 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStandardized Evaluation of Automatic Methods for Perivascular Spaces Segmentation in MRI -- MICCAI 2024 Challenge Results
Dec 20, 2025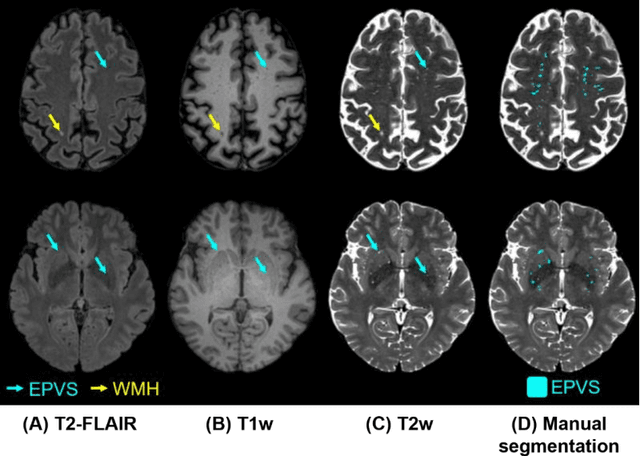
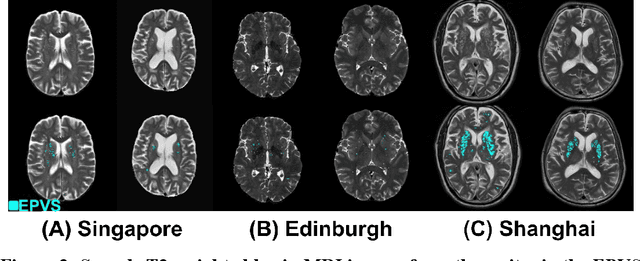
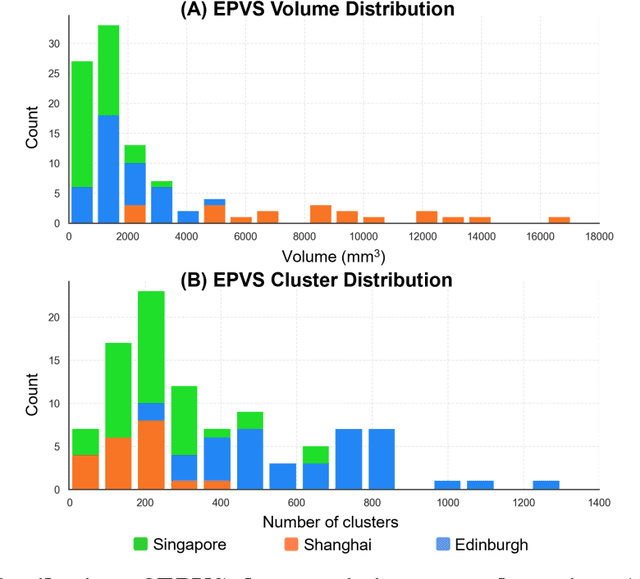
Perivascular spaces (PVS), when abnormally enlarged and visible in magnetic resonance imaging (MRI) structural sequences, are important imaging markers of cerebral small vessel disease and potential indicators of neurodegenerative conditions. Despite their clinical significance, automatic enlarged PVS (EPVS) segmentation remains challenging due to their small size, variable morphology, similarity with other pathological features, and limited annotated datasets. This paper presents the EPVS Challenge organized at MICCAI 2024, which aims to advance the development of automated algorithms for EPVS segmentation across multi-site data. We provided a diverse dataset comprising 100 training, 50 validation, and 50 testing scans collected from multiple international sites (UK, Singapore, and China) with varying MRI protocols and demographics. All annotations followed the STRIVE protocol to ensure standardized ground truth and covered the full brain parenchyma. Seven teams completed the full challenge, implementing various deep learning approaches primarily based on U-Net architectures with innovations in multi-modal processing, ensemble strategies, and transformer-based components. Performance was evaluated using dice similarity coefficient, absolute volume difference, recall, and precision metrics. The winning method employed MedNeXt architecture with a dual 2D/3D strategy for handling varying slice thicknesses. The top solutions showed relatively good performance on test data from seen datasets, but significant degradation of performance was observed on the previously unseen Shanghai cohort, highlighting cross-site generalization challenges due to domain shift. This challenge establishes an important benchmark for EPVS segmentation methods and underscores the need for the continued development of robust algorithms that can generalize in diverse clinical settings.
