 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Free Evaluation of User Contributions in Federated Learning
Aug 24, 2021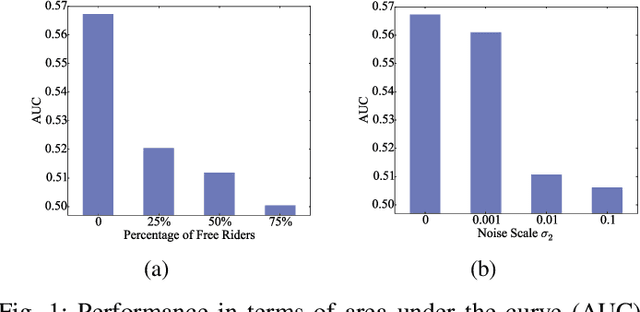
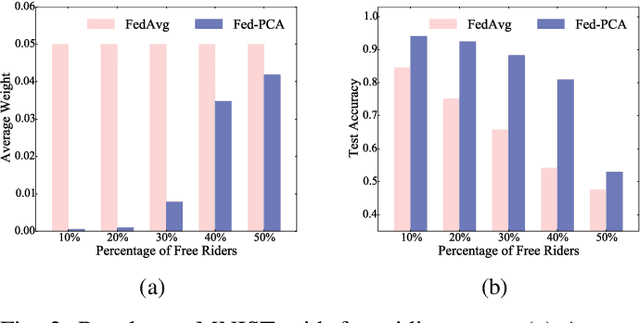
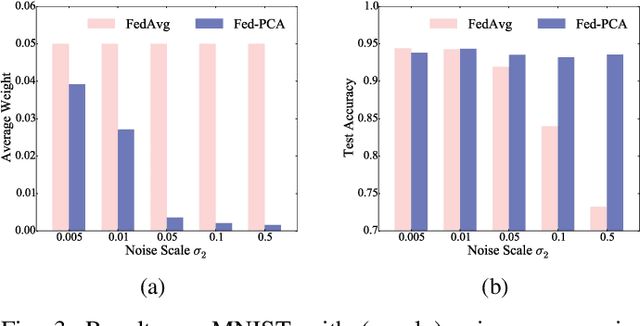
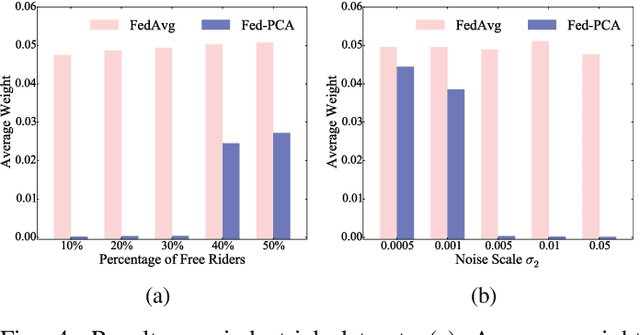
Federated learning (FL) trains a machine learning model on mobile devices in a distributed manner using each device's private data and computing resources. A critical issues is to evaluate individual users' contributions so that (1) users' effort in model training can be compensated with proper incentives and (2) malicious and low-quality users can be detected and removed. The state-of-the-art solutions require a representative test dataset for the evaluation purpose, but such a dataset is often unavailable and hard to synthesize. In this paper, we propose a method called Pairwise Correlated Agreement (PCA) based on the idea of peer prediction to evaluate user contribution in FL without a test dataset. PCA achieves this using the statistical correlation of the model parameters uploaded by users. We then apply PCA to designing (1) a new federated learning algorithm called Fed-PCA, and (2) a new incentive mechanism that guarantees truthfulness. We evaluate the performance of PCA and Fed-PCA using the MNIST dataset and a large industrial product recommendation dataset. The results demonstrate that our Fed-PCA outperforms the canonical FedAvg algorithm and other baseline methods in accuracy, and at the same time, PCA effectively incentivizes users to behave truthfully.
