 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHitem3D 2.0: Multi-View Guided Native 3D Texture Generation
Apr 10, 2026Although recent advances have improved the quality of 3D texture generation, existing methods still struggle with incomplete texture coverage, cross-view inconsistency, and misalignment between geometry and texture. To address these limitations, we propose Hitem3D 2.0, a multi-view guided native 3D texture generation framework that enhances texture quality through the integration of 2D multi-view generation priors and native 3D texture representations. Hitem3D 2.0 comprises two key components: a multi-view synthesis framework and a native 3D texture generation model. The multi-view generation is built upon a pre-trained image editing backbone and incorporates plug-and-play modules that explicitly promote geometric alignment, cross-view consistency, and illumination uniformity, thereby enabling the synthesis of high-fidelity multi-view images. Conditioned on the generated views and 3D geometry, the native 3D texture generation model projects multi-view textures onto 3D surfaces while plausibly completing textures in unseen regions. Through the integration of multi-view consistency constraints with native 3D texture modeling, Hitem3D 2.0 significantly improves texture completeness, cross-view coherence, and geometric alignment. Experimental results demonstrate that Hitem3D 2.0 outperforms existing methods in terms of texture detail, fidelity, consistency, coherence, and alignment.
Know3D: Prompting 3D Generation with Knowledge from Vision-Language Models
Mar 24, 2026Recent advances in 3D generation have improved the fidelity and geometric details of synthesized 3D assets. However, due to the inherent ambiguity of single-view observations and the lack of robust global structural priors caused by limited 3D training data, the unseen regions generated by existing models are often stochastic and difficult to control, which may sometimes fail to align with user intentions or produce implausible geometries. In this paper, we propose Know3D, a novel framework that incorporates rich knowledge from multimodal large language models into 3D generative processes via latent hidden-state injection, enabling language-controllable generation of the back-view for 3D assets. We utilize a VLM-diffusion-based model, where the VLM is responsible for semantic understanding and guidance. The diffusion model acts as a bridge that transfers semantic knowledge from the VLM to the 3D generation model. In this way, we successfully bridge the gap between abstract textual instructions and the geometric reconstruction of unobserved regions, transforming the traditionally stochastic back-view hallucination into a semantically controllable process, demonstrating a promising direction for future 3D generation models.
EI-Part: Explode for Completion and Implode for Refinement
Mar 14, 2026Part-level 3D generation is crucial for various downstream applications, including gaming, film production, and industrial design. However, decomposing a 3D shape into geometrically plausible and meaningful components remains a significant challenge. Previous part-based generation methods often struggle to produce well-constructed parts, exhibiting poor structural coherence, geometric implausibility, inaccuracy, or inefficiency. To address these challenges, we introduce EI-Part, a novel framework specifically designed to generate high-quality 3D shapes with components, characterized by strong structural coherence, geometric plausibility, geometric fidelity, and generation efficiency. We propose utilizing distinct representations at different stages: an Explode state for part completion and an Implode state for geometry refinement. This strategy fully leverages spatial resolution, enabling flexible part completion and fine geometric detail generation. To maintain structural coherence between parts, a self-attention mechanism is incorporated in both exploded and imploded states, facilitating effective information perception and feature fusion among components during generation. Extensive experiments on multiple benchmarks demonstrate that EI-Part efficiently produces semantically meaningful and structurally coherent parts with fine-grained geometric details, achieving state-of-the-art performance in part-level 3D generation. Project page: https://cvhadessun.github.io/EI-Part/
Mesh Silksong: Auto-Regressive Mesh Generation as Weaving Silk
Jul 03, 2025We introduce Mesh Silksong, a compact and efficient mesh representation tailored to generate the polygon mesh in an auto-regressive manner akin to silk weaving. Existing mesh tokenization methods always produce token sequences with repeated vertex tokens, wasting the network capability. Therefore, our approach tokenizes mesh vertices by accessing each mesh vertice only once, reduces the token sequence's redundancy by 50\%, and achieves a state-of-the-art compression rate of approximately 22\%. Furthermore, Mesh Silksong produces polygon meshes with superior geometric properties, including manifold topology, watertight detection, and consistent face normals, which are critical for practical applications. Experimental results demonstrate the effectiveness of our approach, showcasing not only intricate mesh generation but also significantly improved geometric integrity.
