 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProject Imaging-X: A Survey of 1000+ Open-Access Medical Imaging Datasets for Foundation Model Development
Mar 29, 2026Foundation models have demonstrated remarkable success across diverse domains and tasks, primarily due to the thrive of large-scale, diverse, and high-quality datasets. However, in the field of medical imaging, the curation and assembling of such medical datasets are highly challenging due to the reliance on clinical expertise and strict ethical and privacy constraints, resulting in a scarcity of large-scale unified medical datasets and hindering the development of powerful medical foundation models. In this work, we present the largest survey to date of medical image datasets, covering over 1,000 open-access datasets with a systematic catalog of their modalities, tasks, anatomies, annotations, limitations, and potential for integration. Our analysis exposes a landscape that is modest in scale, fragmented across narrowly scoped tasks, and unevenly distributed across organs and modalities, which in turn limits the utility of existing medical image datasets for developing versatile and robust medical foundation models. To turn fragmentation into scale, we propose a metadata-driven fusion paradigm (MDFP) that integrates public datasets with shared modalities or tasks, thereby transforming multiple small data silos into larger, more coherent resources. Building on MDFP, we release an interactive discovery portal that enables end-to-end, automated medical image dataset integration, and compile all surveyed datasets into a unified, structured table that clearly summarizes their key characteristics and provides reference links, offering the community an accessible and comprehensive repository. By charting the current terrain and offering a principled path to dataset consolidation, our survey provides a practical roadmap for scaling medical imaging corpora, supporting faster data discovery, more principled dataset creation, and more capable medical foundation models.
The Constant Eye: Benchmarking and Bridging Appearance Robustness in Autonomous Driving
Feb 13, 2026Despite rapid progress, autonomous driving algorithms remain notoriously fragile under Out-of-Distribution (OOD) conditions. We identify a critical decoupling failure in current research: the lack of distinction between appearance-based shifts, such as weather and lighting, and structural scene changes. This leaves a fundamental question unanswered: Is the planner failing because of complex road geometry, or simply because it is raining? To resolve this, we establish navdream, a high-fidelity robustness benchmark leveraging generative pixel-aligned style transfer. By creating a visual stress test with negligible geometric deviation, we isolate the impact of appearance on driving performance. Our evaluation reveals that existing planning algorithms often show significant degradation under OOD appearance conditions, even when the underlying scene structure remains consistent. To bridge this gap, we propose a universal perception interface leveraging a frozen visual foundation model (DINOv3). By extracting appearance-invariant features as a stable interface for the planner, we achieve exceptional zero-shot generalization across diverse planning paradigms, including regression-based, diffusion-based, and scoring-based models. Our plug-and-play solution maintains consistent performance across extreme appearance shifts without requiring further fine-tuning. The benchmark and code will be made available.
Step 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters
Feb 11, 2026We introduce Step 3.5 Flash, a sparse Mixture-of-Experts (MoE) model that bridges frontier-level agentic intelligence and computational efficiency. We focus on what matters most when building agents: sharp reasoning and fast, reliable execution. Step 3.5 Flash pairs a 196B-parameter foundation with 11B active parameters for efficient inference. It is optimized with interleaved 3:1 sliding-window/full attention and Multi-Token Prediction (MTP-3) to reduce the latency and cost of multi-round agentic interactions. To reach frontier-level intelligence, we design a scalable reinforcement learning framework that combines verifiable signals with preference feedback, while remaining stable under large-scale off-policy training, enabling consistent self-improvement across mathematics, code, and tool use. Step 3.5 Flash demonstrates strong performance across agent, coding, and math tasks, achieving 85.4% on IMO-AnswerBench, 86.4% on LiveCodeBench-v6 (2024.08-2025.05), 88.2% on tau2-Bench, 69.0% on BrowseComp (with context management), and 51.0% on Terminal-Bench 2.0, comparable to frontier models such as GPT-5.2 xHigh and Gemini 3.0 Pro. By redefining the efficiency frontier, Step 3.5 Flash provides a high-density foundation for deploying sophisticated agents in real-world industrial environments.
