 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Modal Machine Learning for Breast Cancer Recurrence Prediction
Jun 01, 2026Breast cancer recurrence, a leading cause of long-term mortality among survivors, requires timely and accurate risk assessment to guide follow-up care and treatment planning. Traditional predictive models, often limited to either structured or unstructured data alone, struggle to capture the full clinical context. This study examines the impact of integrating multi-modal clinical data, including treatment records, pathology reports, and clinician notes, on recurrence prediction. By integrating a rule-based regular expression extraction mechanism with a rigorous precedence-based conflict reconciliation strategy, our approach effectively recovers definitive tumor characteristics from free-text pathology narratives to augment structured records. We also benchmark performance against commonly used feature sets from prior breast cancer studies to assess the added value of multi-modal integration. Single-source and multi-modal inputs are evaluated across a range of machine learning models. Results show that multi-modal integration consistently improves predictive accuracy compared to single-modal methods.
Multi-Task LLM with LoRA Fine-Tuning for Automated Cancer Staging and Biomarker Extraction
Apr 14, 2026Pathology reports serve as the definitive record for breast cancer staging, yet their unstructured format impedes large-scale data curation. While Large Language Models (LLMs) offer semantic reasoning, their deployment is often limited by high computational costs and hallucination risks. This study introduces a parameter-efficient, multi-task framework for automating the extraction of Tumor-Node-Metastasis (TNM) staging, histologic grade, and biomarkers. We fine-tune a Llama-3-8B-Instruct encoder using Low-Rank Adaptation (LoRA) on a curated, expert-verified dataset of 10,677 reports. Unlike generative approaches, our architecture utilizes parallel classification heads to enforce consistent schema adherence. Experimental results demonstrate that the model achieves a Macro F1 score of 0.976, successfully resolving complex contextual ambiguities and heterogeneous reporting formats that challenge traditional extraction methods including rule-based natural language processing (NLP) pipelines, zero-shot LLMs, and single-task LLM baselines. The proposed adapter-efficient, multi-task architecture enables reliable, scalable pathology-derived cancer staging and biomarker profiling, with the potential to enhance clinical decision support and accelerate data-driven oncology research.
The Constant Eye: Benchmarking and Bridging Appearance Robustness in Autonomous Driving
Feb 13, 2026Despite rapid progress, autonomous driving algorithms remain notoriously fragile under Out-of-Distribution (OOD) conditions. We identify a critical decoupling failure in current research: the lack of distinction between appearance-based shifts, such as weather and lighting, and structural scene changes. This leaves a fundamental question unanswered: Is the planner failing because of complex road geometry, or simply because it is raining? To resolve this, we establish navdream, a high-fidelity robustness benchmark leveraging generative pixel-aligned style transfer. By creating a visual stress test with negligible geometric deviation, we isolate the impact of appearance on driving performance. Our evaluation reveals that existing planning algorithms often show significant degradation under OOD appearance conditions, even when the underlying scene structure remains consistent. To bridge this gap, we propose a universal perception interface leveraging a frozen visual foundation model (DINOv3). By extracting appearance-invariant features as a stable interface for the planner, we achieve exceptional zero-shot generalization across diverse planning paradigms, including regression-based, diffusion-based, and scoring-based models. Our plug-and-play solution maintains consistent performance across extreme appearance shifts without requiring further fine-tuning. The benchmark and code will be made available.
ReRoPE: Repurposing RoPE for Relative Camera Control
Feb 08, 2026Video generation with controllable camera viewpoints is essential for applications such as interactive content creation, gaming, and simulation. Existing methods typically adapt pre-trained video models using camera poses relative to a fixed reference, e.g., the first frame. However, these encodings lack shift-invariance, often leading to poor generalization and accumulated drift. While relative camera pose embeddings defined between arbitrary view pairs offer a more robust alternative, integrating them into pre-trained video diffusion models without prohibitive training costs or architectural changes remains challenging. We introduce ReRoPE, a plug-and-play framework that incorporates relative camera information into pre-trained video diffusion models without compromising their generation capability. Our approach is based on the insight that Rotary Positional Embeddings (RoPE) in existing models underutilize their full spectral bandwidth, particularly in the low-frequency components. By seamlessly injecting relative camera pose information into these underutilized bands, ReRoPE achieves precise control while preserving strong pre-trained generative priors. We evaluate our method on both image-to-video (I2V) and video-to-video (V2V) tasks in terms of camera control accuracy and visual fidelity. Our results demonstrate that ReRoPE offers a training-efficient path toward controllable, high-fidelity video generation. See project page for more results: https://sisyphe-lee.github.io/ReRoPE/
ScenDi: 3D-to-2D Scene Diffusion Cascades for Urban Generation
Jan 21, 2026Recent advancements in 3D object generation using diffusion models have achieved remarkable success, but generating realistic 3D urban scenes remains challenging. Existing methods relying solely on 3D diffusion models tend to suffer a degradation in appearance details, while those utilizing only 2D diffusion models typically compromise camera controllability. To overcome this limitation, we propose ScenDi, a method for urban scene generation that integrates both 3D and 2D diffusion models. We first train a 3D latent diffusion model to generate 3D Gaussians, enabling the rendering of images at a relatively low resolution. To enable controllable synthesis, this 3DGS generation process can be optionally conditioned by specifying inputs such as 3d bounding boxes, road maps, or text prompts. Then, we train a 2D video diffusion model to enhance appearance details conditioned on rendered images from the 3D Gaussians. By leveraging the coarse 3D scene as guidance for 2D video diffusion, ScenDi generates desired scenes based on input conditions and successfully adheres to accurate camera trajectories. Experiments on two challenging real-world datasets, Waymo and KITTI-360, demonstrate the effectiveness of our approach.
