 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePINA: Learning a Personalized Implicit Neural Avatar from a Single RGB-D Video Sequence
Paper and Code

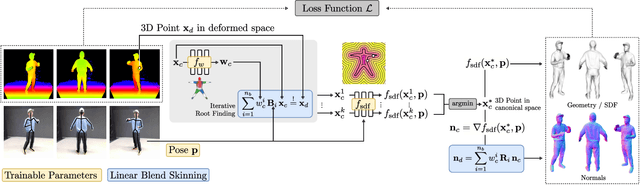
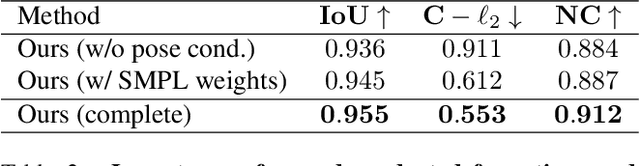
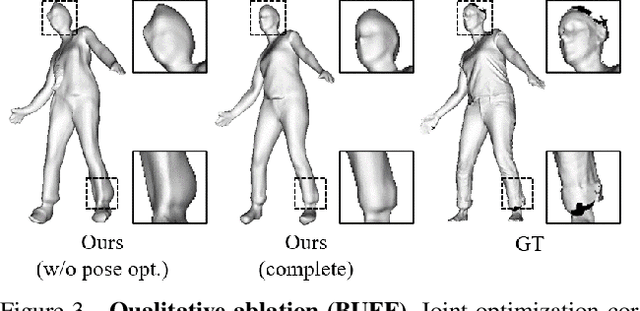
We present a novel method to learn Personalized Implicit Neural Avatars (PINA) from a short RGB-D sequence. This allows non-expert users to create a detailed and personalized virtual copy of themselves, which can be animated with realistic clothing deformations. PINA does not require complete scans, nor does it require a prior learned from large datasets of clothed humans. Learning a complete avatar in this setting is challenging, since only few depth observations are available, which are noisy and incomplete (i.e. only partial visibility of the body per frame). We propose a method to learn the shape and non-rigid deformations via a pose-conditioned implicit surface and a deformation field, defined in canonical space. This allows us to fuse all partial observations into a single consistent canonical representation. Fusion is formulated as a global optimization problem over the pose, shape and skinning parameters. The method can learn neural avatars from real noisy RGB-D sequences for a diverse set of people and clothing styles and these avatars can be animated given unseen motion sequences.