 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrientation Matters: Making 3D Generative Models Orientation-Aligned
Jun 10, 2025Humans intuitively perceive object shape and orientation from a single image, guided by strong priors about canonical poses. However, existing 3D generative models often produce misaligned results due to inconsistent training data, limiting their usability in downstream tasks. To address this gap, we introduce the task of orientation-aligned 3D object generation: producing 3D objects from single images with consistent orientations across categories. To facilitate this, we construct Objaverse-OA, a dataset of 14,832 orientation-aligned 3D models spanning 1,008 categories. Leveraging Objaverse-OA, we fine-tune two representative 3D generative models based on multi-view diffusion and 3D variational autoencoder frameworks to produce aligned objects that generalize well to unseen objects across various categories. Experimental results demonstrate the superiority of our method over post-hoc alignment approaches. Furthermore, we showcase downstream applications enabled by our aligned object generation, including zero-shot object orientation estimation via analysis-by-synthesis and efficient arrow-based object rotation manipulation.
UrbanCAD: Towards Highly Controllable and Photorealistic 3D Vehicles for Urban Scene Simulation
Nov 28, 2024Photorealistic 3D vehicle models with high controllability are essential for autonomous driving simulation and data augmentation. While handcrafted CAD models provide flexible controllability, free CAD libraries often lack the high-quality materials necessary for photorealistic rendering. Conversely, reconstructed 3D models offer high-fidelity rendering but lack controllability. In this work, we introduce UrbanCAD, a framework that pushes the frontier of the photorealism-controllability trade-off by generating highly controllable and photorealistic 3D vehicle digital twins from a single urban image and a collection of free 3D CAD models and handcrafted materials. These digital twins enable realistic 360-degree rendering, vehicle insertion, material transfer, relighting, and component manipulation such as opening doors and rolling down windows, supporting the construction of long-tail scenarios. To achieve this, we propose a novel pipeline that operates in a retrieval-optimization manner, adapting to observational data while preserving flexible controllability and fine-grained handcrafted details. Furthermore, given multi-view background perspective and fisheye images, we approximate environment lighting using fisheye images and reconstruct the background with 3DGS, enabling the photorealistic insertion of optimized CAD models into rendered novel view backgrounds. Experimental results demonstrate that UrbanCAD outperforms baselines based on reconstruction and retrieval in terms of photorealism. Additionally, we show that various perception models maintain their accuracy when evaluated on UrbanCAD with in-distribution configurations but degrade when applied to realistic out-of-distribution data generated by our method. This suggests that UrbanCAD is a significant advancement in creating photorealistic, safety-critical driving scenarios for downstream applications.
Exploring Shape Embedding for Cloth-Changing Person Re-Identification via 2D-3D Correspondences
Oct 27, 2023



Cloth-Changing Person Re-Identification (CC-ReID) is a common and realistic problem since fashion constantly changes over time and people's aesthetic preferences are not set in stone. While most existing cloth-changing ReID methods focus on learning cloth-agnostic identity representations from coarse semantic cues (e.g. silhouettes and part segmentation maps), they neglect the continuous shape distributions at the pixel level. In this paper, we propose Continuous Surface Correspondence Learning (CSCL), a new shape embedding paradigm for cloth-changing ReID. CSCL establishes continuous correspondences between a 2D image plane and a canonical 3D body surface via pixel-to-vertex classification, which naturally aligns a person image to the surface of a 3D human model and simultaneously obtains pixel-wise surface embeddings. We further extract fine-grained shape features from the learned surface embeddings and then integrate them with global RGB features via a carefully designed cross-modality fusion module. The shape embedding paradigm based on 2D-3D correspondences remarkably enhances the model's global understanding of human body shape. To promote the study of ReID under clothing change, we construct 3D Dense Persons (DP3D), which is the first large-scale cloth-changing ReID dataset that provides densely annotated 2D-3D correspondences and a precise 3D mesh for each person image, while containing diverse cloth-changing cases over all four seasons. Experiments on both cloth-changing and cloth-consistent ReID benchmarks validate the effectiveness of our method.
