 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStandardized Evaluation of Automatic Methods for Perivascular Spaces Segmentation in MRI -- MICCAI 2024 Challenge Results
Dec 20, 2025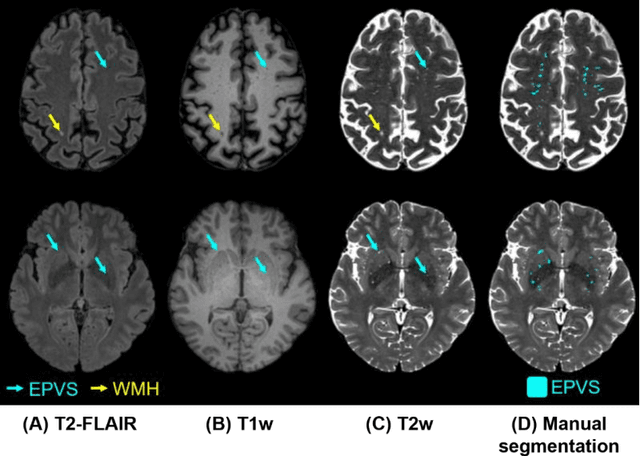
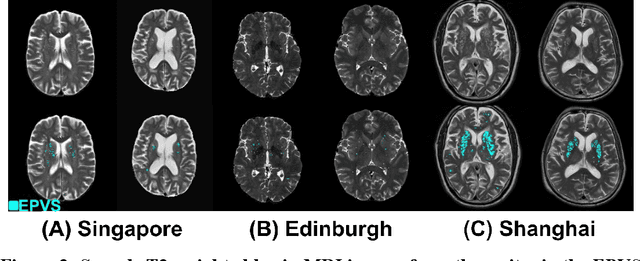
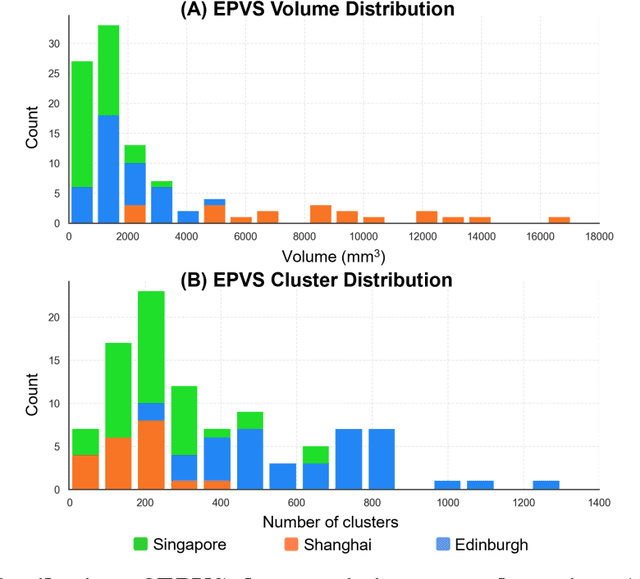
Perivascular spaces (PVS), when abnormally enlarged and visible in magnetic resonance imaging (MRI) structural sequences, are important imaging markers of cerebral small vessel disease and potential indicators of neurodegenerative conditions. Despite their clinical significance, automatic enlarged PVS (EPVS) segmentation remains challenging due to their small size, variable morphology, similarity with other pathological features, and limited annotated datasets. This paper presents the EPVS Challenge organized at MICCAI 2024, which aims to advance the development of automated algorithms for EPVS segmentation across multi-site data. We provided a diverse dataset comprising 100 training, 50 validation, and 50 testing scans collected from multiple international sites (UK, Singapore, and China) with varying MRI protocols and demographics. All annotations followed the STRIVE protocol to ensure standardized ground truth and covered the full brain parenchyma. Seven teams completed the full challenge, implementing various deep learning approaches primarily based on U-Net architectures with innovations in multi-modal processing, ensemble strategies, and transformer-based components. Performance was evaluated using dice similarity coefficient, absolute volume difference, recall, and precision metrics. The winning method employed MedNeXt architecture with a dual 2D/3D strategy for handling varying slice thicknesses. The top solutions showed relatively good performance on test data from seen datasets, but significant degradation of performance was observed on the previously unseen Shanghai cohort, highlighting cross-site generalization challenges due to domain shift. This challenge establishes an important benchmark for EPVS segmentation methods and underscores the need for the continued development of robust algorithms that can generalize in diverse clinical settings.
Learning Brain Tumor Representation in 3D High-Resolution MR Images via Interpretable State Space Models
Sep 12, 2024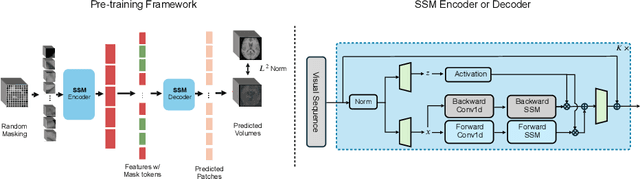


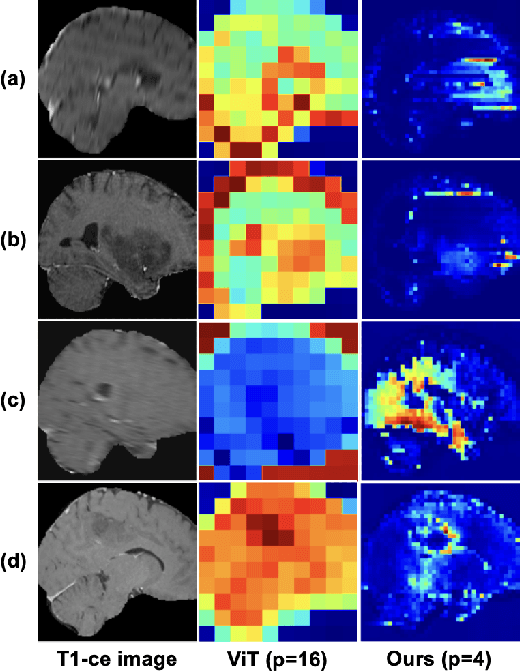
Learning meaningful and interpretable representations from high-dimensional volumetric magnetic resonance (MR) images is essential for advancing personalized medicine. While Vision Transformers (ViTs) have shown promise in handling image data, their application to 3D multi-contrast MR images faces challenges due to computational complexity and interpretability. To address this, we propose a novel state-space-model (SSM)-based masked autoencoder which scales ViT-like models to handle high-resolution data effectively while also enhancing the interpretability of learned representations. We propose a latent-to-spatial mapping technique that enables direct visualization of how latent features correspond to specific regions in the input volumes in the context of SSM. We validate our method on two key neuro-oncology tasks: identification of isocitrate dehydrogenase mutation status and 1p/19q co-deletion classification, achieving state-of-the-art accuracy. Our results highlight the potential of SSM-based self-supervised learning to transform radiomics analysis by combining efficiency and interpretability.