 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFreeFix: Boosting 3D Gaussian Splatting via Fine-Tuning-Free Diffusion Models
Jan 28, 2026Neural Radiance Fields and 3D Gaussian Splatting have advanced novel view synthesis, yet still rely on dense inputs and often degrade at extrapolated views. Recent approaches leverage generative models, such as diffusion models, to provide additional supervision, but face a trade-off between generalization and fidelity: fine-tuning diffusion models for artifact removal improves fidelity but risks overfitting, while fine-tuning-free methods preserve generalization but often yield lower fidelity. We introduce FreeFix, a fine-tuning-free approach that pushes the boundary of this trade-off by enhancing extrapolated rendering with pretrained image diffusion models. We present an interleaved 2D-3D refinement strategy, showing that image diffusion models can be leveraged for consistent refinement without relying on costly video diffusion models. Furthermore, we take a closer look at the guidance signal for 2D refinement and propose a per-pixel confidence mask to identify uncertain regions for targeted improvement. Experiments across multiple datasets show that FreeFix improves multi-frame consistency and achieves performance comparable to or surpassing fine-tuning-based methods, while retaining strong generalization ability.
EVolSplat4D: Efficient Volume-based Gaussian Splatting for 4D Urban Scene Synthesis
Jan 22, 2026Novel view synthesis (NVS) of static and dynamic urban scenes is essential for autonomous driving simulation, yet existing methods often struggle to balance reconstruction time with quality. While state-of-the-art neural radiance fields and 3D Gaussian Splatting approaches achieve photorealism, they often rely on time-consuming per-scene optimization. Conversely, emerging feed-forward methods frequently adopt per-pixel Gaussian representations, which lead to 3D inconsistencies when aggregating multi-view predictions in complex, dynamic environments. We propose EvolSplat4D, a feed-forward framework that moves beyond existing per-pixel paradigms by unifying volume-based and pixel-based Gaussian prediction across three specialized branches. For close-range static regions, we predict consistent geometry of 3D Gaussians over multiple frames directly from a 3D feature volume, complemented by a semantically-enhanced image-based rendering module for predicting their appearance. For dynamic actors, we utilize object-centric canonical spaces and a motion-adjusted rendering module to aggregate temporal features, ensuring stable 4D reconstruction despite noisy motion priors. Far-Field scenery is handled by an efficient per-pixel Gaussian branch to ensure full-scene coverage. Experimental results on the KITTI-360, KITTI, Waymo, and PandaSet datasets show that EvolSplat4D reconstructs both static and dynamic environments with superior accuracy and consistency, outperforming both per-scene optimization and state-of-the-art feed-forward baselines.
ScenDi: 3D-to-2D Scene Diffusion Cascades for Urban Generation
Jan 21, 2026Recent advancements in 3D object generation using diffusion models have achieved remarkable success, but generating realistic 3D urban scenes remains challenging. Existing methods relying solely on 3D diffusion models tend to suffer a degradation in appearance details, while those utilizing only 2D diffusion models typically compromise camera controllability. To overcome this limitation, we propose ScenDi, a method for urban scene generation that integrates both 3D and 2D diffusion models. We first train a 3D latent diffusion model to generate 3D Gaussians, enabling the rendering of images at a relatively low resolution. To enable controllable synthesis, this 3DGS generation process can be optionally conditioned by specifying inputs such as 3d bounding boxes, road maps, or text prompts. Then, we train a 2D video diffusion model to enhance appearance details conditioned on rendered images from the 3D Gaussians. By leveraging the coarse 3D scene as guidance for 2D video diffusion, ScenDi generates desired scenes based on input conditions and successfully adheres to accurate camera trajectories. Experiments on two challenging real-world datasets, Waymo and KITTI-360, demonstrate the effectiveness of our approach.
Towards Depth Foundation Model: Recent Trends in Vision-Based Depth Estimation
Jul 15, 2025Depth estimation is a fundamental task in 3D computer vision, crucial for applications such as 3D reconstruction, free-viewpoint rendering, robotics, autonomous driving, and AR/VR technologies. Traditional methods relying on hardware sensors like LiDAR are often limited by high costs, low resolution, and environmental sensitivity, limiting their applicability in real-world scenarios. Recent advances in vision-based methods offer a promising alternative, yet they face challenges in generalization and stability due to either the low-capacity model architectures or the reliance on domain-specific and small-scale datasets. The emergence of scaling laws and foundation models in other domains has inspired the development of "depth foundation models": deep neural networks trained on large datasets with strong zero-shot generalization capabilities. This paper surveys the evolution of deep learning architectures and paradigms for depth estimation across the monocular, stereo, multi-view, and monocular video settings. We explore the potential of these models to address existing challenges and provide a comprehensive overview of large-scale datasets that can facilitate their development. By identifying key architectures and training strategies, we aim to highlight the path towards robust depth foundation models, offering insights into their future research and applications.