CMVAE: Causal Meta VAE for Unsupervised Meta-Learning
Feb 20, 2023Unsupervised meta-learning aims to learn the meta knowledge from unlabeled data and rapidly adapt to novel tasks. However, existing approaches may be misled by the context-bias (e.g. background) from the training data. In this paper, we abstract the unsupervised meta-learning problem into a Structural Causal Model (SCM) and point out that such bias arises due to hidden confounders. To eliminate the confounders, we define the priors are \textit{conditionally} independent, learn the relationships between priors and intervene on them with casual factorization. Furthermore, we propose Causal Meta VAE (CMVAE) that encodes the priors into latent codes in the causal space and learns their relationships simultaneously to achieve the downstream few-shot image classification task. Results on toy datasets and three benchmark datasets demonstrate that our method can remove the context-bias and it outperforms other state-of-the-art unsupervised meta-learning algorithms because of bias-removal. Code is available at \url{https://github.com/GuodongQi/CMVAE}
Searching Similarity Measure for Binarized Neural Networks
Jun 05, 2022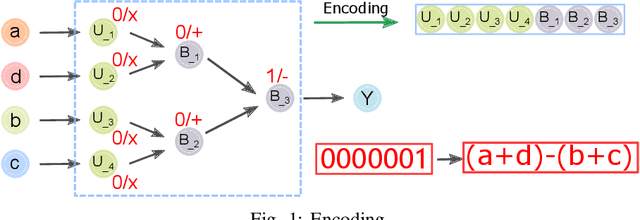
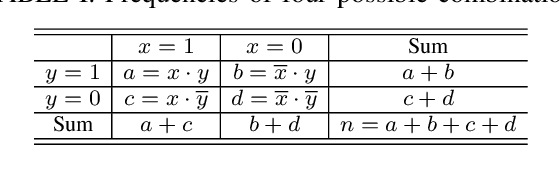
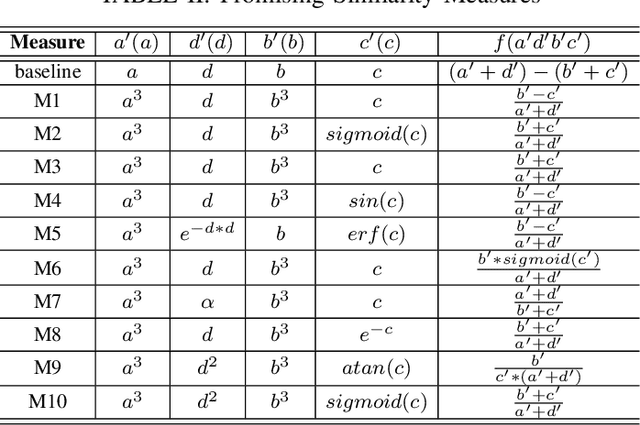
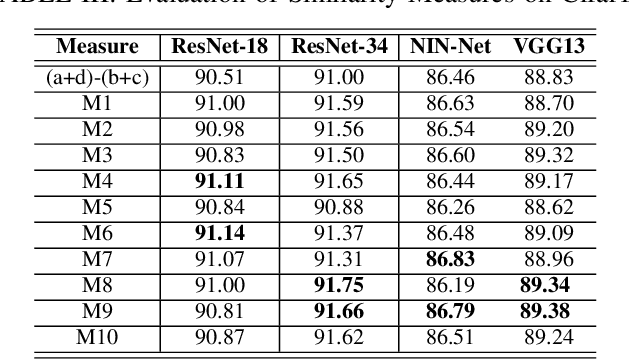
Being a promising model to be deployed in resource-limited devices, Binarized Neural Networks (BNNs) have drawn extensive attention from both academic and industry. However, comparing to the full-precision deep neural networks (DNNs), BNNs suffer from non-trivial accuracy degradation, limiting its applicability in various domains. This is partially because existing network components, such as the similarity measure, are specially designed for DNNs, and might be sub-optimal for BNNs. In this work, we focus on the key component of BNNs -- the similarity measure, which quantifies the distance between input feature maps and filters, and propose an automatic searching method, based on genetic algorithm, for BNN-tailored similarity measure. Evaluation results on Cifar10 and Cifar100 using ResNet, NIN and VGG show that most of the identified similarty measure can achieve considerable accuracy improvement (up to 3.39%) over the commonly-used cross-correlation approach.