MoGA: 3D Generative Avatar Prior for Monocular Gaussian Avatar Reconstruction
Jul 31, 2025We present MoGA, a novel method to reconstruct high-fidelity 3D Gaussian avatars from a single-view image. The main challenge lies in inferring unseen appearance and geometric details while ensuring 3D consistency and realism. Most previous methods rely on 2D diffusion models to synthesize unseen views; however, these generated views are sparse and inconsistent, resulting in unrealistic 3D artifacts and blurred appearance. To address these limitations, we leverage a generative avatar model, that can generate diverse 3D avatars by sampling deformed Gaussians from a learned prior distribution. Due to the limited amount of 3D training data such a 3D model alone cannot capture all image details of unseen identities. Consequently, we integrate it as a prior, ensuring 3D consistency by projecting input images into its latent space and enforcing additional 3D appearance and geometric constraints. Our novel approach formulates Gaussian avatar creation as a model inversion process by fitting the generative avatar to synthetic views from 2D diffusion models. The generative avatar provides a meaningful initialization for model fitting, enforces 3D regularization, and helps in refining pose estimation. Experiments show that our method surpasses state-of-the-art techniques and generalizes well to real-world scenarios. Our Gaussian avatars are also inherently animatable
Brain-JEPA: Brain Dynamics Foundation Model with Gradient Positioning and Spatiotemporal Masking
Sep 28, 2024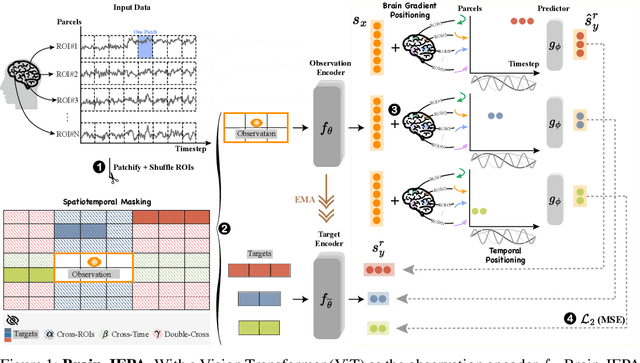
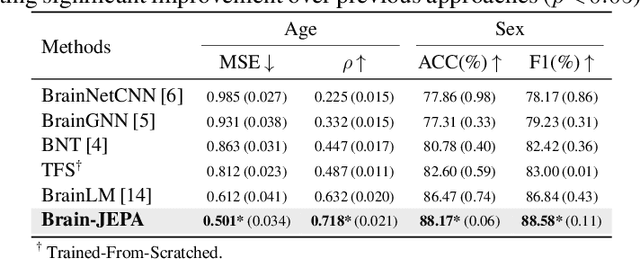
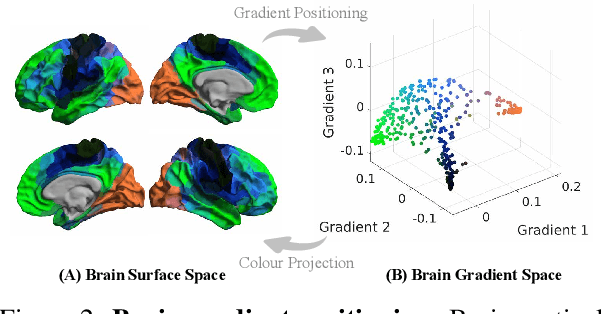
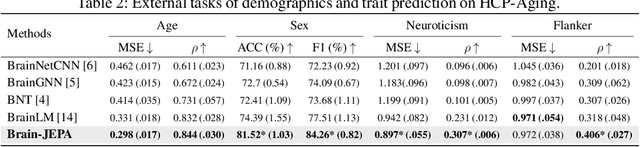
We introduce Brain-JEPA, a brain dynamics foundation model with the Joint-Embedding Predictive Architecture (JEPA). This pioneering model achieves state-of-the-art performance in demographic prediction, disease diagnosis/prognosis, and trait prediction through fine-tuning. Furthermore, it excels in off-the-shelf evaluations (e.g., linear probing) and demonstrates superior generalizability across different ethnic groups, surpassing the previous large model for brain activity significantly. Brain-JEPA incorporates two innovative techniques: Brain Gradient Positioning and Spatiotemporal Masking. Brain Gradient Positioning introduces a functional coordinate system for brain functional parcellation, enhancing the positional encoding of different Regions of Interest (ROIs). Spatiotemporal Masking, tailored to the unique characteristics of fMRI data, addresses the challenge of heterogeneous time-series patches. These methodologies enhance model performance and advance our understanding of the neural circuits underlying cognition. Overall, Brain-JEPA is paving the way to address pivotal questions of building brain functional coordinate system and masking brain activity at the AI-neuroscience interface, and setting a potentially new paradigm in brain activity analysis through downstream adaptation.