XREF: Entity Linking for Chinese News Comments with Supplementary Article Reference
Jun 24, 2020
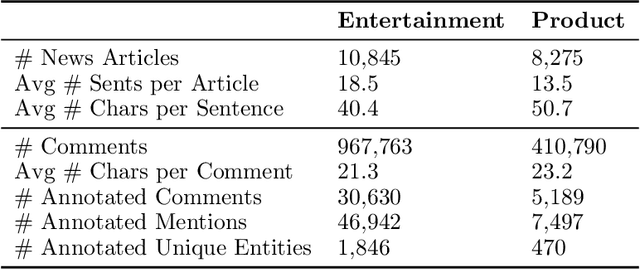
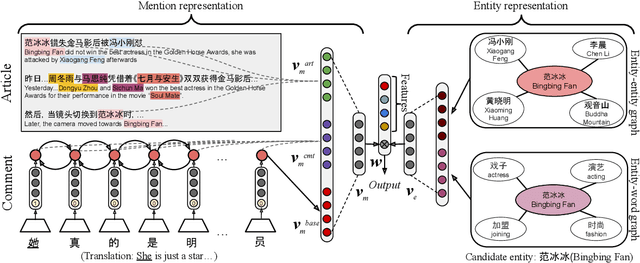

Automatic identification of mentioned entities in social media posts facilitates quick digestion of trending topics and popular opinions. Nonetheless, this remains a challenging task due to limited context and diverse name variations. In this paper, we study the problem of entity linking for Chinese news comments given mentions' spans. We hypothesize that comments often refer to entities in the corresponding news article, as well as topics involving the entities. We therefore propose a novel model, XREF, that leverages attention mechanisms to (1) pinpoint relevant context within comments, and (2) detect supporting entities from the news article. To improve training, we make two contributions: (a) we propose a supervised attention loss in addition to the standard cross entropy, and (b) we develop a weakly supervised training scheme to utilize the large-scale unlabeled corpus. Two new datasets in entertainment and product domains are collected and annotated for experiments. Our proposed method outperforms previous methods on both datasets.
Secure Federated Submodel Learning
Nov 11, 2019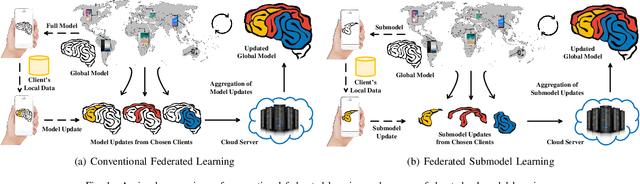
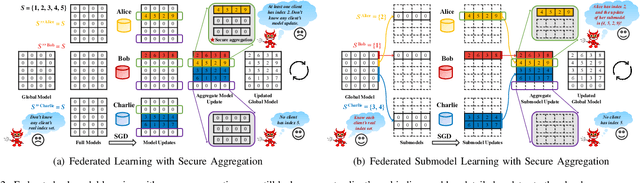
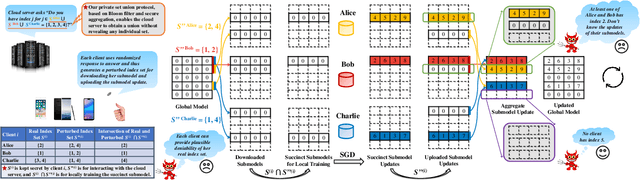
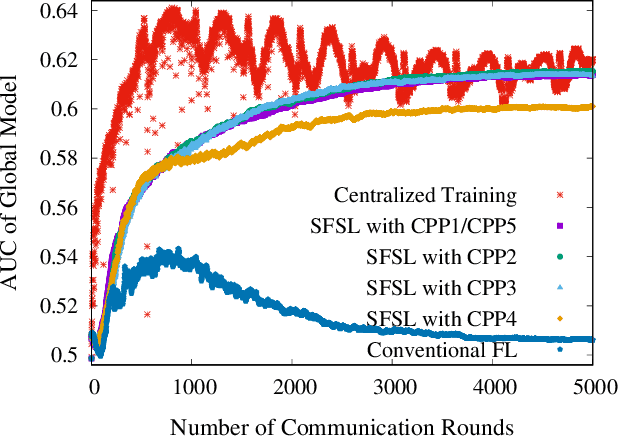
Federated learning was proposed with an intriguing vision of achieving collaborative machine learning among numerous clients without uploading their private data to a cloud server. However, the conventional framework requires each client to leverage the full model for learning, which can be prohibitively inefficient for resource-constrained clients and large-scale deep learning tasks. We thus propose a new framework, called federated submodel learning, where clients download only the needed parts of the full model, namely submodels, and then upload the submodel updates. Nevertheless, the "position" of a client's truly required submodel corresponds to her private data, and its disclosure to the cloud server during interactions inevitably breaks the tenet of federated learning. To