GAAF: Searching Activation Functions for Binary Neural Networks through Genetic Algorithm
Jun 05, 2022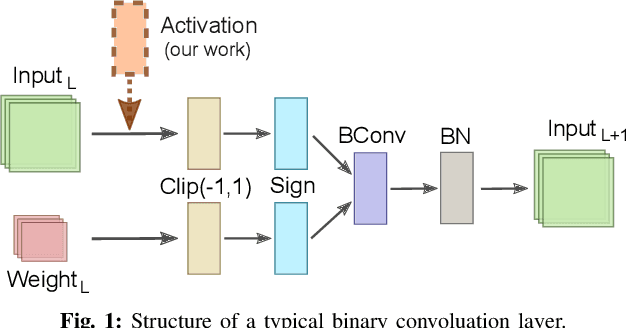
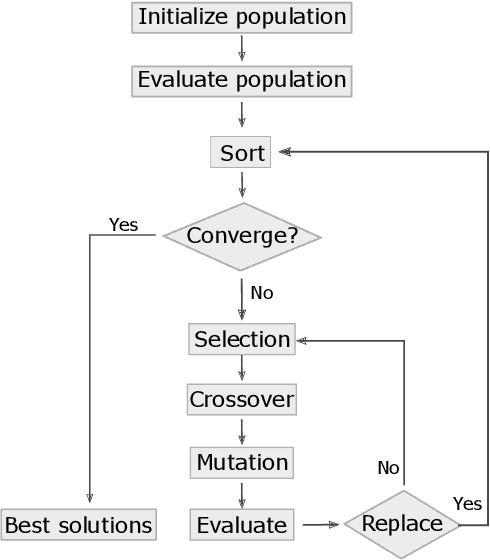
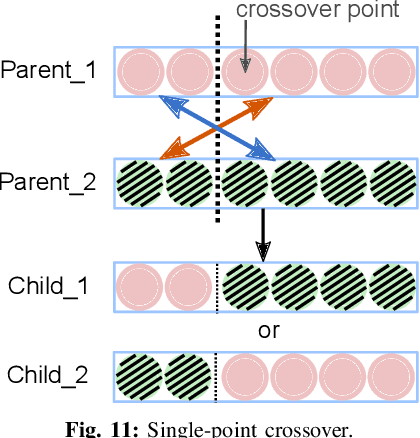
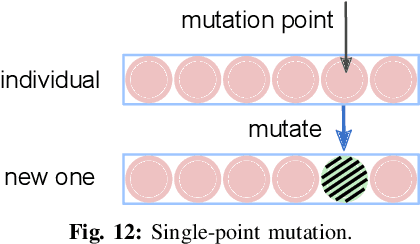
Binary neural networks (BNNs) show promising utilization in cost and power-restricted domains such as edge devices and mobile systems. This is due to its significantly less computation and storage demand, but at the cost of degraded performance. To close the accuracy gap, in this paper we propose to add a complementary activation function (AF) ahead of the sign based binarization, and rely on the genetic algorithm (GA) to automatically search for the ideal AFs. These AFs can help extract extra information from the input data in the forward pass, while allowing improved gradient approximation in the backward pass. Fifteen novel AFs are identified through our GA-based search, while most of them show improved performance (up to 2.54% on ImageNet) when testing on different datasets and network models. Our method offers a novel approach for designing general and application-specific BNN architecture. Our code is available at http://github.com/flying-Yan/GAAF.