Prompt Your Brain: Scaffold Prompt Tuning for Efficient Adaptation of fMRI Pre-trained Model
Aug 20, 2024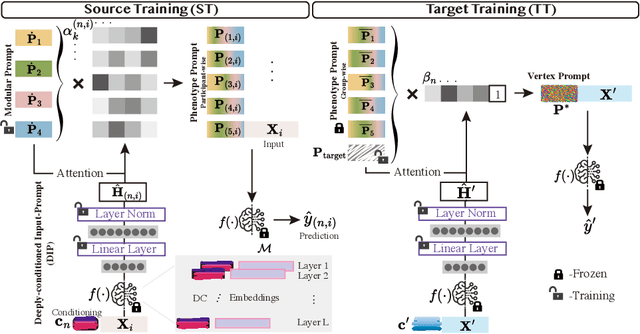
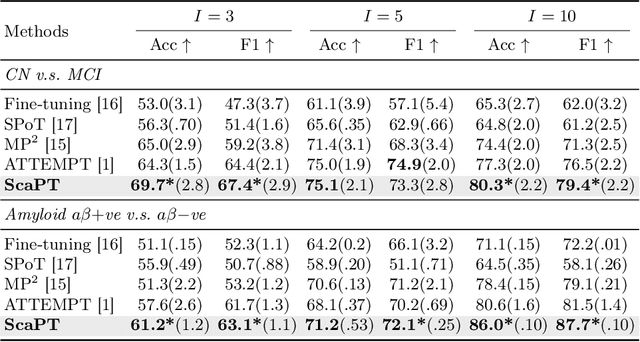
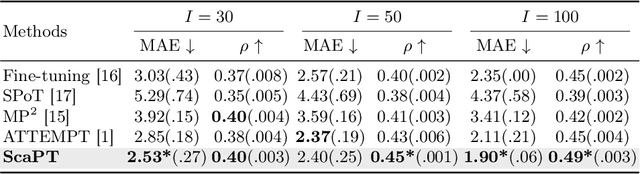
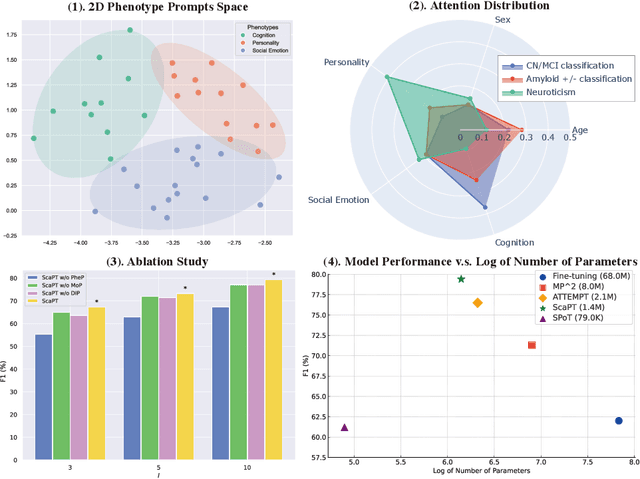
We introduce Scaffold Prompt Tuning (ScaPT), a novel prompt-based framework for adapting large-scale functional magnetic resonance imaging (fMRI) pre-trained models to downstream tasks, with high parameter efficiency and improved performance compared to fine-tuning and baselines for prompt tuning. The full fine-tuning updates all pre-trained parameters, which may distort the learned feature space and lead to overfitting with limited training data which is common in fMRI fields. In contrast, we design a hierarchical prompt structure that transfers the knowledge learned from high-resource tasks to low-resource ones. This structure, equipped with a Deeply-conditioned Input-Prompt (DIP) mapping module, allows for efficient adaptation by updating only 2% of the trainable parameters. The framework enhances semantic interpretability through attention mechanisms between inputs and prompts, and it clusters prompts in the latent space in alignment with prior knowledge. Experiments on public resting state fMRI datasets reveal ScaPT outperforms fine-tuning and multitask-based prompt tuning in neurodegenerative diseases diagnosis/prognosis and personality trait prediction, even with fewer than 20 participants. It highlights ScaPT's efficiency in adapting pre-trained fMRI models to low-resource tasks.
AvatarPose: Avatar-guided 3D Pose Estimation of Close Human Interaction from Sparse Multi-view Videos
Aug 04, 2024



Despite progress in human motion capture, existing multi-view methods often face challenges in estimating the 3D pose and shape of multiple closely interacting people. This difficulty arises from reliance on accurate 2D joint estimations, which are hard to obtain due to occlusions and body contact when people are in close interaction. To address this, we propose a novel method leveraging the personalized implicit neural avatar of each individual as a prior, which significantly improves the robustness and precision of this challenging pose estimation task. Concretely, the avatars are efficiently reconstructed via layered volume rendering from sparse multi-view videos. The