integrate efficiency and privacy, we have designed a secure federated submodel learning scheme coupled with a private set union protocol as a cornerstone. Our secure scheme features the properties of randomized response, secure aggregation, and Bloom filter, and endows each client with a customized plausible deniability, in terms of local differential privacy, against the position of her desired submodel, thus protecting her private data. We further instantiated our scheme with the e-commerce recommendation scenario in Alibaba, implemented a prototype system, and extensively evaluated its performance over 30-day Taobao user data. The analysis and evaluation results demonstrate the feasibility and scalability of our scheme from model accuracy and convergency, practical communication, computation, and storage overheads, as well as manifest its remarkable advantages over the conventional federated learning framework.
SAM: Semantic Attribute Modulation for Language Modeling and Style Variation
Sep 14, 2017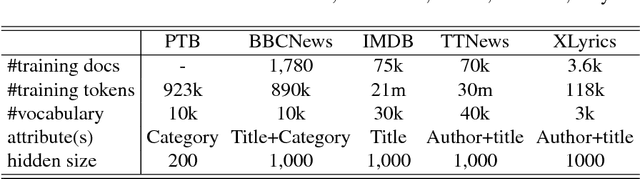
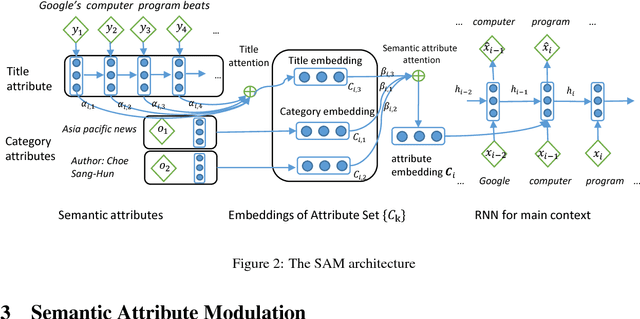

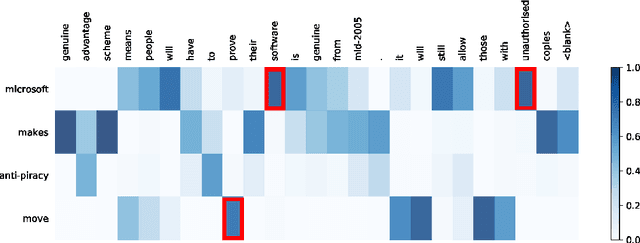
This paper presents a Semantic Attribute Modulation (SAM) for language modeling and style variation. The semantic attribute modulation includes various document attributes, such as titles, authors, and document categories. We consider two types of attributes, (title attributes and category attributes), and a flexible attribute selection scheme by automatically scoring them via an attribute attention mechanism. The semantic attributes are embedded into the hidden semantic space as the generation inputs. With the attributes properly harnessed, our proposed SAM can generate interpretable texts with regard to the input attributes. Qualitative analysis, including word semantic analysis and attention values, shows the interpretability of SAM. On several typical text datasets, we empirically demonstrate the superiority of the Semantic Attribute Modulated language model with different combinations of document attributes. Moreover, we present a style variation for the lyric generation using SAM, which shows a strong connection between the style variation and the semantic attributes.