 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Trimming and Auxiliary Multi-step Prediction for Generative Recommendation
Apr 07, 2026Generative Recommendation (GR) has recently transitioned from atomic item-indexing to Semantic ID (SID)-based frameworks to capture intrinsic item relationships and enhance generalization. However, the adoption of high-granularity SIDs leads to two critical challenges: prohibitive training overhead due to sequence expansion and unstable performance reliability characterized by non-monotonic accuracy fluctuations. We identify that these disparate issues are fundamentally rooted in the Semantic Dilution Effect, where redundant tokens waste massive computation and dilute the already sparse learning signals in recommendation. To counteract this, we propose STAMP (Semantic Trimming and Auxiliary Multi-step Prediction), a framework utilizing a dual-end optimization strategy. We argue that effective SID learning requires simultaneously addressing low input information density and sparse output supervision. On the input side, Semantic Adaptive Pruning (SAP) dynamically filters redundancy during the forward pass, converting noise-laden sequences into compact, information-rich representations. On the output side, Multi-step Auxiliary Prediction (MAP) employs a multi-token objective to densify feedback, strengthening long-range dependency capture and ensuring robust learning signals despite compressed inputs. Unifying input purification and signal amplification, STAMP enhances both training efficiency and representation capability. Experiments on public Amazon and large-scale industrial datasets show STAMP achieves 1.23--1.38$\times$ speedup and 17.2\%--54.7\% VRAM reduction while maintaining or improving performance across multiple architectures.
FHAvatar: Fast and High-Fidelity Reconstruction of Face-and-Hair Composable 3D Head Avatar from Few Casual Captures
Mar 24, 2026We present FHAvatar, a novel framework for reconstructing 3D Gaussian avatars with composable face and hair components from an arbitrary number of views. Unlike previous approaches that couple facial and hair representations within a unified modeling process, we explicitly decouple two components in texture space by representing the face with planar Gaussians and the hair with strand-based Gaussians. To overcome the limitations of existing methods that rely on dense multi-view captures or costly per-identity optimization, we propose an aggregated transformer backbone to learn geometry-aware cross-view priors and head-hair structural coherence from multi-view datasets, enabling effective and efficient feature extraction and fusion from few casual captures. Extensive quantitative and qualitative experiments demonstrate that FHAvatar achieves state-of-the-art reconstruction quality from only a few observations of new identities within minutes, while supporting real-time animation, convenient hairstyle transfer, and stylized editing, broadening the accessibility and applicability of digital avatar creation.
MobileKernelBench: Can LLMs Write Efficient Kernels for Mobile Devices?
Mar 12, 2026Large language models (LLMs) have demonstrated remarkable capabilities in code generation, yet their potential for generating kernels specifically for mobile de- vices remains largely unexplored. In this work, we extend the scope of automated kernel generation to the mobile domain to investigate the central question: Can LLMs write efficient kernels for mobile devices? To enable systematic investigation, we introduce MobileKernelBench, a comprehensive evaluation framework comprising a benchmark prioritizing operator diversity and cross-framework interoperability, coupled with an automated pipeline that bridges the host-device gap for on-device verification. Leveraging this framework, we conduct extensive evaluation on the CPU backend of Mobile Neural Network (MNN), revealing that current LLMs struggle with the engineering complexity and data scarcity inher-ent to mobile frameworks; standard models and even fine-tuned variants exhibit high compilation failure rates (over 54%) and negligible performance gains due to hallucinations and a lack of domain-specific grounding. To overcome these limitations, we propose the Mobile K ernel A gent (MoKA), a multi-agent system equipped with repository-aware reasoning and a plan-and-execute paradigm.Validated on MobileKernelBench, MoKA achieves state-of-the-art performance, boosting compilation success to 93.7% and enabling 27.4% of generated kernelsto deliver measurable speedups over native libraries.