reconstructed avatar prior allows for the direct optimization of 3D poses based on color and silhouette rendering loss, bypassing the issues associated with noisy 2D detections. To handle interpenetration, we propose a collision loss on the overlapping shape regions of avatars to add penetration constraints. Moreover, both 3D poses and avatars are optimized in an alternating manner. Our experimental results demonstrate state-of-the-art performance on several public datasets.
Mixup Your Own Pairs
Sep 29, 2023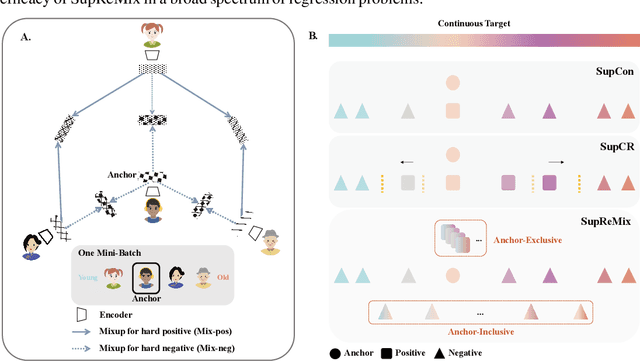
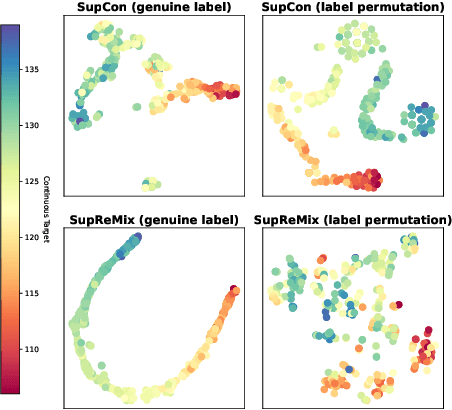
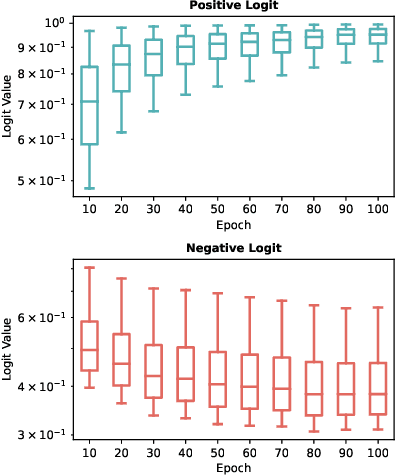
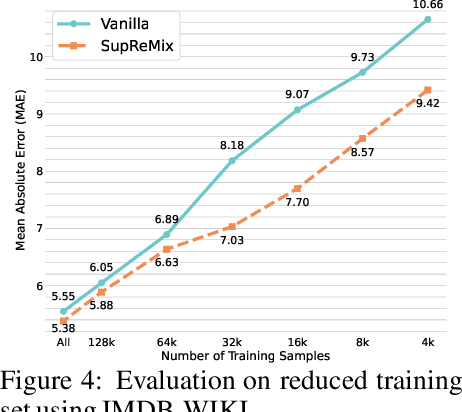
In representation learning, regression has traditionally received less attention than classification. Directly applying representation learning techniques designed for classification to regression often results in fragmented representations in the latent space, yielding sub-optimal performance. In this paper, we argue that the potential of contrastive learning for regression has been overshadowed due to the neglect of two crucial aspects: ordinality-awareness and hardness. To address these challenges, we advocate "mixup your own contrastive pairs for supervised contrastive regression", instead of relying solely on real/augmented samples. Specifically, we propose Supervised Contrastive Learning for Regression with Mixup (SupReMix). It takes anchor-inclusive mixtures (mixup of the anchor and a distinct negative sample) as hard negative pairs and anchor-exclusive mixtures (mixup of two distinct negative samples) as hard positive pairs at the embedding level. This strategy formulates harder contrastive pairs by integrating richer ordinal information. Through extensive experiments on six regression datasets including 2D images, volumetric images, text, tabular data, and time-series signals, coupled with theoretical analysis, we demonstrate that SupReMix pre-training fosters continuous ordered representations of regression data, resulting in significant improvement in regression performance. Furthermore, SupReMix is superior to other approaches in a range of regression challenges including transfer learning, imbalanced training data, and scenarios with fewer training samples.
Beyond the Snapshot: Brain Tokenized Graph Transformer for Longitudinal Brain Functional Connectome Embedding
