 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStep-Audio 2 Technical Report
Jul 24, 2025



This paper presents Step-Audio 2, an end-to-end multi-modal large language model designed for industry-strength audio understanding and speech conversation. By integrating a latent audio encoder and reasoning-centric reinforcement learning (RL), Step-Audio 2 achieves promising performance in automatic speech recognition (ASR) and audio understanding. To facilitate genuine end-to-end speech conversation, Step-Audio 2 incorporates the generation of discrete audio tokens into language modeling, significantly enhancing its responsiveness to paralinguistic information such as speaking styles and emotions. To effectively leverage the rich textual and acoustic knowledge in real-world data, Step-Audio 2 integrates retrieval-augmented generation (RAG) and is able to call external tools such as web search to mitigate hallucination and audio search to switch timbres. Trained on millions of hours of speech and audio data, Step-Audio 2 delivers intelligence and expressiveness across diverse conversational scenarios. Evaluation results demonstrate that Step-Audio 2 achieves state-of-the-art performance on various audio understanding and conversational benchmarks compared to other open-source and commercial solutions. Please visit https://github.com/stepfun-ai/Step-Audio2 for more information.
Step-Audio-AQAA: a Fully End-to-End Expressive Large Audio Language Model
Jun 10, 2025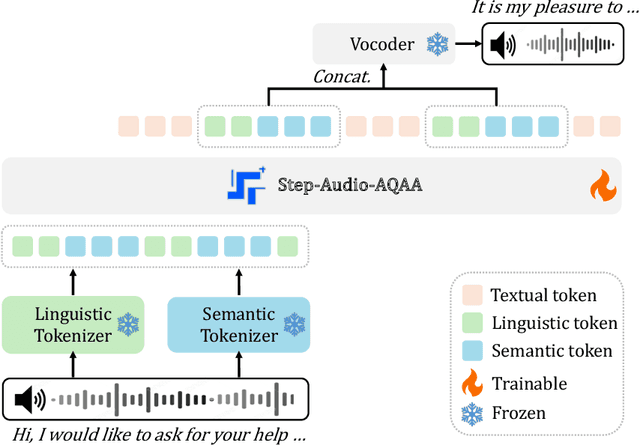
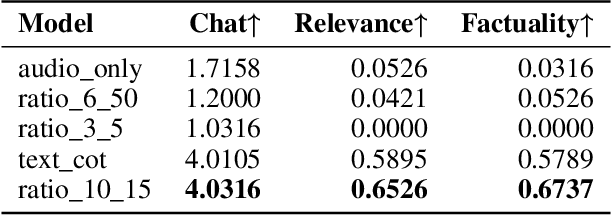
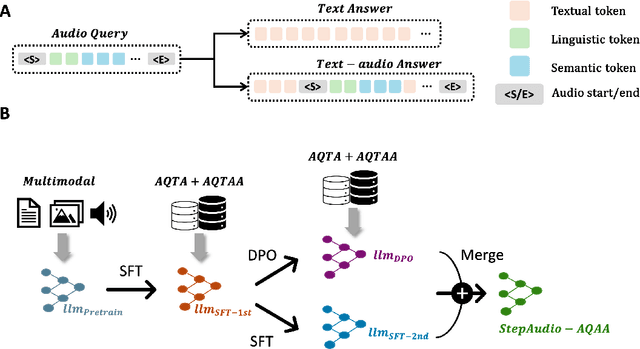

