 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStereo World Model: Camera-Guided Stereo Video Generation
Mar 18, 2026We present StereoWorld, a camera-conditioned stereo world model that jointly learns appearance and binocular geometry for end-to-end stereo video generation.Unlike monocular RGB or RGBD approaches, StereoWorld operates exclusively within the RGB modality, while simultaneously grounding geometry directly from disparity. To efficiently achieve consistent stereo generation, our approach introduces two key designs: (1) a unified camera-frame RoPE that augments latent tokens with camera-aware rotary positional encoding, enabling relative, view- and time-consistent conditioning while preserving pretrained video priors via a stable attention initialization; and (2) a stereo-aware attention decomposition that factors full 4D attention into 3D intra-view attention plus horizontal row attention, leveraging the epipolar prior to capture disparity-aligned correspondences with substantially lower compute. Across benchmarks, StereoWorld improves stereo consistency, disparity accuracy, and camera-motion fidelity over strong monocular-then-convert pipelines, achieving more than 3x faster generation with an additional 5% gain in viewpoint consistency. Beyond benchmarks, StereoWorld enables end-to-end binocular VR rendering without depth estimation or inpainting, enhances embodied policy learning through metric-scale depth grounding, and is compatible with long-video distillation for extended interactive stereo synthesis.
Gen3R: 3D Scene Generation Meets Feed-Forward Reconstruction
Jan 07, 2026We present Gen3R, a method that bridges the strong priors of foundational reconstruction models and video diffusion models for scene-level 3D generation. We repurpose the VGGT reconstruction model to produce geometric latents by training an adapter on its tokens, which are regularized to align with the appearance latents of pre-trained video diffusion models. By jointly generating these disentangled yet aligned latents, Gen3R produces both RGB videos and corresponding 3D geometry, including camera poses, depth maps, and global point clouds. Experiments demonstrate that our approach achieves state-of-the-art results in single- and multi-image conditioned 3D scene generation. Additionally, our method can enhance the robustness of reconstruction by leveraging generative priors, demonstrating the mutual benefit of tightly coupling reconstruction and generative models.
ImmerseGen: Agent-Guided Immersive World Generation with Alpha-Textured Proxies
Jun 18, 2025Automatic creation of 3D scenes for immersive VR presence has been a significant research focus for decades. However, existing methods often rely on either high-poly mesh modeling with post-hoc simplification or massive 3D Gaussians, resulting in a complex pipeline or limited visual realism. In this paper, we demonstrate that such exhaustive modeling is unnecessary for achieving compelling immersive experience. We introduce ImmerseGen, a novel agent-guided framework for compact and photorealistic world modeling. ImmerseGen represents scenes as hierarchical compositions of lightweight geometric proxies, i.e., simplified terrain and billboard meshes, and generates photorealistic appearance by synthesizing RGBA textures onto these proxies. Specifically, we propose terrain-conditioned texturing for user-centric base world synthesis, and RGBA asset texturing for midground and foreground scenery. This reformulation offers several advantages: (i) it simplifies modeling by enabling agents to guide generative models in producing coherent textures that integrate seamlessly with the scene; (ii) it bypasses complex geometry creation and decimation by directly synthesizing photorealistic textures on proxies, preserving visual quality without degradation; (iii) it enables compact representations suitable for real-time rendering on mobile VR headsets. To automate scene creation from text prompts, we introduce VLM-based modeling agents enhanced with semantic grid-based analysis for improved spatial reasoning and accurate asset placement. ImmerseGen further enriches scenes with dynamic effects and ambient audio to support multisensory immersion. Experiments on scene generation and live VR showcases demonstrate that ImmerseGen achieves superior photorealism, spatial coherence and rendering efficiency compared to prior methods. Project webpage: https://immersegen.github.io.