ReRoPE: Repurposing RoPE for Relative Camera Control
Feb 08, 2026Video generation with controllable camera viewpoints is essential for applications such as interactive content creation, gaming, and simulation. Existing methods typically adapt pre-trained video models using camera poses relative to a fixed reference, e.g., the first frame. However, these encodings lack shift-invariance, often leading to poor generalization and accumulated drift. While relative camera pose embeddings defined between arbitrary view pairs offer a more robust alternative, integrating them into pre-trained video diffusion models without prohibitive training costs or architectural changes remains challenging. We introduce ReRoPE, a plug-and-play framework that incorporates relative camera information into pre-trained video diffusion models without compromising their generation capability. Our approach is based on the insight that Rotary Positional Embeddings (RoPE) in existing models underutilize their full spectral bandwidth, particularly in the low-frequency components. By seamlessly injecting relative camera pose information into these underutilized bands, ReRoPE achieves precise control while preserving strong pre-trained generative priors. We evaluate our method on both image-to-video (I2V) and video-to-video (V2V) tasks in terms of camera control accuracy and visual fidelity. Our results demonstrate that ReRoPE offers a training-efficient path toward controllable, high-fidelity video generation. See project page for more results: https://sisyphe-lee.github.io/ReRoPE/
FreeFix: Boosting 3D Gaussian Splatting via Fine-Tuning-Free Diffusion Models
Jan 28, 2026Neural Radiance Fields and 3D Gaussian Splatting have advanced novel view synthesis, yet still rely on dense inputs and often degrade at extrapolated views. Recent approaches leverage generative models, such as diffusion models, to provide additional supervision, but face a trade-off between generalization and fidelity: fine-tuning diffusion models for artifact removal improves fidelity but risks overfitting, while fine-tuning-free methods preserve generalization but often yield lower fidelity. We introduce FreeFix, a fine-tuning-free approach that pushes the boundary of this trade-off by enhancing extrapolated rendering with pretrained image diffusion models. We present an interleaved 2D-3D refinement strategy, showing that image diffusion models can be leveraged for consistent refinement without relying on costly video diffusion models. Furthermore, we take a closer look at the guidance signal for 2D refinement and propose a per-pixel confidence mask to identify uncertain regions for targeted improvement. Experiments across multiple datasets show that FreeFix improves multi-frame consistency and achieves performance comparable to or surpassing fine-tuning-based methods, while retaining strong generalization ability.
STEP3-VL-10B Technical Report
Jan 15, 2026We present STEP3-VL-10B, a lightweight open-source foundation model designed to redefine the trade-off between compact efficiency and frontier-level multimodal intelligence. STEP3-VL-10B is realized through two strategic shifts: first, a unified, fully unfrozen pre-training strategy on 1.2T multimodal tokens that integrates a language-aligned Perception Encoder with a Qwen3-8B decoder to establish intrinsic vision-language synergy; and second, a scaled post-training pipeline featuring over 1k iterations of reinforcement learning. Crucially, we implement Parallel Coordinated Reasoning (PaCoRe) to scale test-time compute, allocating resources to scalable perceptual reasoning that explores and synthesizes diverse visual hypotheses. Consequently, despite its compact 10B footprint, STEP3-VL-10B rivals or surpasses models 10$\times$-20$\times$ larger (e.g., GLM-4.6V-106B, Qwen3-VL-235B) and top-tier proprietary flagships like Gemini 2.5 Pro and Seed-1.5-VL. Delivering best-in-class performance, it records 92.2% on MMBench and 80.11% on MMMU, while excelling in complex reasoning with 94.43% on AIME2025 and 75.95% on MathVision. We release the full model suite to provide the community with a powerful, efficient, and reproducible baseline.
PaCoRe: Learning to Scale Test-Time Compute with Parallel Coordinated Reasoning
Jan 09, 2026We introduce Parallel Coordinated Reasoning (PaCoRe), a training-and-inference framework designed to overcome a central limitation of contemporary language models: their inability to scale test-time compute (TTC) far beyond sequential reasoning under a fixed context window. PaCoRe departs from the traditional sequential paradigm by driving TTC through massive parallel exploration coordinated via a message-passing architecture in multiple rounds. Each round launches many parallel reasoning trajectories, compacts their findings into context-bounded messages, and synthesizes these messages to guide the next round and ultimately produce the final answer. Trained end-to-end with large-scale, outcome-based reinforcement learning, the model masters the synthesis abilities required by PaCoRe and scales to multi-million-token effective TTC without exceeding context limits. The approach yields strong improvements across diverse domains, and notably pushes reasoning beyond frontier systems in mathematics: an 8B model reaches 94.5% on HMMT 2025, surpassing GPT-5's 93.2% by scaling effective TTC to roughly two million tokens. We open-source model checkpoints, training data, and the full inference pipeline to accelerate follow-up work.
Feature-based Inversion of 2.5D Controlled Source Electromagnetic Data using Generative Priors
Jan 05, 2026In this study, we investigate feature-based 2.5D controlled source marine electromagnetic (mCSEM) data inversion using generative priors. Two-and-half dimensional modeling using finite difference method (FDM) is adopted to compute the response of horizontal electric dipole (HED) excitation. Rather than using a neural network to approximate the entire inverse mapping in a black-box manner, we adopt a plug-andplay strategy in which a variational autoencoder (VAE) is used solely to learn prior information on conductivity distributions. During the inversion process, the conductivity model is iteratively updated using the Gauss Newton method, while the model space is constrained by projections onto the learned VAE decoder. This framework preserves explicit control over data misfit and enables flexible adaptation to different survey configurations. Numerical and field experiments demonstrate that the proposed approach effectively incorporates prior information, improves reconstruction accuracy, and exhibits good generalization performance.