Hyper3D: Efficient 3D Representation via Hybrid Triplane and Octree Feature for Enhanced 3D Shape Variational Auto-Encoders
Mar 13, 2025Recent 3D content generation pipelines often leverage Variational Autoencoders (VAEs) to encode shapes into compact latent representations, facilitating diffusion-based generation. Efficiently compressing 3D shapes while preserving intricate geometric details remains a key challenge. Existing 3D shape VAEs often employ uniform point sampling and 1D/2D latent representations, such as vector sets or triplanes, leading to significant geometric detail loss due to inadequate surface coverage and the absence of explicit 3D representations in the latent space. Although recent work explores 3D latent representations, their large scale hinders high-resolution encoding and efficient training. Given these challenges, we introduce Hyper3D, which enhances VAE reconstruction through efficient 3D representation that integrates hybrid triplane and octree features. First, we adopt an octree-based feature representation to embed mesh information into the network, mitigating the limitations of uniform point sampling in capturing geometric distributions along the mesh surface. Furthermore, we propose a hybrid latent space representation that integrates a high-resolution triplane with a low-resolution 3D grid. This design not only compensates for the lack of explicit 3D representations but also leverages a triplane to preserve high-resolution details. Experimental results demonstrate that Hyper3D outperforms traditional representations by reconstructing 3D shapes with higher fidelity and finer details, making it well-suited for 3D generation pipelines.
NeuDA: Neural Deformable Anchor for High-Fidelity Implicit Surface Reconstruction
Mar 04, 2023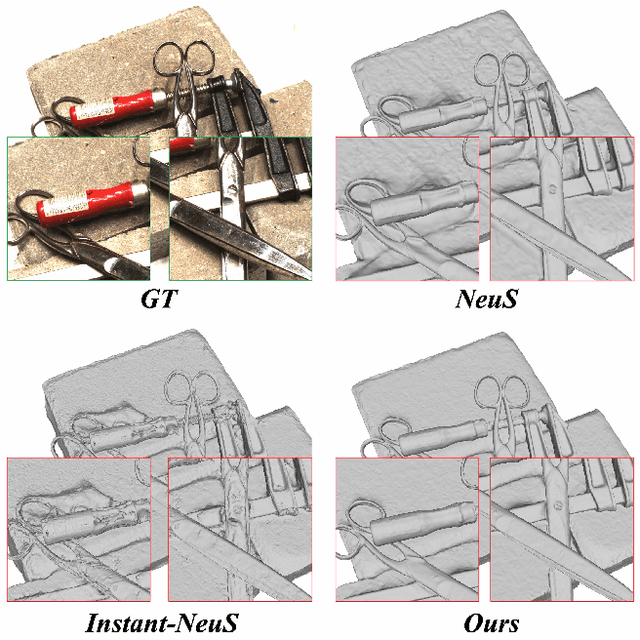



This paper studies implicit surface reconstruction leveraging differentiable ray casting. Previous works such as IDR and NeuS overlook the spatial context in 3D space when predicting and rendering the surface, thereby may fail to capture sharp local topologies such as small holes and structures. To mitigate the limitation, we propose a flexible neural implicit representation leveraging hierarchical voxel grids, namely Neural Deformable Anchor (NeuDA), for high-fidelity surface reconstruction. NeuDA maintains the hierarchical anchor grids where each vertex stores a 3D position (or anchor) instead of the direct embedding (or feature). We optimize the anchor grids such that different local geometry structures can be adaptively encoded. Besides, we dig into the frequency encoding strategies and introduce a simple hierarchical positional encoding method for the hierarchical anchor structure to flexibly exploit the properties of high-frequency and low-frequency geometry and appearance. Experiments on both the DTU and BlendedMVS datasets demonstrate that NeuDA can produce promising mesh surfaces.