EX-4D: EXtreme Viewpoint 4D Video Synthesis via Depth Watertight Mesh
Jun 05, 2025
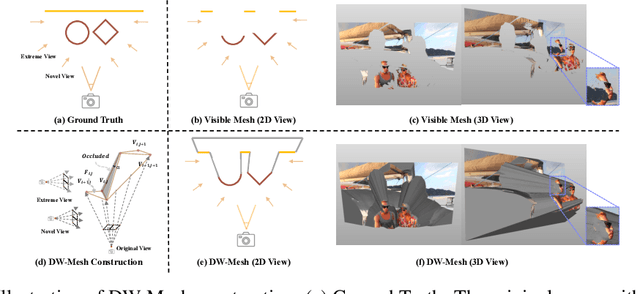


Generating high-quality camera-controllable videos from monocular input is a challenging task, particularly under extreme viewpoint. Existing methods often struggle with geometric inconsistencies and occlusion artifacts in boundaries, leading to degraded visual quality. In this paper, we introduce EX-4D, a novel framework that addresses these challenges through a Depth Watertight Mesh representation. The representation serves as a robust geometric prior by explicitly modeling both visible and occluded regions, ensuring geometric consistency in extreme camera pose. To overcome the lack of paired multi-view datasets, we propose a simulated masking strategy that generates effective training data only from monocular videos. Additionally, a lightweight LoRA-based video diffusion adapter is employed to synthesize high-quality, physically consistent, and temporally coherent videos. Extensive experiments demonstrate that EX-4D outperforms state-of-the-art methods in terms of physical consistency and extreme-view quality, enabling practical 4D video generation.
HiScene: Creating Hierarchical 3D Scenes with Isometric View Generation
Apr 17, 2025Scene-level 3D generation represents a critical frontier in multimedia and computer graphics, yet existing approaches either suffer from limited object categories or lack editing flexibility for interactive applications. In this paper, we present HiScene, a novel hierarchical framework that bridges the gap between 2D image generation and 3D object generation and delivers high-fidelity scenes with compositional identities and aesthetic scene content. Our key insight is treating scenes as hierarchical "objects" under isometric views, where a room functions as a complex object that can be further decomposed into manipulatable items. This hierarchical approach enables us to generate 3D content that aligns with 2D representations while maintaining compositional structure. To ensure completeness and spatial alignment of each decomposed instance, we develop a video-diffusion-based amodal completion technique that effectively handles occlusions and shadows between objects, and introduce shape prior injection to ensure spatial coherence within the scene. Experimental results demonstrate that our method produces more natural object arrangements and complete object instances suitable for interactive applications, while maintaining physical plausibility and alignment with user inputs.
Vivid4D: Improving 4D Reconstruction from Monocular Video by Video Inpainting
Apr 15, 2025



Reconstructing 4D dynamic scenes from casually captured monocular videos is valuable but highly challenging, as each timestamp is observed from a single viewpoint. We introduce Vivid4D, a novel approach that enhances 4D monocular video synthesis by augmenting observation views - synthesizing multi-view videos from a monocular input. Unlike existing methods that either solely leverage geometric priors for supervision or use generative priors while overlooking geometry, we integrate both. This reformulates view augmentation as a video inpainting task, where observed views are warped into new viewpoints based on monocular depth priors. To achieve this, we train a video inpainting model on unposed web videos with synthetically generated masks that mimic warping occlusions, ensuring spatially and temporally consistent completion of missing regions. To further mitigate inaccuracies in monocular depth priors, we introduce an iterative view augmentation strategy and a robust reconstruction loss. Experiments demonstrate that our method effectively improves monocular 4D scene reconstruction and completion.
TexPro: Text-guided PBR Texturing with Procedural Material Modeling
Oct 21, 2024
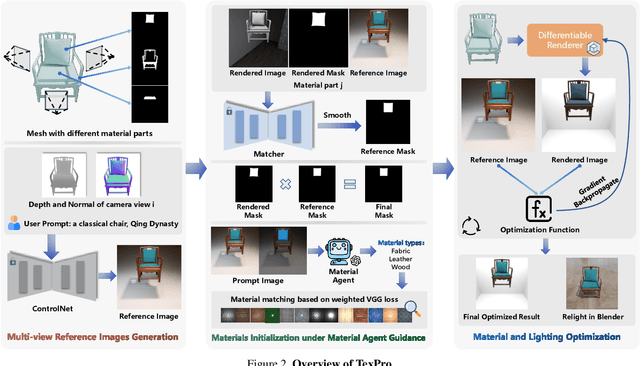
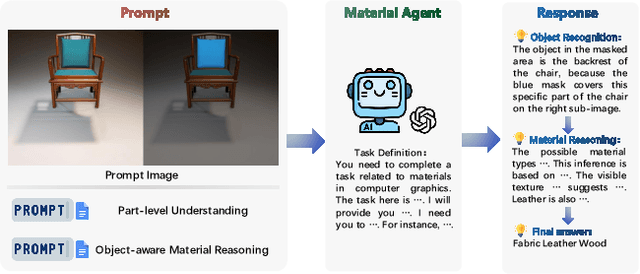
In this paper, we present TexPro, a novel method for high-fidelity material generation for input 3D meshes given text prompts. Unlike existing text-conditioned texture generation methods that typically generate RGB textures with baked lighting, TexPro is able to produce diverse texture maps via procedural material modeling, which enables physical-based rendering, relighting, and additional benefits inherent to procedural materials. Specifically, we first generate multi-view reference images given the input textual prompt by employing the latest text-to-image model. We then derive texture maps through a rendering-based optimization with recent differentiable procedural materials. To this end, we design several techniques to handle the misalignment between the generated multi-view images and 3D meshes, and introduce a novel material agent that enhances material classification and matching by exploring both part-level understanding and object-aware material reasoning. Experiments demonstrate the superiority of the proposed method over existing SOTAs and its capability of relighting.