Hazard-Responsive Digital Twin for Climate-Driven Urban Resilience and Equity
Oct 27, 2025Compounding climate hazards, such as wildfire-induced outages and urban heatwaves, challenge the stability and equity of cities. We present a Hazard-Responsive Digital Twin (H-RDT) that combines physics-informed neural network modeling, multimodal data fusion, and equity-aware risk analytics for urban-scale response. In a synthetic district with diverse building archetypes and populations, a simulated wildfire-outage-heatwave cascade shows that H-RDT maintains stable indoor temperature predictions (approximately 31 to 33 C) under partial sensor loss, reproducing outage-driven surges and recovery. The reinforcement learning based fusion module adaptively reweights IoT, UAV, and satellite inputs to sustain spatiotemporal coverage, while the equity-adjusted mapping isolates high-vulnerability clusters (schools, clinics, low-income housing). Prospective interventions, such as preemptive cooling-center activation and microgrid sharing, reduce population-weighted thermal risk by 11 to 13 percent, shrink the 95th-percentile (tail) risk by 7 to 17 percent, and cut overheating hours by up to 9 percent. Beyond the synthetic demonstration, the framework establishes a transferable foundation for real-city implementation, linking physical hazard modeling with social equity and decision intelligence. The H-RDT advances digital urban resilience toward adaptive, learning-based, and equity-centered decision support for climate adaptation.
Does Multimodality Improve Recommender Systems as Expected? A Critical Analysis and Future Directions
Aug 07, 2025
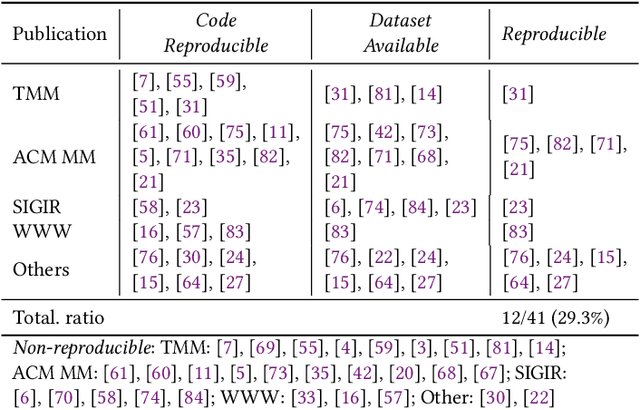
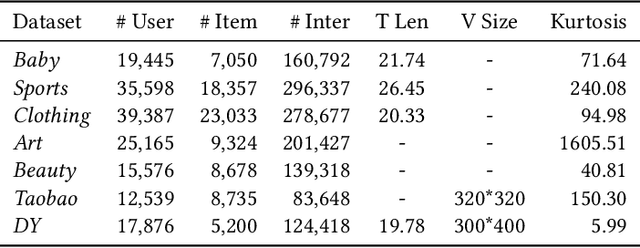
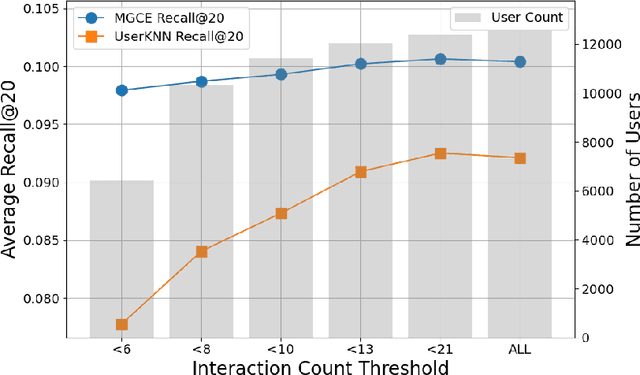
Multimodal recommendation systems are increasingly popular for their potential to improve performance by integrating diverse data types. However, the actual benefits of this integration remain unclear, raising questions about when and how it truly enhances recommendations. In this paper, we propose a structured evaluation framework to systematically assess multimodal recommendations across four dimensions: Comparative Efficiency, Recommendation Tasks, Recommendation Stages, and Multimodal Data Integration. We benchmark a set of reproducible multimodal models against strong traditional baselines and evaluate their performance on different platforms. Our findings show that multimodal data is particularly beneficial in sparse interaction scenarios and during the recall stage of recommendation pipelines. We also observe that the importance of each modality is task-specific, where text features are more useful in e-commerce and visual features are more effective in short-video recommendations. Additionally, we explore different integration strategies and model sizes, finding that Ensemble-Based Learning outperforms Fusion-Based Learning, and that larger models do not necessarily deliver better results. To deepen our understanding, we include case studies and review findings from other recommendation domains. Our work provides practical insights for building efficient and effective multimodal recommendation systems, emphasizing the need for thoughtful modality selection, integration strategies, and model design.