 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatialDreamer: Self-supervised Stereo Video Synthesis from Monocular Input
Nov 18, 2024Stereo video synthesis from a monocular input is a demanding task in the fields of spatial computing and virtual reality. The main challenges of this task lie on the insufficiency of high-quality paired stereo videos for training and the difficulty of maintaining the spatio-temporal consistency between frames. Existing methods primarily address these issues by directly applying novel view synthesis (NVS) techniques to video, while facing limitations such as the inability to effectively represent dynamic scenes and the requirement for large amounts of training data. In this paper, we introduce a novel self-supervised stereo video synthesis paradigm via a video diffusion model, termed SpatialDreamer, which meets the challenges head-on. Firstly, to address the stereo video data insufficiency, we propose a Depth based Video Generation module DVG, which employs a forward-backward rendering mechanism to generate paired videos with geometric and temporal priors. Leveraging data generated by DVG, we propose RefinerNet along with a self-supervised synthetic framework designed to facilitate efficient and dedicated training. More importantly, we devise a consistency control module, which consists of a metric of stereo deviation strength and a Temporal Interaction Learning module TIL for geometric and temporal consistency ensurance respectively. We evaluated the proposed method against various benchmark methods, with the results showcasing its superior performance.
Local Similarity Pattern and Cost Self-Reassembling for Deep Stereo Matching Networks
Dec 05, 2021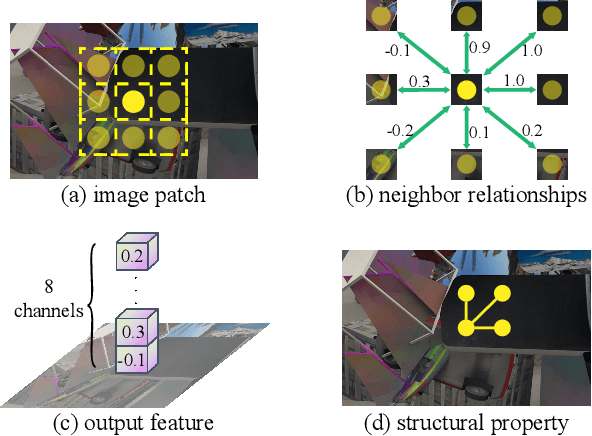
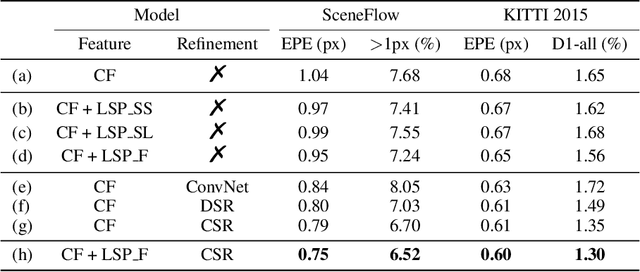
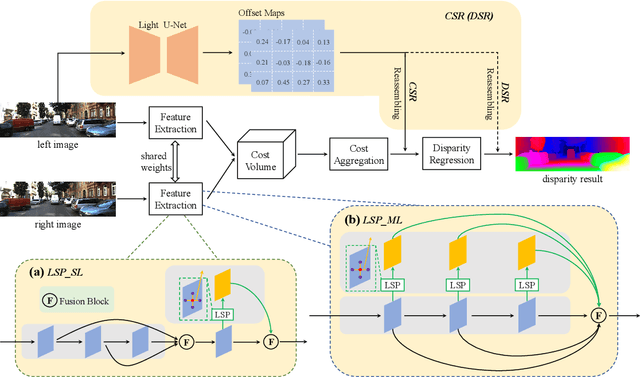
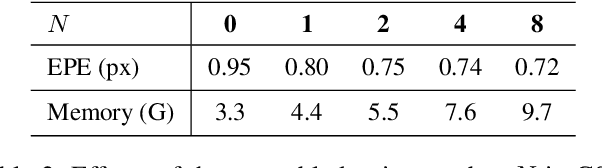
Although convolution neural network based stereo matching architectures have made impressive achievements, there are still some limitations: 1) Convolutional Feature (CF) tends to capture appearance information, which is inadequate for accurate matching. 2) Due to the static filters, current convolution based disparity refinement modules often produce over-smooth results. In this paper, we present two schemes to address these issues, where some traditional wisdoms are integrated. Firstly, we introduce a pairwise feature for deep stereo matching networks, named LSP (Local Similarity Pattern). Through explicitly revealing the neighbor relationships, LSP contains rich structural information, which can be leveraged to aid CF for more discriminative feature description. Secondly, we design a dynamic self-reassembling refinement strategy and apply it to the cost distribution and the disparity map respectively. The former could be equipped with the unimodal distribution constraint to alleviate the over-smoothing problem, and the latter is more practical. The effectiveness of the proposed methods is demonstrated via incorporating them into two well-known basic architectures, GwcNet and GANet-deep. Experimental results on the SceneFlow and KITTI benchmarks show that our modules significantly improve the performance of the model.