Jul 13, 2023

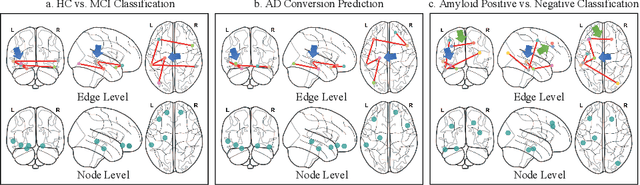
Under the framework of network-based neurodegeneration, brain functional connectome (FC)-based Graph Neural Networks (GNN) have emerged as a valuable tool for the diagnosis and prognosis of neurodegenerative diseases such as Alzheimer's disease (AD). However, these models are tailored for brain FC at a single time point instead of characterizing FC trajectory. Discerning how FC evolves with disease progression, particularly at the predementia stages such as cognitively normal individuals with amyloid deposition or individuals with mild cognitive impairment (MCI), is crucial for delineating disease spreading patterns and developing effective strategies to slow down or even halt disease advancement. In this work, we proposed the first interpretable framework for brain FC trajectory embedding with application to neurodegenerative disease diagnosis and prognosis, namely Brain Tokenized Graph Transformer (Brain TokenGT). It consists of two modules: 1) Graph Invariant and Variant Embedding (GIVE) for generation of node and spatio-temporal edge embeddings, which were tokenized for downstream processing; 2) Brain Informed Graph Transformer Readout (BIGTR) which augments previous tokens with trainable type identifiers and non-trainable node identifiers and feeds them into a standard transformer encoder to readout. We conducted extensive experiments on two public longitudinal fMRI datasets of the AD continuum for three tasks, including differentiating MCI from controls, predicting dementia conversion in MCI, and classification of amyloid positive or negative cognitively normal individuals. Based on brain FC trajectory, the proposed Brain TokenGT approach outperformed all the other benchmark models and at the same time provided excellent interpretability. The code is available at https://github.com/ZijianD/Brain-TokenGT.git
AG3D: Learning to Generate 3D Avatars from 2D Image Collections
May 03, 2023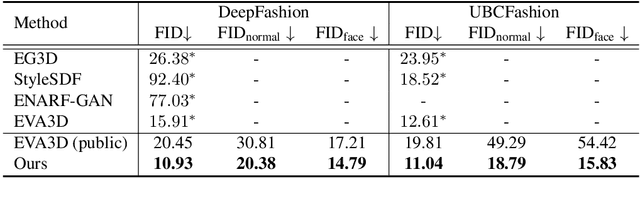
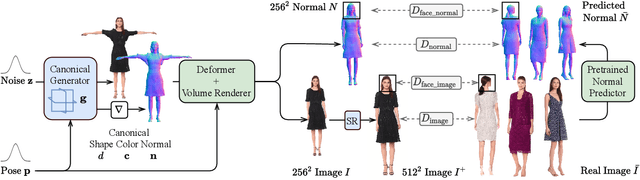
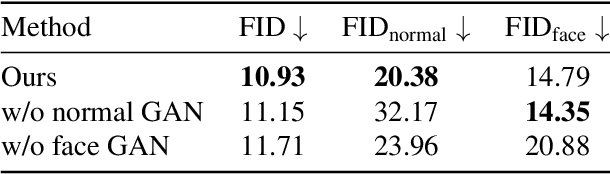