Towards Depth Foundation Model: Recent Trends in Vision-Based Depth Estimation
Jul 15, 2025Depth estimation is a fundamental task in 3D computer vision, crucial for applications such as 3D reconstruction, free-viewpoint rendering, robotics, autonomous driving, and AR/VR technologies. Traditional methods relying on hardware sensors like LiDAR are often limited by high costs, low resolution, and environmental sensitivity, limiting their applicability in real-world scenarios. Recent advances in vision-based methods offer a promising alternative, yet they face challenges in generalization and stability due to either the low-capacity model architectures or the reliance on domain-specific and small-scale datasets. The emergence of scaling laws and foundation models in other domains has inspired the development of "depth foundation models": deep neural networks trained on large datasets with strong zero-shot generalization capabilities. This paper surveys the evolution of deep learning architectures and paradigms for depth estimation across the monocular, stereo, multi-view, and monocular video settings. We explore the potential of these models to address existing challenges and provide a comprehensive overview of large-scale datasets that can facilitate their development. By identifying key architectures and training strategies, we aim to highlight the path towards robust depth foundation models, offering insights into their future research and applications.
Prometheus: 3D-Aware Latent Diffusion Models for Feed-Forward Text-to-3D Scene Generation
Dec 30, 2024In this work, we introduce Prometheus, a 3D-aware latent diffusion model for text-to-3D generation at both object and scene levels in seconds. We formulate 3D scene generation as multi-view, feed-forward, pixel-aligned 3D Gaussian generation within the latent diffusion paradigm. To ensure generalizability, we build our model upon pre-trained text-to-image generation model with only minimal adjustments, and further train it using a large number of images from both single-view and multi-view datasets. Furthermore, we introduce an RGB-D latent space into 3D Gaussian generation to disentangle appearance and geometry information, enabling efficient feed-forward generation of 3D Gaussians with better fidelity and geometry. Extensive experimental results demonstrate the effectiveness of our method in both feed-forward 3D Gaussian reconstruction and text-to-3D generation. Project page: https://freemty.github.io/project-prometheus/
Learning Temporally Consistent Video Depth from Video Diffusion Priors
Jun 04, 2024This work addresses the challenge of video depth estimation, which expects not only per-frame accuracy but, more importantly, cross-frame consistency. Instead of directly developing a depth estimator from scratch, we reformulate the prediction task into a conditional generation problem. This allows us to leverage the prior knowledge embedded in existing video generation models, thereby reducing learning difficulty and enhancing generalizability. Concretely, we study how to tame the public Stable Video Diffusion (SVD) to predict reliable depth from input videos using a mixture of image depth and video depth datasets. We empirically confirm that a procedural training strategy -- first optimizing the spatial layers of SVD and then optimizing the temporal layers while keeping the spatial layers frozen -- yields the best results in terms of both spatial accuracy and temporal consistency. We further examine the sliding window strategy for inference on arbitrarily long videos. Our observations indicate a trade-off between efficiency and performance, with a one-frame overlap already producing favorable results. Extensive experimental results demonstrate the superiority of our approach, termed ChronoDepth, over existing alternatives, particularly in terms of the temporal consistency of the estimated depth. Additionally, we highlight the benefits of more consistent video depth in two practical applications: depth-conditioned video generation and novel view synthesis. Our project page is available at https://jhaoshao.github.io/ChronoDepth/.
HUGS: Holistic Urban 3D Scene Understanding via Gaussian Splatting
Mar 19, 2024



Holistic understanding of urban scenes based on RGB images is a challenging yet important problem. It encompasses understanding both the geometry and appearance to enable novel view synthesis, parsing semantic labels, and tracking moving objects. Despite considerable progress, existing approaches often focus on specific aspects of this task and require additional inputs such as LiDAR scans or manually annotated 3D bounding boxes. In this paper, we introduce a novel pipeline that utilizes 3D Gaussian Splatting for holistic urban scene understanding. Our main idea involves the joint optimization of geometry, appearance, semantics, and motion using a combination of static and dynamic 3D Gaussians, where moving object poses are regularized via physical constraints. Our approach offers the ability to render new viewpoints in real-time, yielding 2D and 3D semantic information with high accuracy, and reconstruct dynamic scenes, even in scenarios where 3D bounding box detection are highly noisy. Experimental results on KITTI, KITTI-360, and Virtual KITTI 2 demonstrate the effectiveness of our approach.
