 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeed-Forward 3D Scene Modeling: A Problem-Driven Perspective
Apr 15, 2026Reconstructing 3D representations from 2D inputs is a fundamental task in computer vision and graphics, serving as a cornerstone for understanding and interacting with the physical world. While traditional methods achieve high fidelity, they are limited by slow per-scene optimization or category-specific training, which hinders their practical deployment and scalability. Hence, generalizable feed-forward 3D reconstruction has witnessed rapid development in recent years. By learning a model that maps images directly to 3D representations in a single forward pass, these methods enable efficient reconstruction and robust cross-scene generalization. Our survey is motivated by a critical observation: despite the diverse geometric output representations, ranging from implicit fields to explicit primitives, existing feed-forward approaches share similar high-level architectural patterns, such as image feature extraction backbones, multi-view information fusion mechanisms, and geometry-aware design principles. Consequently, we abstract away from these representation differences and instead focus on model design, proposing a novel taxonomy centered on model design strategies that are agnostic to the output format. Our proposed taxonomy organizes the research directions into five key problems that drive recent research development: feature enhancement, geometry awareness, model efficiency, augmentation strategies and temporal-aware models. To support this taxonomy with empirical grounding and standardized evaluation, we further comprehensively review related benchmarks and datasets, and extensively discuss and categorize real-world applications based on feed-forward 3D models. Finally, we outline future directions to address open challenges such as scalability, evaluation standards, and world modeling.
Fail2Drive: Benchmarking Closed-Loop Driving Generalization
Apr 09, 2026Generalization under distribution shift remains a central bottleneck for closed-loop autonomous driving. Although simulators like CARLA enable safe and scalable testing, existing benchmarks rarely measure true generalization: they typically reuse training scenarios at test time. Success can therefore reflect memorization rather than robust driving behavior. We introduce Fail2Drive, the first paired-route benchmark for closed-loop generalization in CARLA, with 200 routes and 17 new scenario classes spanning appearance, layout, behavioral, and robustness shifts. Each shifted route is matched with an in-distribution counterpart, isolating the effect of the shift and turning qualitative failures into quantitative diagnostics. Evaluating multiple state-of-the-art models reveals consistent degradation, with an average success-rate drop of 22.8\%. Our analysis uncovers unexpected failure modes, such as ignoring objects clearly visible in the LiDAR and failing to learn the fundamental concepts of free and occupied space. To accelerate follow-up work, Fail2Drive includes an open-source toolbox for creating new scenarios and validating solvability via a privileged expert policy. Together, these components establish a reproducible foundation for benchmarking and improving closed-loop driving generalization. We open-source all code, data, and tools at https://github.com/autonomousvision/fail2drive .
UniComp: A Unified Evaluation of Large Language Model Compression via Pruning, Quantization and Distillation
Feb 11, 2026Model compression is increasingly essential for deploying large language models (LLMs), yet existing evaluations are limited in method coverage and focus primarily on knowledge-centric benchmarks. Thus, we introduce UniComp, a unified evaluation framework for comparing pruning, quantization, and knowledge distillation. UniComp evaluates compressed models along three dimensions: performance, reliability, and efficiency, using a diverse set of capability- and safety-oriented benchmarks together with a hardware-aware efficiency analysis. Through extensive evaluation of six compression techniques on modern LLMs across more than 40 datasets, we find that (i) compression exhibits a consistent knowledge bias, where knowledge-intensive tasks are relatively preserved while reasoning, multilingual, and instruction-following capabilities degrade substantially; (ii) quantization provides the best overall trade-off between retained performance and efficiency, whereas distillation yields strong runtime acceleration gains at high computational cost; and (iii) task-specific calibration can significantly improve the reasoning ability of pruned models by up to 50%.
EVolSplat4D: Efficient Volume-based Gaussian Splatting for 4D Urban Scene Synthesis
Jan 22, 2026Novel view synthesis (NVS) of static and dynamic urban scenes is essential for autonomous driving simulation, yet existing methods often struggle to balance reconstruction time with quality. While state-of-the-art neural radiance fields and 3D Gaussian Splatting approaches achieve photorealism, they often rely on time-consuming per-scene optimization. Conversely, emerging feed-forward methods frequently adopt per-pixel Gaussian representations, which lead to 3D inconsistencies when aggregating multi-view predictions in complex, dynamic environments. We propose EvolSplat4D, a feed-forward framework that moves beyond existing per-pixel paradigms by unifying volume-based and pixel-based Gaussian prediction across three specialized branches. For close-range static regions, we predict consistent geometry of 3D Gaussians over multiple frames directly from a 3D feature volume, complemented by a semantically-enhanced image-based rendering module for predicting their appearance. For dynamic actors, we utilize object-centric canonical spaces and a motion-adjusted rendering module to aggregate temporal features, ensuring stable 4D reconstruction despite noisy motion priors. Far-Field scenery is handled by an efficient per-pixel Gaussian branch to ensure full-scene coverage. Experimental results on the KITTI-360, KITTI, Waymo, and PandaSet datasets show that EvolSplat4D reconstructs both static and dynamic environments with superior accuracy and consistency, outperforming both per-scene optimization and state-of-the-art feed-forward baselines.
