 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedADP: Unified Model Aggregation for Federated Learning with Heterogeneous Model Architectures
May 10, 2025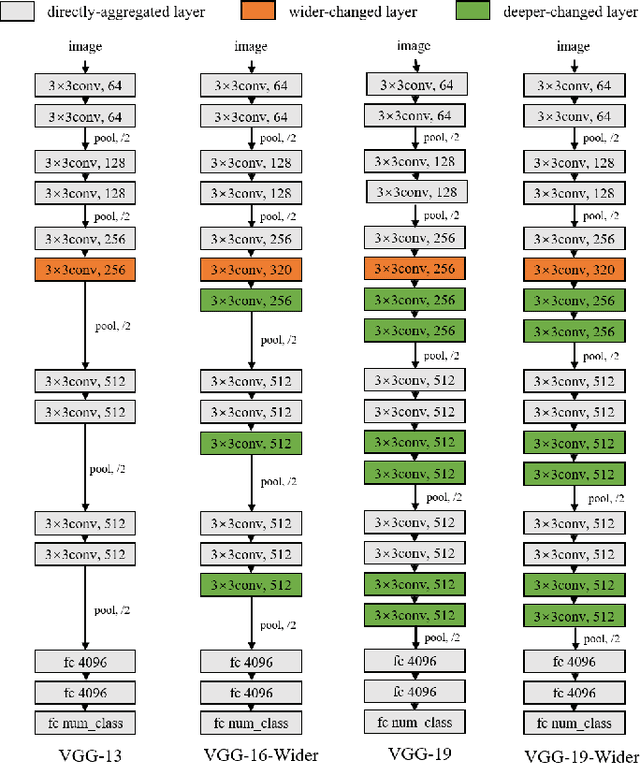
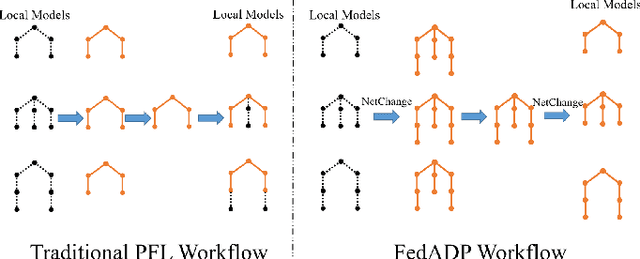
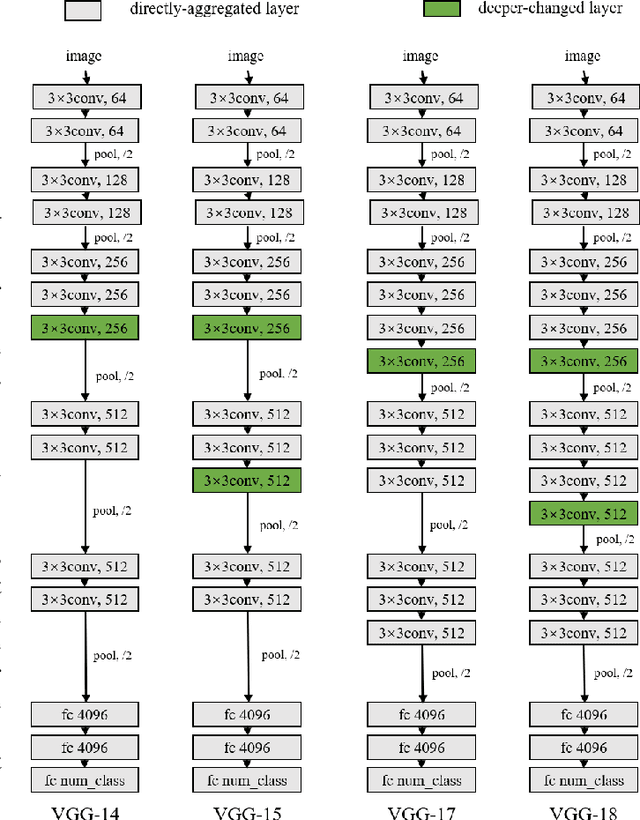
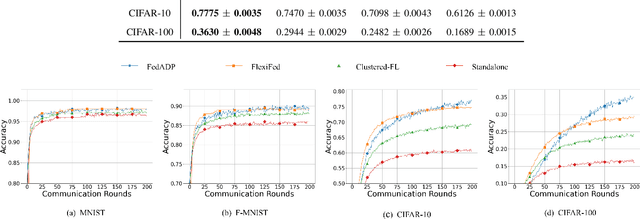
Traditional Federated Learning (FL) faces significant challenges in terms of efficiency and accuracy, particularly in heterogeneous environments where clients employ diverse model architectures and have varying computational resources. Such heterogeneity complicates the aggregation process, leading to performance bottlenecks and reduced model generalizability. To address these issues, we propose FedADP, a federated learning framework designed to adapt to client heterogeneity by dynamically adjusting model architectures during aggregation. FedADP enables effective collaboration among clients with differing capabilities, maximizing resource utilization and ensuring model quality. Our experimental results demonstrate that FedADP significantly outperforms existing methods, such as FlexiFed, achieving an accuracy improvement of up to 23.30%, thereby enhancing model adaptability and training efficiency in heterogeneous real-world settings.