Defending Against Adversarial Attack in ECG Classification with Adversarial Distillation Training
Mar 14, 2022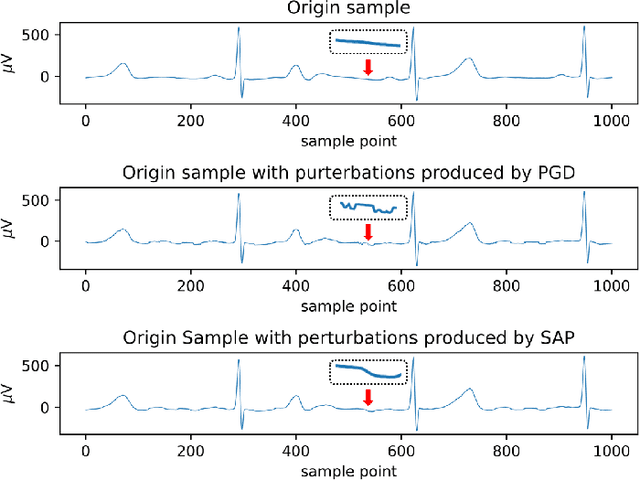
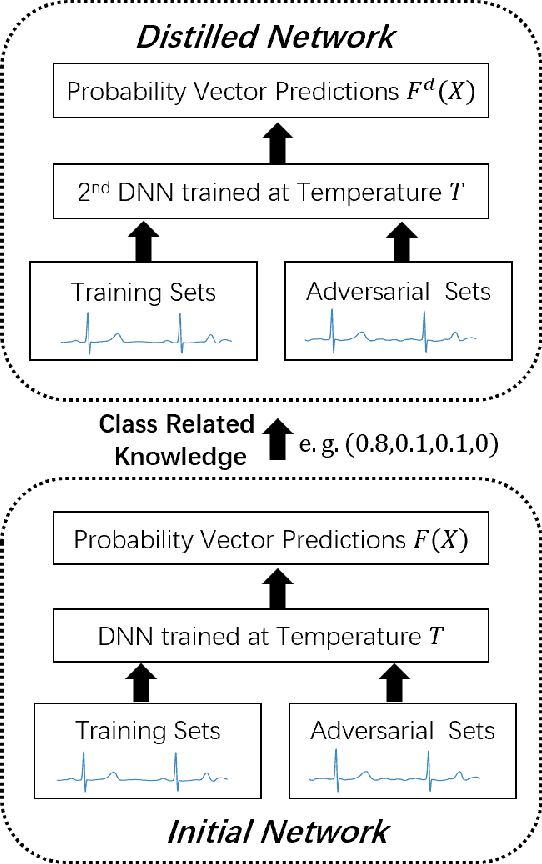
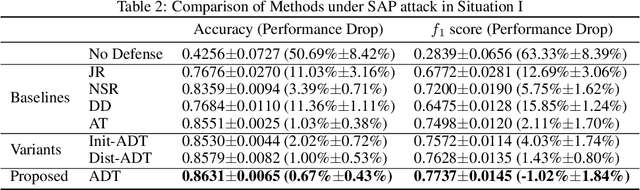
In clinics, doctors rely on electrocardiograms (ECGs) to assess severe cardiac disorders. Owing to the development of technology and the increase in health awareness, ECG signals are currently obtained by using medical and commercial devices. Deep neural networks (DNNs) can be used to analyze these signals because of their high accuracy rate. However, researchers have found that adversarial attacks can significantly reduce the accuracy of DNNs. Studies have been conducted to defend ECG-based DNNs against traditional adversarial attacks, such as projected gradient descent (PGD), and smooth adversarial perturbation (SAP) which targets ECG classification; however, to the best of our knowledge, no study has completely explored the defense against adversarial attacks targeting ECG classification. Thus, we did different experiments to explore the effects of defense methods against white-box adversarial attack and black-box adversarial attack targeting ECG classification, and we found that some common defense methods performed well against these attacks. Besides, we proposed a new defense method called Adversarial Distillation Training (ADT) which comes from defensive distillation and can effectively improve the generalization performance of DNNs. The results show that our method performed more effectively against adversarial attacks targeting on ECG classification than the other baseline methods, namely, adversarial training, defensive distillation, Jacob regularization, and noise-to-signal ratio regularization. Furthermore, we found that our method performed better against PGD attacks with low noise levels, which means that our method has stronger robustness.