AccKV: Towards Efficient Audio-Video LLMs Inference via Adaptive-Focusing and Cross-Calibration KV Cache Optimization
Nov 14, 2025

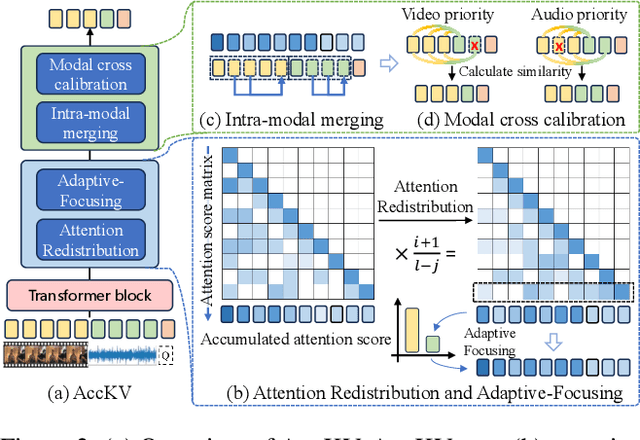

Recent advancements in Audio-Video Large Language Models (AV-LLMs) have enhanced their capabilities in tasks like audio-visual question answering and multimodal dialog systems. Video and audio introduce an extended temporal dimension, resulting in a larger key-value (KV) cache compared to static image embedding. A naive optimization strategy is to selectively focus on and retain KV caches of audio or video based on task. However, in the experiment, we observed that the attention of AV-LLMs to various modalities in the high layers is not strictly dependent on the task. In higher layers, the attention of AV-LLMs shifts more towards the video modality. In addition, we also found that directly integrating temporal KV of audio and spatial-temporal KV of video may lead to information confusion and significant performance degradation of AV-LLMs. If audio and video are processed indiscriminately, it may also lead to excessive compression or reservation of a certain modality, thereby disrupting the alignment between modalities. To address these challenges, we propose AccKV, an Adaptive-Focusing and Cross-Calibration KV cache optimization framework designed specifically for efficient AV-LLMs inference. Our method is based on layer adaptive focusing technology, selectively focusing on key modalities according to the characteristics of different layers, and enhances the recognition of heavy hitter tokens through attention redistribution. In addition, we propose a Cross-Calibration technique that first integrates inefficient KV caches within the audio and video modalities, and then aligns low-priority modalities with high-priority modalities to selectively evict KV cache of low-priority modalities. The experimental results show that AccKV can significantly improve the computational efficiency of AV-LLMs while maintaining accuracy.
MNN-LLM: A Generic Inference Engine for Fast Large Language Model Deployment on Mobile Devices
Jun 12, 2025Large language models (LLMs) have demonstrated exceptional performance across a variety of tasks. However, their substantial scale leads to significant computational resource consumption during inference, resulting in high costs. Consequently, edge device inference presents a promising solution. The primary challenges of edge inference include memory usage and inference speed. This paper introduces MNN-LLM, a framework specifically designed to accelerate the deployment of large language models on mobile devices. MNN-LLM addresses the runtime characteristics of LLMs through model quantization and DRAM-Flash hybrid storage, effectively reducing memory usage. It rearranges weights and inputs based on mobile CPU instruction sets and GPU characteristics while employing strategies such as multicore load balancing, mixed-precision floating-point operations, and geometric computations to enhance performance. Notably, MNN-LLM achieves up to a 8.6x speed increase compared to current mainstream LLM-specific frameworks.
Collaborative Learning of On-Device Small Model and Cloud-Based Large Model: Advances and Future Directions
Apr 17, 2025


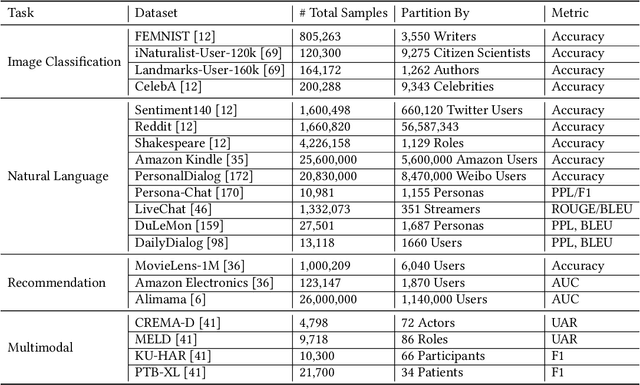
The conventional cloud-based large model learning framework is increasingly constrained by latency, cost, personalization, and privacy concerns. In this survey, we explore an emerging paradigm: collaborative learning between on-device small model and cloud-based large model, which promises low-latency, cost-efficient, and personalized intelligent services while preserving user privacy. We provide a comprehensive review across hardware, system, algorithm, and application layers. At each layer, we summarize key problems and recent advances from both academia and industry. In particular, we categorize collaboration algorithms into data-based, feature-based, and parameter-based frameworks. We also review publicly available datasets and evaluation metrics with user-level or device-level consideration tailored to collaborative learning settings. We further highlight real-world deployments, ranging from recommender systems and mobile livestreaming to personal intelligent assistants. We finally point out open research directions to guide future development in this rapidly evolving field.