3D Scene Creation and Rendering via Rough Meshes: A Lighting Transfer Avenue
Dec 04, 2022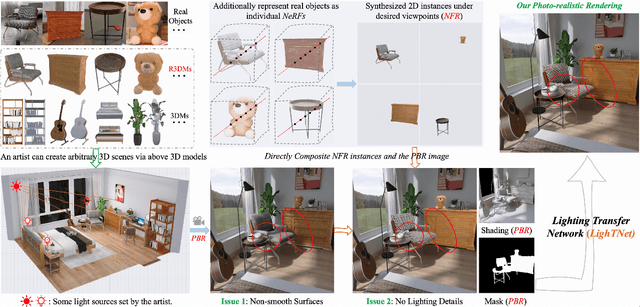



This paper studies how to flexibly integrate reconstructed 3D models into practical 3D modeling pipelines such as 3D scene creation and rendering. Due to the technical difficulty, one can only obtain rough 3D models (R3DMs) for most real objects using existing 3D reconstruction techniques. As a result, physically-based rendering (PBR) would render low-quality images or videos for scenes that are constructed by R3DMs. One promising solution would be representing real-world objects as Neural Fields such as NeRFs, which are able to generate photo-realistic renderings of an object under desired viewpoints. However, a drawback is that the synthesized views through Neural Fields Rendering (NFR) cannot reflect the simulated lighting details on R3DMs in PBR pipelines, especially when object interactions in the 3D scene creation cause local shadows. To solve this dilemma, we propose a lighting transfer network (LighTNet) to bridge NFR and PBR, such that they can benefit from each other. LighTNet reasons about a simplified image composition model, remedies the uneven surface issue caused by R3DMs, and is empowered by several perceptual-motivated constraints and a new Lab angle loss which enhances the contrast between lighting strength and colors. Comparisons demonstrate that LighTNet is superior in synthesizing impressive lighting, and is promising in pushing NFR further in practical 3D modeling workflows. Project page: https://3d-front-future.github.io/LighTNet .
DCCF: Deep Comprehensible Color Filter Learning Framework for High-Resolution Image Harmonization
Jul 13, 2022

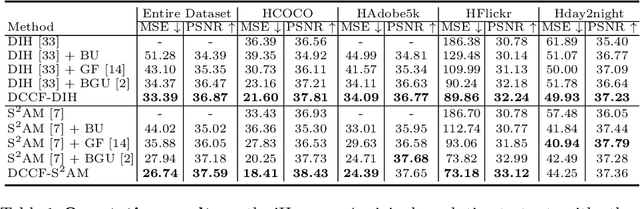
Image color harmonization algorithm aims to automatically match the color distribution of foreground and background images captured in different conditions. Previous deep learning based models neglect two issues that are critical for practical applications, namely high resolution (HR) image processing and model comprehensibility. In this paper, we propose a novel Deep Comprehensible Color Filter (DCCF) learning framework for high-resolution image harmonization. Specifically, DCCF first downsamples the original input image to its low-resolution (LR) counter-part, then learns four human comprehensible neural filters (i.e. hue, saturation, value and attentive rendering filters) in an end-to-end manner, finally applies these filters to the original input image to get the harmonized result. Benefiting from the comprehensible neural filters, we could provide a simple yet efficient handler for users to cooperate with deep model to get the desired results with very little effort when necessary. Extensive experiments demonstrate the effectiveness of DCCF learning framework and it outperforms state-of-the-art post-processing method on iHarmony4 dataset on images' full-resolutions by achieving 7.63% and 1.69% relative improvements on MSE and PSNR respectively.