While progress in 2D generative models of human appearance has been rapid, many applications require 3D avatars that can be animated and rendered. Unfortunately, most existing methods for learning generative models of 3D humans with diverse shape and appearance require 3D training data, which is limited and expensive to acquire. The key to progress is hence to learn generative models of 3D avatars from abundant unstructured 2D image collections. However, learning realistic and complete 3D appearance and geometry in this under-constrained setting remains challenging, especially in the presence of loose clothing such as dresses. In this paper, we propose a new adversarial generative model of realistic 3D people from 2D images. Our method captures shape and deformation of the body and loose clothing by adopting a holistic 3D generator and integrating an efficient and flexible articulation module. To improve realism, we train our model using multiple discriminators while also integrating geometric cues in the form of predicted 2D normal maps. We experimentally find that our method outperforms previous 3D- and articulation-aware methods in terms of geometry and appearance. We validate the effectiveness of our model and the importance of each component via systematic ablation studies.
PINA: Learning a Personalized Implicit Neural Avatar from a Single RGB-D Video Sequence
Apr 08, 2022
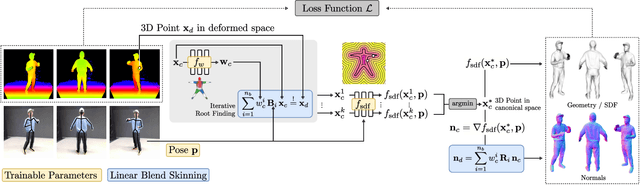
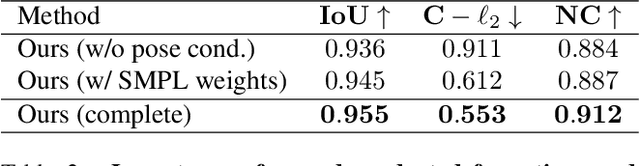
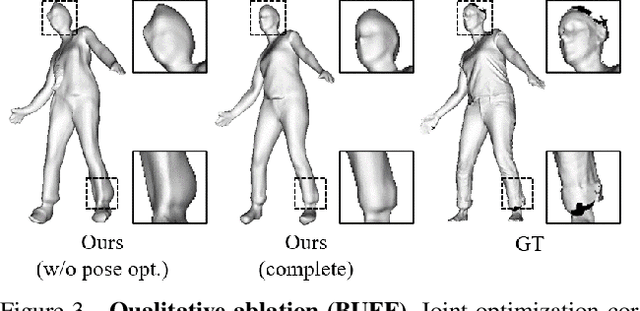
We present a novel method to learn Personalized Implicit Neural Avatars (PINA) from a short RGB-D sequence. This allows non-expert users to create a detailed and personalized virtual copy of themselves, which can be animated with realistic clothing deformations. PINA does not require complete scans, nor does it require a prior learned from large datasets of clothed humans. Learning a complete avatar in this setting is challenging, since only few depth observations are available, which are noisy and incomplete (i.e. only partial visibility of the body per frame). We propose a method to learn the shape and non-rigid deformations via a pose-conditioned implicit surface and a deformation field, defined in canonical space. This allows us to fuse all partial observations into a single consistent canonical representation. Fusion is formulated as a global optimization problem over the pose, shape and skinning parameters. The method can learn neural avatars from real noisy RGB-D sequences for a diverse set of people and clothing styles and these avatars can be animated given unseen motion sequences.