Personalized LLM for Generating Customized Responses to the Same Query from Different Users
Dec 16, 2024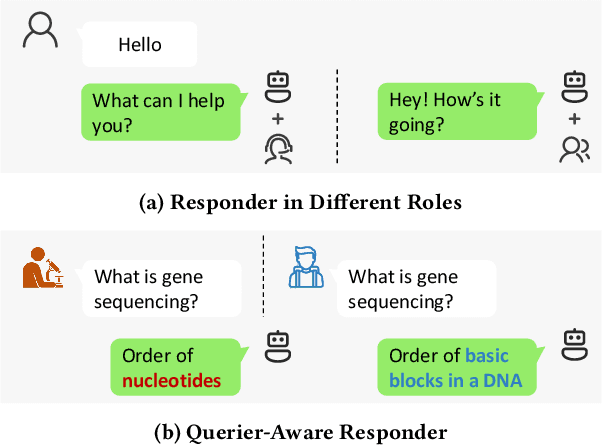
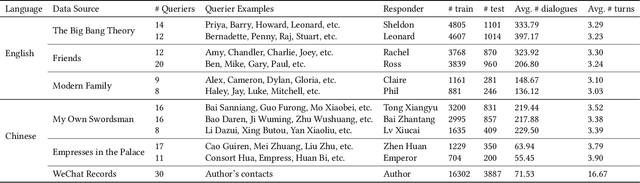
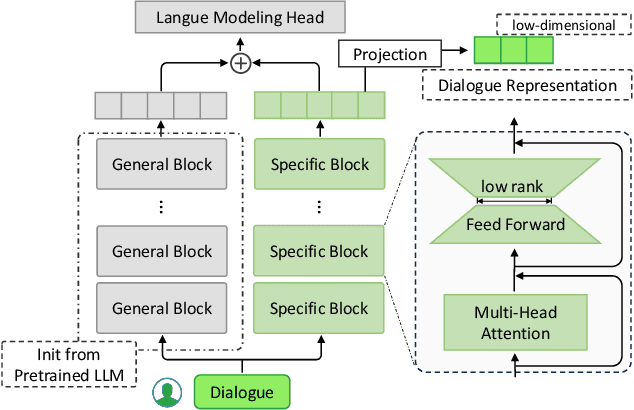
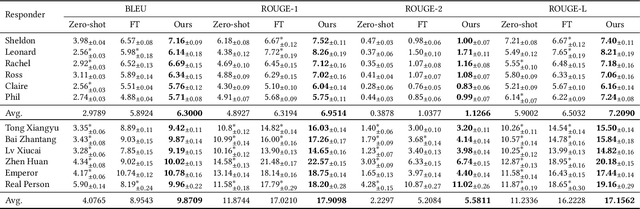
Existing work on large language model (LLM) personalization assigned different responding roles to LLM, but overlooked the diversity of questioners. In this work, we propose a new form of questioner-aware LLM personalization, generating different responses even for the same query from different questioners. We design a dual-tower model architecture with a cross-questioner general encoder and a questioner-specific encoder. We further apply contrastive learning with multi-view augmentation, pulling close the dialogue representations of the same questioner, while pulling apart those of different questioners. To mitigate the impact of question diversity on questioner-contrastive learning, we cluster the dialogues based on question similarity and restrict the scope of contrastive learning within each cluster. We also build a multi-questioner dataset from English and Chinese scripts and WeChat records, called MQDialog, containing 173 questioners and 12 responders. Extensive evaluation with different metrics shows a significant improvement in the quality of personalized response generation.
SpatialDreamer: Self-supervised Stereo Video Synthesis from Monocular Input
Nov 18, 2024Stereo video synthesis from a monocular input is a demanding task in the fields of spatial computing and virtual reality. The main challenges of this task lie on the insufficiency of high-quality paired stereo videos for training and the difficulty of maintaining the spatio-temporal consistency between frames. Existing methods primarily address these issues by directly applying novel view synthesis (NVS) techniques to video, while facing limitations such as the inability to effectively represent dynamic scenes and the requirement for large amounts of training data. In this paper, we introduce a novel self-supervised stereo video synthesis paradigm via a video diffusion model, termed SpatialDreamer, which meets the challenges head-on. Firstly, to address the stereo video data insufficiency, we propose a Depth based Video Generation module DVG, which employs a forward-backward rendering mechanism to generate paired videos with geometric and temporal priors. Leveraging data generated by DVG, we propose RefinerNet along with a self-supervised synthetic framework designed to facilitate efficient and dedicated training. More importantly, we devise a consistency control module, which consists of a metric of stereo deviation strength and a Temporal Interaction Learning module TIL for geometric and temporal consistency ensurance respectively. We evaluated the proposed method against various benchmark methods, with the results showcasing its superior performance.