Ray Priors through Reprojection: Improving Neural Radiance Fields for Novel View Extrapolation
May 12, 2022
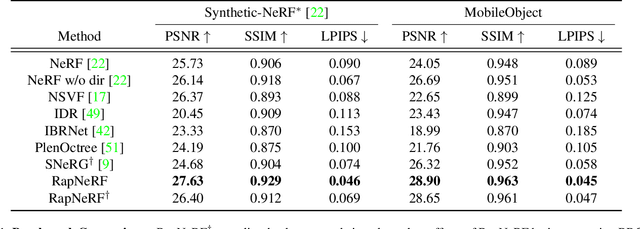
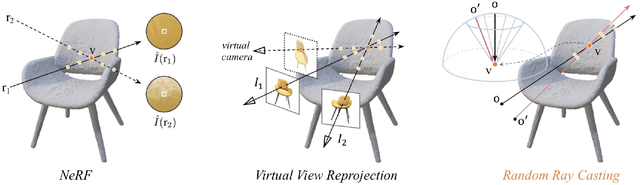
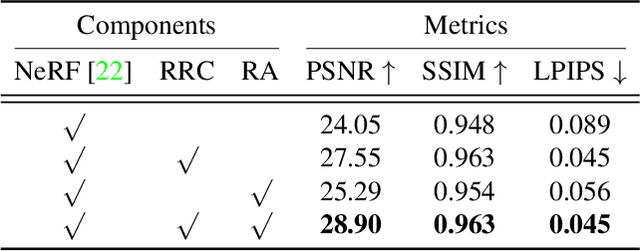
Neural Radiance Fields (NeRF) have emerged as a potent paradigm for representing scenes and synthesizing photo-realistic images. A main limitation of conventional NeRFs is that they often fail to produce high-quality renderings under novel viewpoints that are significantly different from the training viewpoints. In this paper, instead of exploiting few-shot image synthesis, we study the novel view extrapolation setting that (1) the training images can well describe an object, and (2) there is a notable discrepancy between the training and test viewpoints' distributions. We present RapNeRF (RAy Priors) as a solution. Our insight is that the inherent appearances of a 3D surface's arbitrary visible projections should be consistent. We thus propose a random ray casting policy that allows training unseen views using seen views. Furthermore, we show that a ray atlas pre-computed from the observed rays' viewing directions could further enhance the rendering quality for extrapolated views. A main limitation is that RapNeRF would remove the strong view-dependent effects because it leverages the multi-view consistency property.
NeRF-Editing: Geometry Editing of Neural Radiance Fields
May 10, 2022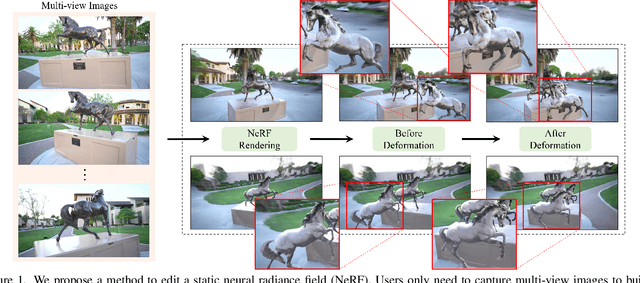

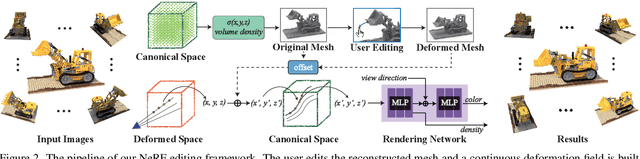

Implicit neural rendering, especially Neural Radiance Field (NeRF), has shown great potential in novel view synthesis of a scene. However, current NeRF-based methods cannot enable users to perform user-controlled shape deformation in the scene. While existing works have proposed some approaches to modify the radiance field according to the user's constraints, the modification is limited to color editing or object translation and rotation. In this paper, we propose a method that allows users to perform controllable shape deformation on the implicit representation of the scene, and synthesizes the novel view images of the edited scene without re-training the network. Specifically, we establish a correspondence between the extracted explicit mesh representation and the implicit neural representation of the target scene. Users can first utilize well-developed mesh-based deformation methods to deform the mesh representation of the scene. Our method then utilizes user edits from the mesh representation to bend the camera rays by introducing a tetrahedra mesh as a proxy, obtaining the rendering results of the edited scene. Extensive experiments demonstrate that our framework can achieve ideal editing results not only on synthetic data, but also on real scenes captured by users.