GraftNet: Towards Domain Generalized Stereo Matching with a Broad-Spectrum and Task-Oriented Feature
Apr 01, 2022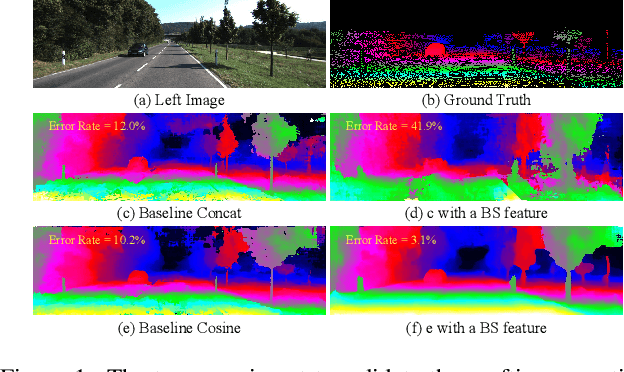
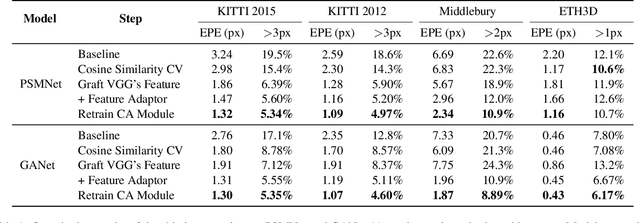
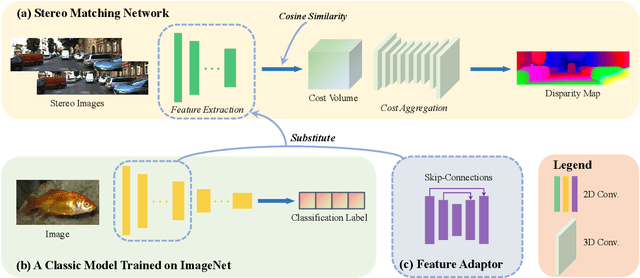

Although supervised deep stereo matching networks have made impressive achievements, the poor generalization ability caused by the domain gap prevents them from being applied to real-life scenarios. In this paper, we propose to leverage the feature of a model trained on large-scale datasets to deal with the domain shift since it has seen various styles of images. With the cosine similarity based cost volume as a bridge, the feature will be grafted to an ordinary cost aggregation module. Despite the broad-spectrum representation, such a low-level feature contains much general information which is not aimed at stereo matching. To recover more task-specific information, the grafted feature is further input into a shallow network to be transformed before calculating the cost. Extensive experiments show that the model generalization ability can be improved significantly with this broad-spectrum and task-oriented feature. Specifically, based on two well-known architectures PSMNet and GANet, our methods are superior to other robust algorithms when transferring from SceneFlow to KITTI 2015, KITTI 2012, and Middlebury. Code is available at https://github.com/SpadeLiu/Graft-PSMNet.
Gated Domain-Invariant Feature Disentanglement for Domain Generalizable Object Detection
Mar 22, 2022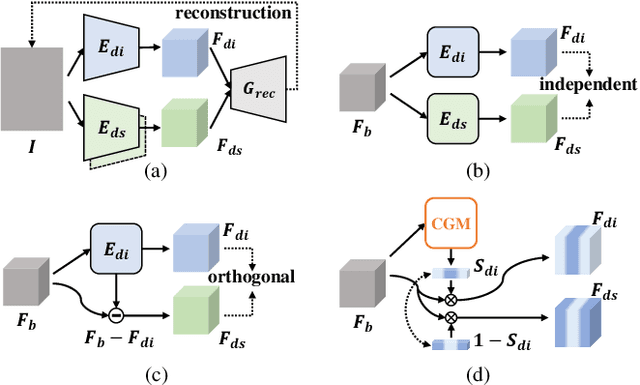


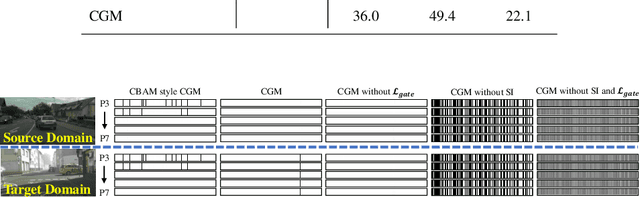
For Domain Generalizable Object Detection (DGOD), Disentangled Representation Learning (DRL) helps a lot by explicitly disentangling Domain-Invariant Representations (DIR) from Domain-Specific Representations (DSR). Considering the domain category is an attribute of input data, it should be feasible for networks to fit a specific mapping which projects DSR into feature channels exclusive to domain-specific information, and thus much cleaner disentanglement of DIR from DSR can be achieved simply on channel dimension. Inspired by this idea, we propose a novel DRL method for DGOD, which is termed Gated Domain-Invariant Feature Disentanglement (GDIFD). In GDIFD, a Channel Gate Module (CGM) learns to output channel gate signals close to either 0 or 1, which can mask out the channels exclusive to domain-specific information helpful for domain recognition. With the proposed GDIFD, the backbone in our framework can fit the desired mapping easily, which enables the channel-wise disentanglement. In experiments, we demonstrate that our approach is highly effective and achieves state-of-the-art DGOD performance.