Coin3D: Controllable and Interactive 3D Assets Generation with Proxy-Guided Conditioning
May 13, 2024As humans, we aspire to create media content that is both freely willed and readily controlled. Thanks to the prominent development of generative techniques, we now can easily utilize 2D diffusion methods to synthesize images controlled by raw sketch or designated human poses, and even progressively edit/regenerate local regions with masked inpainting. However, similar workflows in 3D modeling tasks are still unavailable due to the lack of controllability and efficiency in 3D generation. In this paper, we present a novel controllable and interactive 3D assets modeling framework, named Coin3D. Coin3D allows users to control the 3D generation using a coarse geometry proxy assembled from basic shapes, and introduces an interactive generation workflow to support seamless local part editing while delivering responsive 3D object previewing within a few seconds. To this end, we develop several techniques, including the 3D adapter that applies volumetric coarse shape control to the diffusion model, proxy-bounded editing strategy for precise part editing, progressive volume cache to support responsive preview, and volume-SDS to ensure consistent mesh reconstruction. Extensive experiments of interactive generation and editing on diverse shape proxies demonstrate that our method achieves superior controllability and flexibility in the 3D assets generation task.
DeferredGS: Decoupled and Editable Gaussian Splatting with Deferred Shading
Apr 15, 2024



Reconstructing and editing 3D objects and scenes both play crucial roles in computer graphics and computer vision. Neural radiance fields (NeRFs) can achieve realistic reconstruction and editing results but suffer from inefficiency in rendering. Gaussian splatting significantly accelerates rendering by rasterizing Gaussian ellipsoids. However, Gaussian splatting utilizes a single Spherical Harmonic (SH) function to model both texture and lighting, limiting independent editing capabilities of these components. Recently, attempts have been made to decouple texture and lighting with the Gaussian splatting representation but may fail to produce plausible geometry and decomposition results on reflective scenes. Additionally, the forward shading technique they employ introduces noticeable blending artifacts during relighting, as the geometry attributes of Gaussians are optimized under the original illumination and may not be suitable for novel lighting conditions. To address these issues, we introduce DeferredGS, a method for decoupling and editing the Gaussian splatting representation using deferred shading. To achieve successful decoupling, we model the illumination with a learnable environment map and define additional attributes such as texture parameters and normal direction on Gaussians, where the normal is distilled from a jointly trained signed distance function. More importantly, we apply deferred shading, resulting in more realistic relighting effects compared to previous methods. Both qualitative and quantitative experiments demonstrate the superior performance of DeferredGS in novel view synthesis and editing tasks.
DreamSpace: Dreaming Your Room Space with Text-Driven Panoramic Texture Propagation
Oct 19, 2023



Diffusion-based methods have achieved prominent success in generating 2D media. However, accomplishing similar proficiencies for scene-level mesh texturing in 3D spatial applications, e.g., XR/VR, remains constrained, primarily due to the intricate nature of 3D geometry and the necessity for immersive free-viewpoint rendering. In this paper, we propose a novel indoor scene texturing framework, which delivers text-driven texture generation with enchanting details and authentic spatial coherence. The key insight is to first imagine a stylized 360{\deg} panoramic texture from the central viewpoint of the scene, and then propagate it to the rest areas with inpainting and imitating techniques. To ensure meaningful and aligned textures to the scene, we develop a novel coarse-to-fine panoramic texture generation approach with dual texture alignment, which both considers the geometry and texture cues of the captured scenes. To survive from cluttered geometries during texture propagation, we design a separated strategy, which conducts texture inpainting in confidential regions and then learns an implicit imitating network to synthesize textures in occluded and tiny structural areas. Extensive experiments and the immersive VR application on real-world indoor scenes demonstrate the high quality of the generated textures and the engaging experience on VR headsets. Project webpage: https://ybbbbt.com/publication/dreamspace