Fractal Pyramid Networks
Jun 28, 2021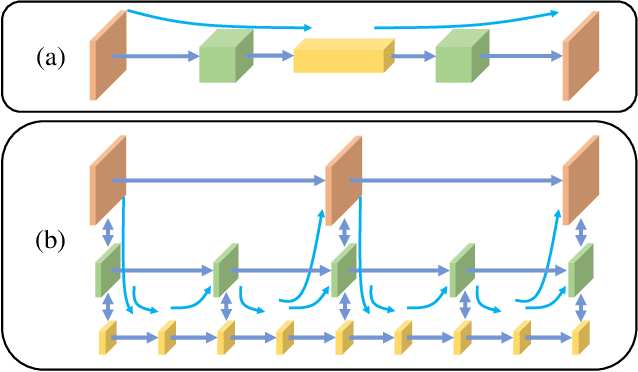
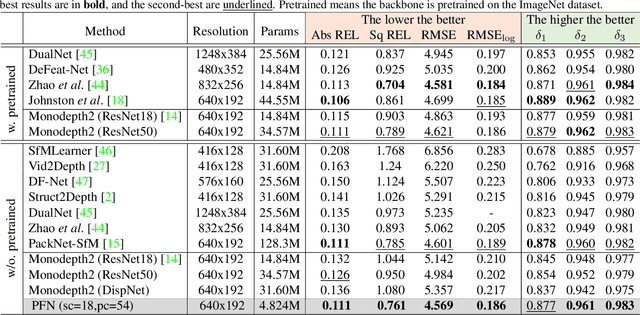
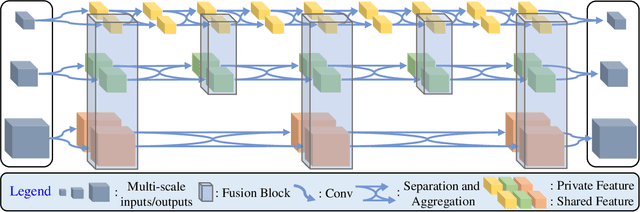
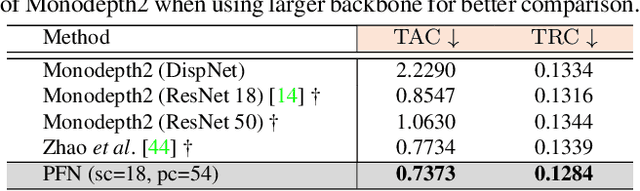
We propose a new network architecture, the Fractal Pyramid Networks (PFNs) for pixel-wise prediction tasks as an alternative to the widely used encoder-decoder structure. In the encoder-decoder structure, the input is processed by an encoding-decoding pipeline that tries to get a semantic large-channel feature. Different from that, our proposed PFNs hold multiple information processing pathways and encode the information to multiple separate small-channel features. On the task of self-supervised monocular depth estimation, even without ImageNet pretrained, our models can compete or outperform the state-of-the-art methods on the KITTI dataset with much fewer parameters. Moreover, the visual quality of the prediction is significantly improved. The experiment of semantic segmentation provides evidence that the PFNs can be applied to other pixel-wise prediction tasks, and demonstrates that our models can catch more global structure information.