Local Similarity Pattern and Cost Self-Reassembling for Deep Stereo Matching Networks
Dec 05, 2021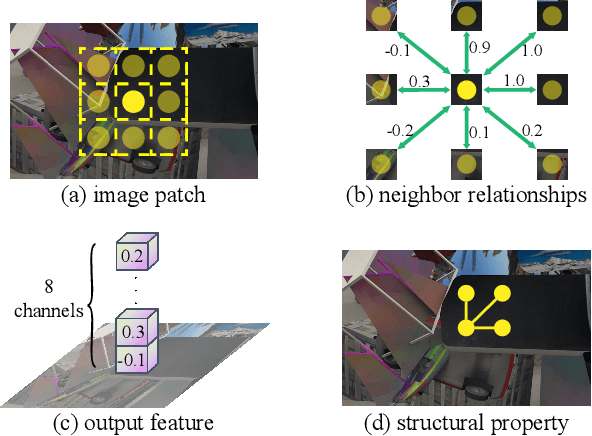
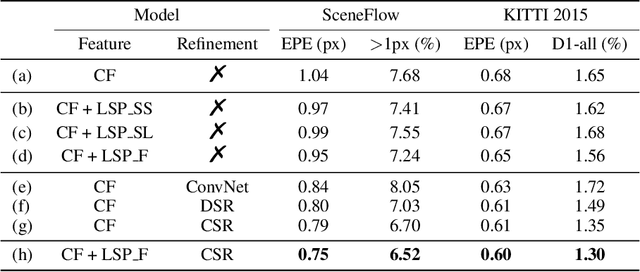
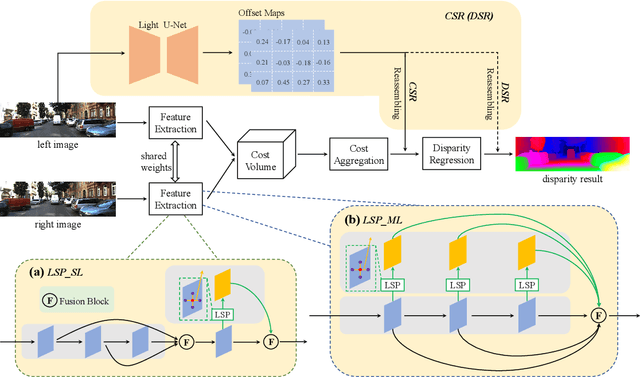
Although convolution neural network based stereo matching architectures have made impressive achievements, there are still some limitations: 1) Convolutional Feature (CF) tends to capture appearance information, which is inadequate for accurate matching. 2) Due to the static filters, current convolution based disparity refinement modules often produce over-smooth results. In this paper, we present two schemes to address these issues, where some traditional wisdoms are integrated. Firstly, we introduce a pairwise feature for deep stereo matching networks, named LSP (Local Similarity Pattern). Through explicitly revealing the neighbor relationships, LSP contains rich structural information, which can be leveraged to aid CF for more discriminative feature description. Secondly, we design a dynamic self-reassembling refinement strategy and apply it to the cost distribution and the disparity map respectively. The former could be equipped with the unimodal distribution constraint to alleviate the over-smoothing problem, and the latter is more practical. The effectiveness of the proposed methods is demonstrated via incorporating them into two well-known basic architectures, GwcNet and GANet-deep. Experimental results on the SceneFlow and KITTI benchmarks show that our modules significantly improve the performance of the model.