FrankenMotion: Part-level Human Motion Generation and Composition
Jan 15, 2026Human motion generation from text prompts has made remarkable progress in recent years. However, existing methods primarily rely on either sequence-level or action-level descriptions due to the absence of fine-grained, part-level motion annotations. This limits their controllability over individual body parts. In this work, we construct a high-quality motion dataset with atomic, temporally-aware part-level text annotations, leveraging the reasoning capabilities of large language models (LLMs). Unlike prior datasets that either provide synchronized part captions with fixed time segments or rely solely on global sequence labels, our dataset captures asynchronous and semantically distinct part movements at fine temporal resolution. Based on this dataset, we introduce a diffusion-based part-aware motion generation framework, namely FrankenMotion, where each body part is guided by its own temporally-structured textual prompt. This is, to our knowledge, the first work to provide atomic, temporally-aware part-level motion annotations and have a model that allows motion generation with both spatial (body part) and temporal (atomic action) control. Experiments demonstrate that FrankenMotion outperforms all previous baseline models adapted and retrained for our setting, and our model can compose motions unseen during training. Our code and dataset will be publicly available upon publication.
LEAD: Minimizing Learner-Expert Asymmetry in End-to-End Driving
Dec 23, 2025Simulators can generate virtually unlimited driving data, yet imitation learning policies in simulation still struggle to achieve robust closed-loop performance. Motivated by this gap, we empirically study how misalignment between privileged expert demonstrations and sensor-based student observations can limit the effectiveness of imitation learning. More precisely, experts have significantly higher visibility (e.g., ignoring occlusions) and far lower uncertainty (e.g., knowing other vehicles' actions), making them difficult to imitate reliably. Furthermore, navigational intent (i.e., the route to follow) is under-specified in student models at test time via only a single target point. We demonstrate that these asymmetries can measurably limit driving performance in CARLA and offer practical interventions to address them. After careful modifications to narrow the gaps between expert and student, our TransFuser v6 (TFv6) student policy achieves a new state of the art on all major publicly available CARLA closed-loop benchmarks, reaching 95 DS on Bench2Drive and more than doubling prior performances on Longest6~v2 and Town13. Additionally, by integrating perception supervision from our dataset into a shared sim-to-real pipeline, we show consistent gains on the NAVSIM and Waymo Vision-Based End-to-End driving benchmarks. Our code, data, and models are publicly available at https://github.com/autonomousvision/lead.
SpaceDrive: Infusing Spatial Awareness into VLM-based Autonomous Driving
Dec 11, 2025End-to-end autonomous driving methods built on vision language models (VLMs) have undergone rapid development driven by their universal visual understanding and strong reasoning capabilities obtained from the large-scale pretraining. However, we find that current VLMs struggle to understand fine-grained 3D spatial relationships which is a fundamental requirement for systems interacting with the physical world. To address this issue, we propose SpaceDrive, a spatial-aware VLM-based driving framework that treats spatial information as explicit positional encodings (PEs) instead of textual digit tokens, enabling joint reasoning over semantic and spatial representations. SpaceDrive employs a universal positional encoder to all 3D coordinates derived from multi-view depth estimation, historical ego-states, and text prompts. These 3D PEs are first superimposed to augment the corresponding 2D visual tokens. Meanwhile, they serve as a task-agnostic coordinate representation, replacing the digit-wise numerical tokens as both inputs and outputs for the VLM. This mechanism enables the model to better index specific visual semantics in spatial reasoning and directly regress trajectory coordinates rather than generating digit-by-digit, thereby enhancing planning accuracy. Extensive experiments validate that SpaceDrive achieves state-of-the-art open-loop performance on the nuScenes dataset and the second-best Driving Score of 78.02 on the Bench2Drive closed-loop benchmark over existing VLM-based methods.