Vivid4D: Improving 4D Reconstruction from Monocular Video by Video Inpainting
Apr 15, 2025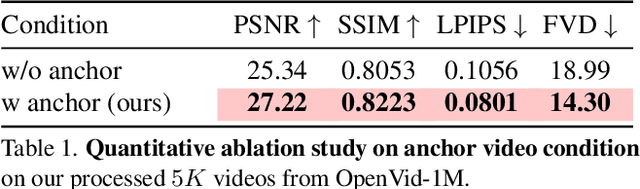



Reconstructing 4D dynamic scenes from casually captured monocular videos is valuable but highly challenging, as each timestamp is observed from a single viewpoint. We introduce Vivid4D, a novel approach that enhances 4D monocular video synthesis by augmenting observation views - synthesizing multi-view videos from a monocular input. Unlike existing methods that either solely leverage geometric priors for supervision or use generative priors while overlooking geometry, we integrate both. This reformulates view augmentation as a video inpainting task, where observed views are warped into new viewpoints based on monocular depth priors. To achieve this, we train a video inpainting model on unposed web videos with synthetically generated masks that mimic warping occlusions, ensuring spatially and temporally consistent completion of missing regions. To further mitigate inaccuracies in monocular depth priors, we introduce an iterative view augmentation strategy and a robust reconstruction loss. Experiments demonstrate that our method effectively improves monocular 4D scene reconstruction and completion.
EVolSplat: Efficient Volume-based Gaussian Splatting for Urban View Synthesis
Mar 26, 2025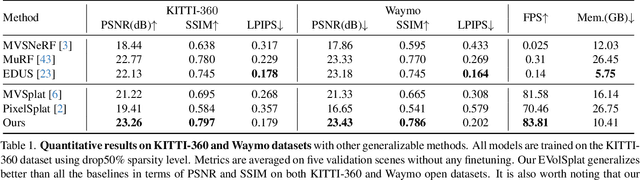
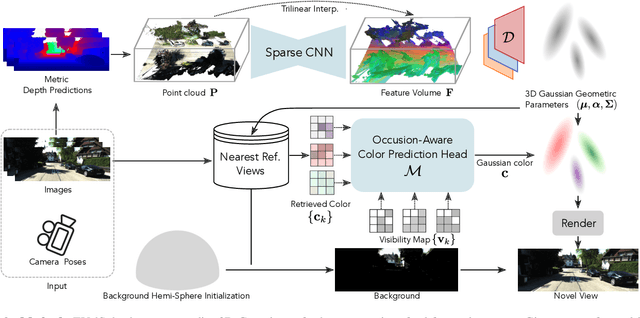
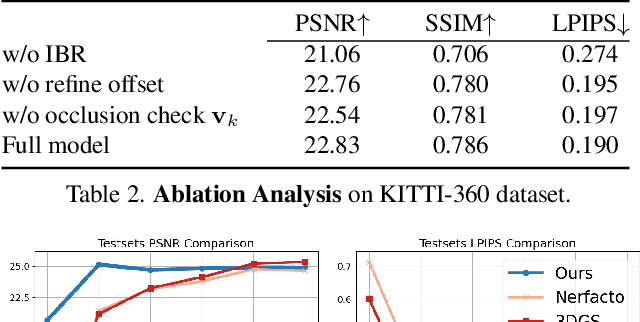
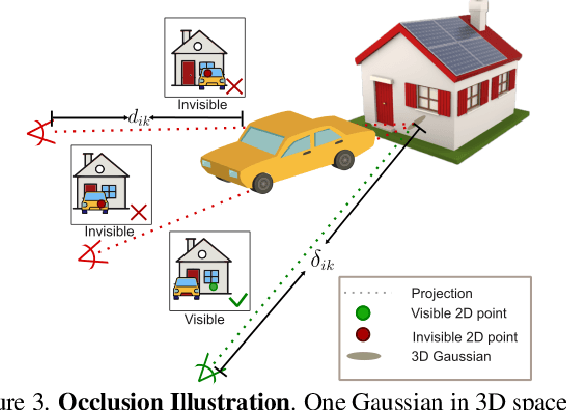
Novel view synthesis of urban scenes is essential for autonomous driving-related applications.Existing NeRF and 3DGS-based methods show promising results in achieving photorealistic renderings but require slow, per-scene optimization. We introduce EVolSplat, an efficient 3D Gaussian Splatting model for urban scenes that works in a feed-forward manner. Unlike existing feed-forward, pixel-aligned 3DGS methods, which often suffer from issues like multi-view inconsistencies and duplicated content, our approach predicts 3D Gaussians across multiple frames within a unified volume using a 3D convolutional network. This is achieved by initializing 3D Gaussians with noisy depth predictions, and then refining their geometric properties in 3D space and predicting color based on 2D textures. Our model also handles distant views and the sky with a flexible hemisphere background model. This enables us to perform fast, feed-forward reconstruction while achieving real-time rendering. Experimental evaluations on the KITTI-360 and Waymo datasets show that our method achieves state-of-the-art quality compared to existing feed-forward 3DGS- and NeRF-based methods.
Efficient Depth-Guided Urban View Synthesis
Jul 17, 2024



Recent advances in implicit scene representation enable high-fidelity street view novel view synthesis. However, existing methods optimize a neural radiance field for each scene, relying heavily on dense training images and extensive computation resources. To mitigate this shortcoming, we introduce a new method called Efficient Depth-Guided Urban View Synthesis (EDUS) for fast feed-forward inference and efficient per-scene fine-tuning. Different from prior generalizable methods that infer geometry based on feature matching, EDUS leverages noisy predicted geometric priors as guidance to enable generalizable urban view synthesis from sparse input images. The geometric priors allow us to apply our generalizable model directly in the 3D space, gaining robustness across various sparsity levels. Through comprehensive experiments on the KITTI-360 and Waymo datasets, we demonstrate promising generalization abilities on novel street scenes. Moreover, our results indicate that EDUS achieves state-of-the-art performance in sparse view settings when combined with fast test-time optimization.