Transductive Few-Shot Classification on the Oblique Manifold
Aug 09, 2021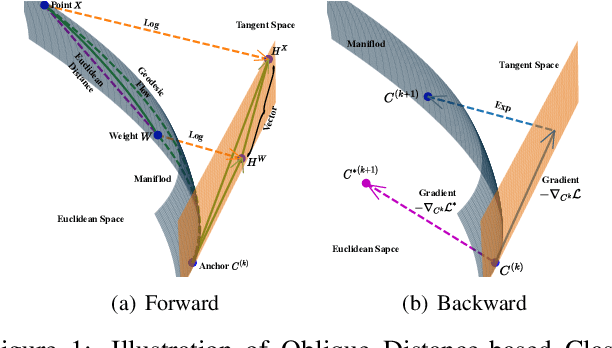
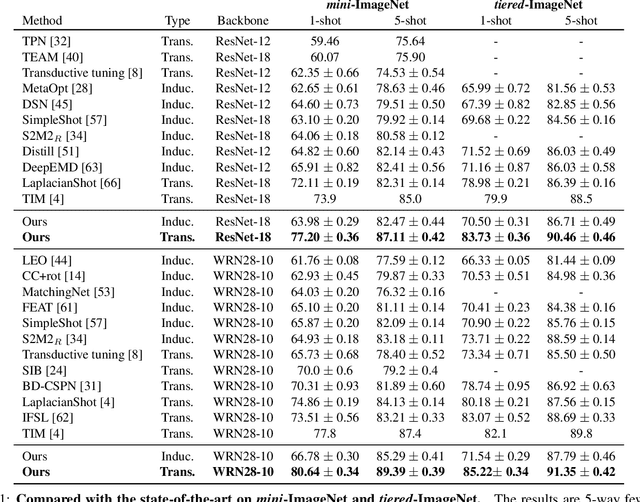
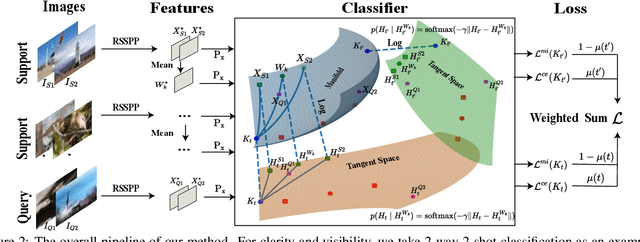
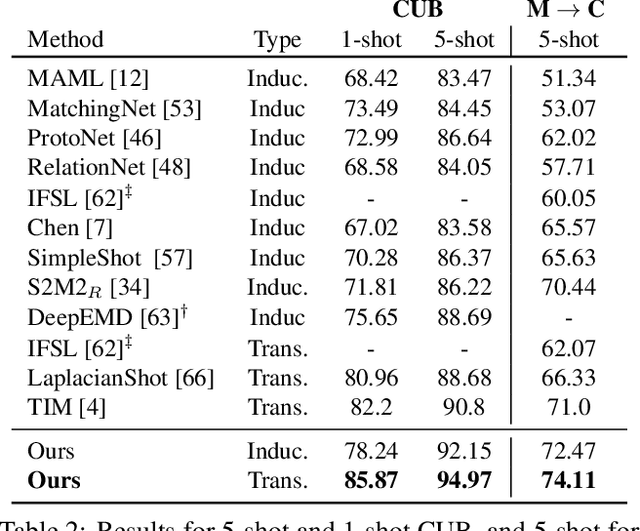
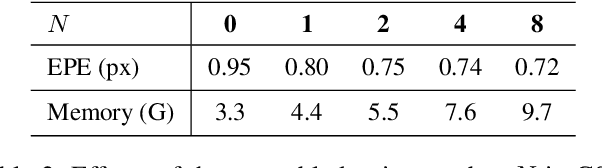
Few-shot learning (FSL) attempts to learn with limited data. In this work, we perform the feature extraction in the Euclidean space and the geodesic distance metric on the Oblique Manifold (OM). Specially, for better feature extraction, we propose a non-parametric Region Self-attention with Spatial Pyramid Pooling (RSSPP), which realizes a trade-off between the generalization and the discriminative ability of the single image feature. Then, we embed the feature to OM as a point. Furthermore, we design an Oblique Distance-based Classifier (ODC) that achieves classification in the tangent spaces which better approximate OM locally by learnable tangency points. Finally, we introduce a new method for parameters initialization and a novel loss function in the transductive settings. Extensive experiments demonstrate the effectiveness of our algorithm and it outperforms state-of-the-art methods on the popular benchmarks: mini-ImageNet, tiered-ImageNet, and Caltech-UCSD Birds-200-2011 (CUB).