GlossyGS: Inverse Rendering of Glossy Objects with 3D Gaussian Splatting
Oct 17, 2024

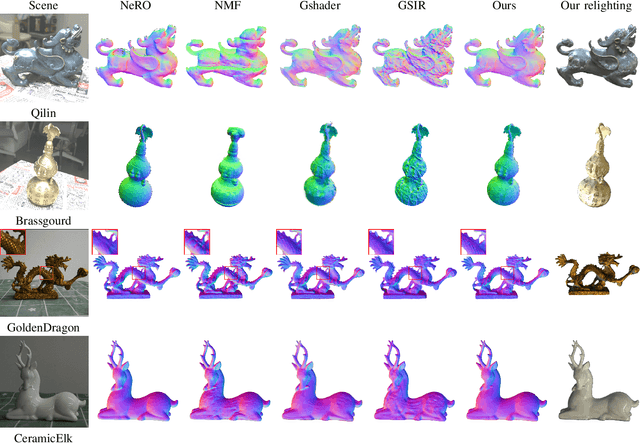
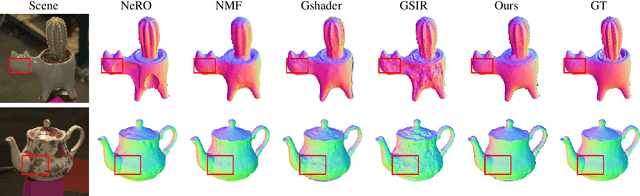
Reconstructing objects from posed images is a crucial and complex task in computer graphics and computer vision. While NeRF-based neural reconstruction methods have exhibited impressive reconstruction ability, they tend to be time-comsuming. Recent strategies have adopted 3D Gaussian Splatting (3D-GS) for inverse rendering, which have led to quick and effective outcomes. However, these techniques generally have difficulty in producing believable geometries and materials for glossy objects, a challenge that stems from the inherent ambiguities of inverse rendering. To address this, we introduce GlossyGS, an innovative 3D-GS-based inverse rendering framework that aims to precisely reconstruct the geometry and materials of glossy objects by integrating material priors. The key idea is the use of micro-facet geometry segmentation prior, which helps to reduce the intrinsic ambiguities and improve the decomposition of geometries and materials. Additionally, we introduce a normal map prefiltering strategy to more accurately simulate the normal distribution of reflective surfaces. These strategies are integrated into a hybrid geometry and material representation that employs both explicit and implicit methods to depict glossy objects. We demonstrate through quantitative analysis and qualitative visualization that the proposed method is effective to reconstruct high-fidelity geometries and materials of glossy objects, and performs favorably against state-of-the-arts.
GaussianTalker: Speaker-specific Talking Head Synthesis via 3D Gaussian Splatting
Apr 28, 2024



Recent works on audio-driven talking head synthesis using Neural Radiance Fields (NeRF) have achieved impressive results. However, due to inadequate pose and expression control caused by NeRF implicit representation, these methods still have some limitations, such as unsynchronized or unnatural lip movements, and visual jitter and artifacts. In this paper, we propose GaussianTalker, a novel method for audio-driven talking head synthesis based on 3D Gaussian Splatting. With the explicit representation property of 3D Gaussians, intuitive control of the facial motion is achieved by binding Gaussians to 3D facial models. GaussianTalker consists of two modules, Speaker-specific Motion Translator and Dynamic Gaussian Renderer. Speaker-specific Motion Translator achieves accurate lip movements specific to the target speaker through universalized audio feature extraction and customized lip motion generation. Dynamic Gaussian Renderer introduces Speaker-specific BlendShapes to enhance facial detail representation via a latent pose, delivering stable and realistic rendered videos. Extensive experimental results suggest that GaussianTalker outperforms existing state-of-the-art methods in talking head synthesis, delivering precise lip synchronization and exceptional visual quality. Our method achieves rendering speeds of 130 FPS on NVIDIA RTX4090 GPU, significantly exceeding the threshold for real-time rendering performance, and can potentially be deployed on other hardware platforms.