Shape-aware Multi-Person Pose Estimation from Multi-View Images
Oct 05, 2021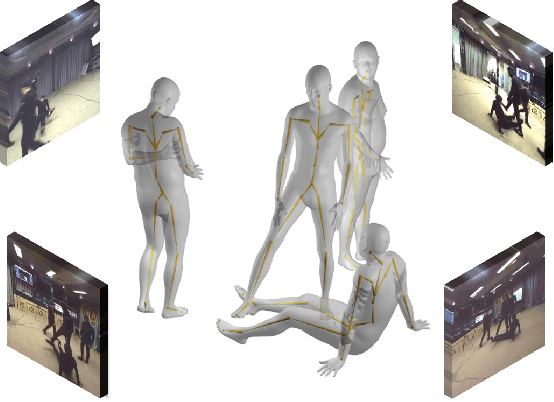
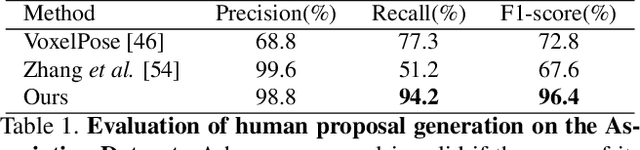
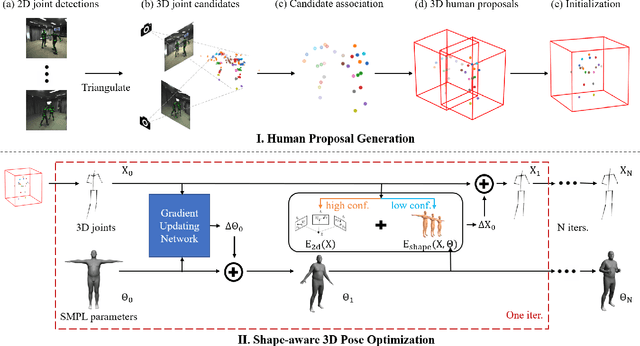

In this paper we contribute a simple yet effective approach for estimating 3D poses of multiple people from multi-view images. Our proposed coarse-to-fine pipeline first aggregates noisy 2D observations from multiple camera views into 3D space and then associates them into individual instances based on a confidence-aware majority voting technique. The final pose estimates are attained from a novel optimization scheme which links high-confidence multi-view 2D observations and 3D joint candidates. Moreover, a statistical parametric body model such as SMPL is leveraged as a regularizing prior for these 3D joint candidates. Specifically, both 3D poses and SMPL parameters are optimized jointly in an alternating fashion. Here the parametric models help in correcting implausible 3D pose estimates and filling in missing joint detections while updated 3D poses in turn guide obtaining better SMPL estimations. By linking 2D and 3D observations, our method is both accurate and generalizes to different data sources because it better decouples the final 3D pose from the inter-person constellation and is more robust to noisy 2D detections. We systematically evaluate our method on public datasets and achieve state-of-the-art performance. The code and video will be available on the project page: https://ait.ethz.ch/projects/2021/multi-human-pose/.