 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Constant Eye: Benchmarking and Bridging Appearance Robustness in Autonomous Driving
Feb 13, 2026Despite rapid progress, autonomous driving algorithms remain notoriously fragile under Out-of-Distribution (OOD) conditions. We identify a critical decoupling failure in current research: the lack of distinction between appearance-based shifts, such as weather and lighting, and structural scene changes. This leaves a fundamental question unanswered: Is the planner failing because of complex road geometry, or simply because it is raining? To resolve this, we establish navdream, a high-fidelity robustness benchmark leveraging generative pixel-aligned style transfer. By creating a visual stress test with negligible geometric deviation, we isolate the impact of appearance on driving performance. Our evaluation reveals that existing planning algorithms often show significant degradation under OOD appearance conditions, even when the underlying scene structure remains consistent. To bridge this gap, we propose a universal perception interface leveraging a frozen visual foundation model (DINOv3). By extracting appearance-invariant features as a stable interface for the planner, we achieve exceptional zero-shot generalization across diverse planning paradigms, including regression-based, diffusion-based, and scoring-based models. Our plug-and-play solution maintains consistent performance across extreme appearance shifts without requiring further fine-tuning. The benchmark and code will be made available.
ReRoPE: Repurposing RoPE for Relative Camera Control
Feb 08, 2026Video generation with controllable camera viewpoints is essential for applications such as interactive content creation, gaming, and simulation. Existing methods typically adapt pre-trained video models using camera poses relative to a fixed reference, e.g., the first frame. However, these encodings lack shift-invariance, often leading to poor generalization and accumulated drift. While relative camera pose embeddings defined between arbitrary view pairs offer a more robust alternative, integrating them into pre-trained video diffusion models without prohibitive training costs or architectural changes remains challenging. We introduce ReRoPE, a plug-and-play framework that incorporates relative camera information into pre-trained video diffusion models without compromising their generation capability. Our approach is based on the insight that Rotary Positional Embeddings (RoPE) in existing models underutilize their full spectral bandwidth, particularly in the low-frequency components. By seamlessly injecting relative camera pose information into these underutilized bands, ReRoPE achieves precise control while preserving strong pre-trained generative priors. We evaluate our method on both image-to-video (I2V) and video-to-video (V2V) tasks in terms of camera control accuracy and visual fidelity. Our results demonstrate that ReRoPE offers a training-efficient path toward controllable, high-fidelity video generation. See project page for more results: https://sisyphe-lee.github.io/ReRoPE/
Gen3R: 3D Scene Generation Meets Feed-Forward Reconstruction
Jan 07, 2026We present Gen3R, a method that bridges the strong priors of foundational reconstruction models and video diffusion models for scene-level 3D generation. We repurpose the VGGT reconstruction model to produce geometric latents by training an adapter on its tokens, which are regularized to align with the appearance latents of pre-trained video diffusion models. By jointly generating these disentangled yet aligned latents, Gen3R produces both RGB videos and corresponding 3D geometry, including camera poses, depth maps, and global point clouds. Experiments demonstrate that our approach achieves state-of-the-art results in single- and multi-image conditioned 3D scene generation. Additionally, our method can enhance the robustness of reconstruction by leveraging generative priors, demonstrating the mutual benefit of tightly coupling reconstruction and generative models.
Orientation Matters: Making 3D Generative Models Orientation-Aligned
Jun 10, 2025Humans intuitively perceive object shape and orientation from a single image, guided by strong priors about canonical poses. However, existing 3D generative models often produce misaligned results due to inconsistent training data, limiting their usability in downstream tasks. To address this gap, we introduce the task of orientation-aligned 3D object generation: producing 3D objects from single images with consistent orientations across categories. To facilitate this, we construct Objaverse-OA, a dataset of 14,832 orientation-aligned 3D models spanning 1,008 categories. Leveraging Objaverse-OA, we fine-tune two representative 3D generative models based on multi-view diffusion and 3D variational autoencoder frameworks to produce aligned objects that generalize well to unseen objects across various categories. Experimental results demonstrate the superiority of our method over post-hoc alignment approaches. Furthermore, we showcase downstream applications enabled by our aligned object generation, including zero-shot object orientation estimation via analysis-by-synthesis and efficient arrow-based object rotation manipulation.