Adaptive incentive for cross-silo federated learning: A multi-agent reinforcement learning approach
Feb 15, 2023


Cross-silo federated learning (FL) is a typical FL that enables organizations(e.g., financial or medical entities) to train global models on isolated data. Reasonable incentive is key to encouraging organizations to contribute data. However, existing works on incentivizing cross-silo FL lack consideration of the environmental dynamics (e.g., precision of the trained global model and data owned by uncertain clients during the training processes). Moreover, most of them assume that organizations share private information, which is unrealistic. To overcome these limitations, we propose a novel adaptive mechanism for cross-silo FL, towards incentivizing organizations to contribute data to maximize their long-term payoffs in a real dynamic training environment. The mechanism is based on multi-agent reinforcement learning, which learns near-optimal data contribution strategy from the history of potential games without organizations' private information. Experiments demonstrate that our mechanism achieves adaptive incentive and effectively improves the long-term payoffs for organizations.
Data-Free Evaluation of User Contributions in Federated Learning
Aug 24, 2021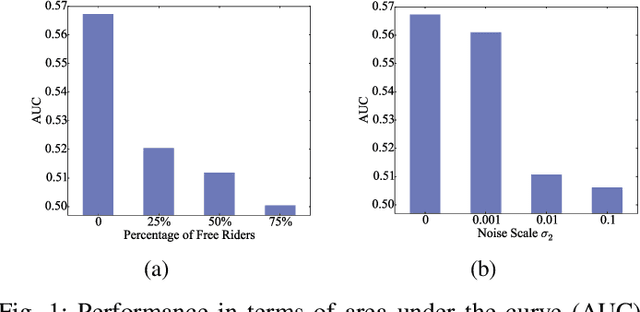
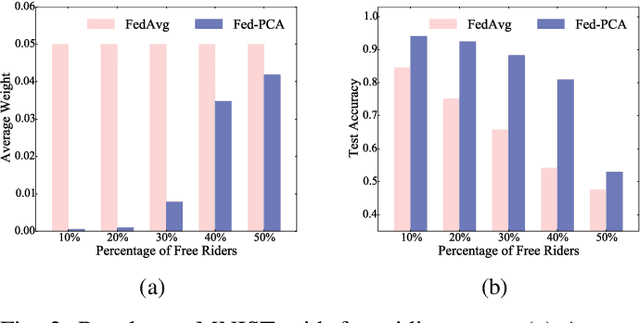
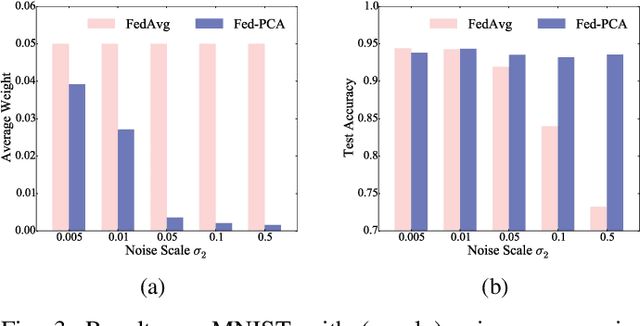
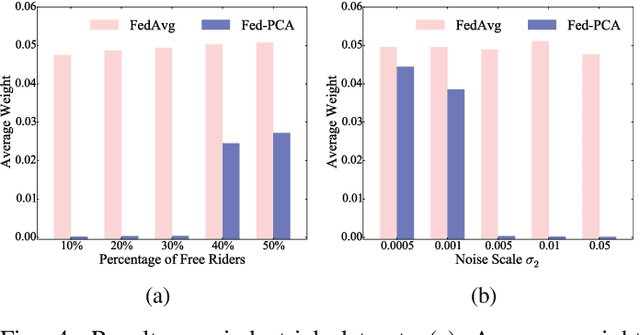
Federated learning (FL) trains a machine learning model on mobile devices in a distributed manner using each device's private data and computing resources. A critical issues is to evaluate individual users' contributions so that (1) users' effort in model training can be compensated with proper incentives and (2) malicious and low-quality users can be detected and removed. The state-of-the-art solutions require a representative test dataset for the evaluation purpose, but such a dataset is often unavailable and hard to synthesize. In this paper, we propose a method called Pairwise Correlated Agreement (PCA) based on the idea of peer prediction to evaluate user contribution in FL without a test dataset. PCA achieves this using the statistical correlation of the model parameters uploaded by users. We then apply PCA to designing (1) a new federated learning algorithm called Fed-PCA, and (2) a new incentive mechanism that guarantees truthfulness. We evaluate the performance of PCA and Fed-PCA using the MNIST dataset and a large industrial product recommendation dataset. The results demonstrate that our Fed-PCA outperforms the canonical FedAvg algorithm and other baseline methods in accuracy, and at the same time, PCA effectively incentivizes users to behave truthfully.
Neural Auction: End-to-End Learning of Auction Mechanisms for E-Commerce Advertising
Jun 07, 2021In e-commerce advertising, it is crucial to jointly consider various performance metrics, e.g., user experience, advertiser utility, and platform revenue. Traditional auction mechanisms, such as GSP and VCG auctions, can be suboptimal due to their fixed allocation rules to optimize a single performance metric (e.g., revenue or social welfare). Recently, data-driven auctions, learned directly from auction outcomes to optimize multiple performance metrics, have attracted increasing research interests. However, the procedure of auction mechanisms involves various discrete calculation operations, making it challenging to be compatible with continuous optimization pipelines in machine learning. In this paper, we design \underline{D}eep \underline{N}eural \underline{A}uctions (DNAs) to enable end-to-end auction learning by proposing a differentiable model to relax the discrete sorting operation, a key component in auctions. We optimize the performance metrics by developing deep models to efficiently extract contexts from auctions, providing rich features for auction design. We further integrate the game theoretical conditions within the model design, to guarantee the stability of the auctions. DNAs have been successfully deployed in the e-commerce advertising system at Taobao. Experimental evaluation results on both large-scale data set as well as online A/B test demonstrated that DNAs significantly outperformed other mechanisms widely adopted in industry.