PlanT 2.0: Exposing Biases and Structural Flaws in Closed-Loop Driving
Nov 10, 2025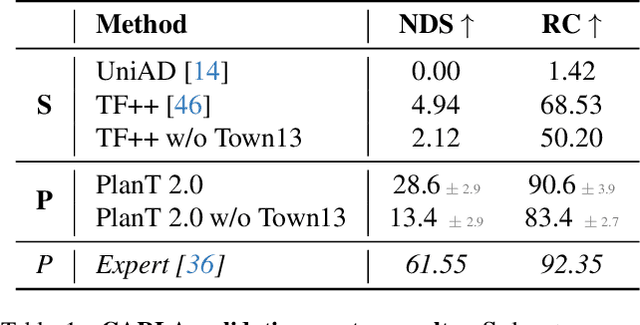



Most recent work in autonomous driving has prioritized benchmark performance and methodological innovation over in-depth analysis of model failures, biases, and shortcut learning. This has led to incremental improvements without a deep understanding of the current failures. While it is straightforward to look at situations where the model fails, it is hard to understand the underlying reason. This motivates us to conduct a systematic study, where inputs to the model are perturbed and the predictions observed. We introduce PlanT 2.0, a lightweight, object-centric planning transformer designed for autonomous driving research in CARLA. The object-level representation enables controlled analysis, as the input can be easily perturbed (e.g., by changing the location or adding or removing certain objects), in contrast to sensor-based models. To tackle the scenarios newly introduced by the challenging CARLA Leaderboard 2.0, we introduce multiple upgrades to PlanT, achieving state-of-the-art performance on Longest6 v2, Bench2Drive, and the CARLA validation routes. Our analysis exposes insightful failures, such as a lack of scene understanding caused by low obstacle diversity, rigid expert behaviors leading to exploitable shortcuts, and overfitting to a fixed set of expert trajectories. Based on these findings, we argue for a shift toward data-centric development, with a focus on richer, more robust, and less biased datasets. We open-source our code and model at https://github.com/autonomousvision/plant2.
ConeGS: Error-Guided Densification Using Pixel Cones for Improved Reconstruction with Fewer Primitives
Nov 10, 2025



3D Gaussian Splatting (3DGS) achieves state-of-the-art image quality and real-time performance in novel view synthesis but often suffers from a suboptimal spatial distribution of primitives. This issue stems from cloning-based densification, which propagates Gaussians along existing geometry, limiting exploration and requiring many primitives to adequately cover the scene. We present ConeGS, an image-space-informed densification framework that is independent of existing scene geometry state. ConeGS first creates a fast Instant Neural Graphics Primitives (iNGP) reconstruction as a geometric proxy to estimate per-pixel depth. During the subsequent 3DGS optimization, it identifies high-error pixels and inserts new Gaussians along the corresponding viewing cones at the predicted depth values, initializing their size according to the cone diameter. A pre-activation opacity penalty rapidly removes redundant Gaussians, while a primitive budgeting strategy controls the total number of primitives, either by a fixed budget or by adapting to scene complexity, ensuring high reconstruction quality. Experiments show that ConeGS consistently enhances reconstruction quality and rendering performance across Gaussian budgets, with especially strong gains under tight primitive constraints where efficient placement is crucial.
ReSplat: Learning Recurrent Gaussian Splats
Oct 09, 2025While feed-forward Gaussian splatting models provide computational efficiency and effectively handle sparse input settings, their performance is fundamentally limited by the reliance on a single forward pass during inference. We propose ReSplat, a feed-forward recurrent Gaussian splatting model that iteratively refines 3D Gaussians without explicitly computing gradients. Our key insight is that the Gaussian splatting rendering error serves as a rich feedback signal, guiding the recurrent network to learn effective Gaussian updates. This feedback signal naturally adapts to unseen data distributions at test time, enabling robust generalization. To initialize the recurrent process, we introduce a compact reconstruction model that operates in a $16 \times$ subsampled space, producing $16 \times$ fewer Gaussians than previous per-pixel Gaussian models. This substantially reduces computational overhead and allows for efficient Gaussian updates. Extensive experiments across varying of input views (2, 8, 16), resolutions ($256 \times 256$ to $540 \times 960$), and datasets (DL3DV and RealEstate10K) demonstrate that our method achieves state-of-the-art performance while significantly reducing the number of Gaussians and improving the rendering speed. Our project page is at https://haofeixu.github.io/resplat/.