Prometheus: 3D-Aware Latent Diffusion Models for Feed-Forward Text-to-3D Scene Generation
Dec 30, 2024In this work, we introduce Prometheus, a 3D-aware latent diffusion model for text-to-3D generation at both object and scene levels in seconds. We formulate 3D scene generation as multi-view, feed-forward, pixel-aligned 3D Gaussian generation within the latent diffusion paradigm. To ensure generalizability, we build our model upon pre-trained text-to-image generation model with only minimal adjustments, and further train it using a large number of images from both single-view and multi-view datasets. Furthermore, we introduce an RGB-D latent space into 3D Gaussian generation to disentangle appearance and geometry information, enabling efficient feed-forward generation of 3D Gaussians with better fidelity and geometry. Extensive experimental results demonstrate the effectiveness of our method in both feed-forward 3D Gaussian reconstruction and text-to-3D generation. Project page: https://freemty.github.io/project-prometheus/
Learning Temporally Consistent Video Depth from Video Diffusion Priors
Jun 04, 2024This work addresses the challenge of video depth estimation, which expects not only per-frame accuracy but, more importantly, cross-frame consistency. Instead of directly developing a depth estimator from scratch, we reformulate the prediction task into a conditional generation problem. This allows us to leverage the prior knowledge embedded in existing video generation models, thereby reducing learning difficulty and enhancing generalizability. Concretely, we study how to tame the public Stable Video Diffusion (SVD) to predict reliable depth from input videos using a mixture of image depth and video depth datasets. We empirically confirm that a procedural training strategy -- first optimizing the spatial layers of SVD and then optimizing the temporal layers while keeping the spatial layers frozen -- yields the best results in terms of both spatial accuracy and temporal consistency. We further examine the sliding window strategy for inference on arbitrarily long videos. Our observations indicate a trade-off between efficiency and performance, with a one-frame overlap already producing favorable results. Extensive experimental results demonstrate the superiority of our approach, termed ChronoDepth, over existing alternatives, particularly in terms of the temporal consistency of the estimated depth. Additionally, we highlight the benefits of more consistent video depth in two practical applications: depth-conditioned video generation and novel view synthesis. Our project page is available at https://jhaoshao.github.io/ChronoDepth/.
MaPa: Text-driven Photorealistic Material Painting for 3D Shapes
Apr 26, 2024

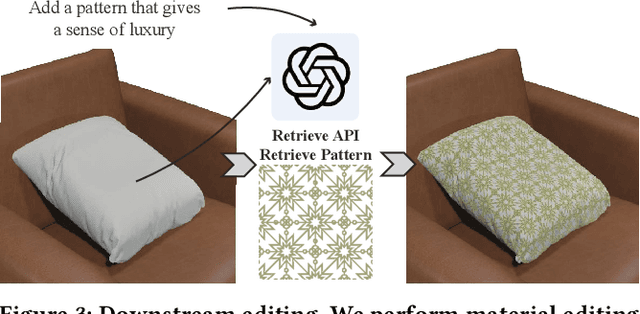

This paper aims to generate materials for 3D meshes from text descriptions. Unlike existing methods that synthesize texture maps, we propose to generate segment-wise procedural material graphs as the appearance representation, which supports high-quality rendering and provides substantial flexibility in editing. Instead of relying on extensive paired data, i.e., 3D meshes with material graphs and corresponding text descriptions, to train a material graph generative model, we propose to leverage the pre-trained 2D diffusion model as a bridge to connect the text and material graphs. Specifically, our approach decomposes a shape into a set of segments and designs a segment-controlled diffusion model to synthesize 2D images that are aligned with mesh parts. Based on generated images, we initialize parameters of material graphs and fine-tune them through the differentiable rendering module to produce materials in accordance with the textual description. Extensive experiments demonstrate the superior performance of our framework in photorealism, resolution, and editability over existing methods. Project page: https://zhanghe3z.github.io/MaPa/
Learning 3D-Aware GANs from Unposed Images with Template Feature Field
Apr 08, 2024



Collecting accurate camera poses of training images has been shown to well serve the learning of 3D-aware generative adversarial networks (GANs) yet can be quite expensive in practice. This work targets learning 3D-aware GANs from unposed images, for which we propose to perform on-the-fly pose estimation of training images with a learned template feature field (TeFF). Concretely, in addition to a generative radiance field as in previous approaches, we ask the generator to also learn a field from 2D semantic features while sharing the density from the radiance field. Such a framework allows us to acquire a canonical 3D feature template leveraging the dataset mean discovered by the generative model, and further efficiently estimate the pose parameters on real data. Experimental results on various challenging datasets demonstrate the superiority of our approach over state-of-the-art alternatives from both the qualitative and the quantitative perspectives.
UrbanGIRAFFE: Representing Urban Scenes as Compositional Generative Neural Feature Fields
Mar 28, 2023



Generating photorealistic images with controllable camera pose and scene contents is essential for many applications including AR/VR and simulation. Despite the fact that rapid progress has been made in 3D-aware generative models, most existing methods focus on object-centric images and are not applicable to generating urban scenes for free camera viewpoint control and scene editing. To address this challenging task, we propose UrbanGIRAFFE, which uses a coarse 3D panoptic prior, including the layout distribution of uncountable stuff and countable objects, to guide a 3D-aware generative model. Our model is compositional and controllable as it breaks down the scene into stuff, objects, and sky. Using stuff prior in the form of semantic voxel grids, we build a conditioned stuff generator that effectively incorporates the coarse semantic and geometry information. The object layout prior further allows us to learn an object generator from cluttered scenes. With proper loss functions, our approach facilitates photorealistic 3D-aware image synthesis with diverse controllability, including large camera movement, stuff editing, and object manipulation. We validate the effectiveness of our model on both synthetic and real-world datasets, including the challenging KITTI-360 dataset.
InvNorm: Domain Generalization for Object Detection in Gastrointestinal Endoscopy
May 05, 2022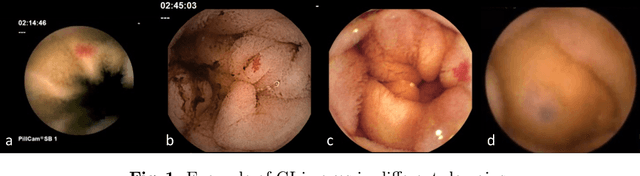
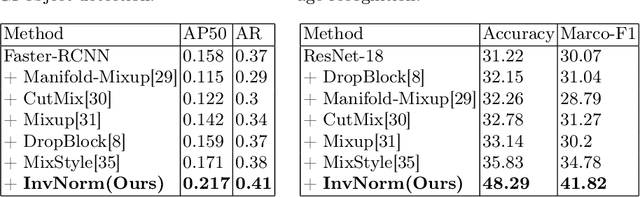
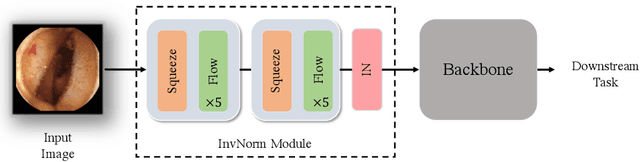
Domain Generalization is a challenging topic in computer vision, especially in Gastrointestinal Endoscopy image analysis. Due to several device limitations and ethical reasons, current open-source datasets are typically collected on a limited number of patients using the same brand of sensors. Different brands of devices and individual differences will significantly affect the model's generalizability. Therefore, to address the generalization problem in GI(Gastrointestinal) endoscopy, we propose a multi-domain GI dataset and a light, plug-in block called InvNorm(Invertible Normalization), which could achieve a better generalization performance in any structure. Previous DG(Domain Generalization) methods fail to achieve invertible transformation, which would lead to some misleading augmentation. Moreover, these models would be more likely to lead to medical ethics issues. Our method utilizes normalizing flow to achieve invertible and explainable style normalization to address the problem. The effectiveness of InvNorm is demonstrated on a wide range of tasks, including GI recognition, GI object detection, and natural image recognition.