Large Audio-Language Models (LALMs) have significantly advanced intelligent human-computer interaction, yet their reliance on text-based outputs limits their ability to generate natural speech responses directly, hindering seamless audio interactions. To address this, we introduce Step-Audio-AQAA, a fully end-to-end LALM designed for Audio Query-Audio Answer (AQAA) tasks. The model integrates a dual-codebook audio tokenizer for linguistic and semantic feature extraction, a 130-billion-parameter backbone LLM and a neural vocoder for high-fidelity speech synthesis. Our post-training approach employs interleaved token-output of text and audio to enhance semantic coherence and combines Direct Preference Optimization (DPO) with model merge to improve performance. Evaluations on the StepEval-Audio-360 benchmark demonstrate that Step-Audio-AQAA excels especially in speech control, outperforming the state-of-art LALMs in key areas. This work contributes a promising solution for end-to-end LALMs and highlights the critical role of token-based vocoder in enhancing overall performance for AQAA tasks.
StreamRL: Scalable, Heterogeneous, and Elastic RL for LLMs with Disaggregated Stream Generation
Apr 22, 2025Reinforcement learning (RL) has become the core post-training technique for large language models (LLMs). RL for LLMs involves two stages: generation and training. The LLM first generates samples online, which are then used to derive rewards for training. The conventional view holds that the colocated architecture, where the two stages share resources via temporal multiplexing, outperforms the disaggregated architecture, in which dedicated resources are assigned to each stage. However, in real-world deployments, we observe that the colocated architecture suffers from resource coupling, where the two stages are constrained to use the same resources. This coupling compromises the scalability and cost-efficiency of colocated RL in large-scale training. In contrast, the disaggregated architecture allows for flexible resource allocation, supports heterogeneous training setups, and facilitates cross-datacenter deployment. StreamRL is designed with disaggregation from first principles and fully unlocks its potential by addressing two types of performance bottlenecks in existing disaggregated RL frameworks: pipeline bubbles, caused by stage dependencies, and skewness bubbles, resulting from long-tail output length distributions. To address pipeline bubbles, StreamRL breaks the traditional stage boundary in synchronous RL algorithms through stream generation and achieves full overlapping in asynchronous RL. To address skewness bubbles, StreamRL employs an output-length ranker model to identify long-tail samples and reduces generation time via skewness-aware dispatching and scheduling. Experiments show that StreamRL improves throughput by up to 2.66x compared to existing state-of-the-art systems, and improves cost-effectiveness by up to 1.33x in a heterogeneous, cross-datacenter setting.
PipeWeaver: Addressing Data Dynamicity in Large Multimodal Model Training with Dynamic Interleaved Pipeline
Apr 19, 2025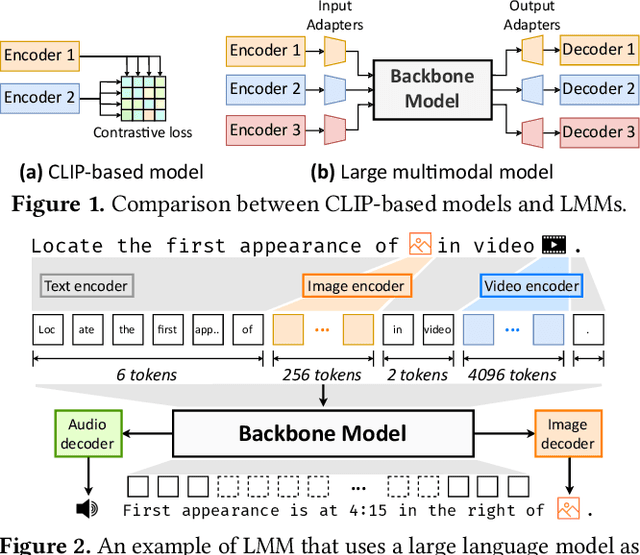
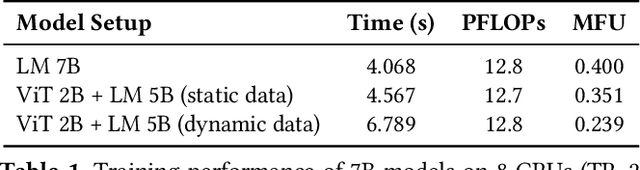


Large multimodal models (LMMs) have demonstrated excellent capabilities in both understanding and generation tasks with various modalities. While these models can accept flexible combinations of input data, their training efficiency suffers from two major issues: pipeline stage imbalance caused by heterogeneous model architectures, and training data dynamicity stemming from the diversity of multimodal data. In this paper, we present PipeWeaver, a dynamic pipeline scheduling framework designed for LMM training. The core of PipeWeaver is dynamic interleaved pipeline, which searches for pipeline schedules dynamically tailored to current training batches. PipeWeaver addresses issues of LMM training with two techniques: adaptive modality-aware partitioning and efficient pipeline schedule search within a hierarchical schedule space. Meanwhile, PipeWeaver utilizes SEMU (Step Emulator), a training simulator for multimodal models, for accurate performance estimations, accelerated by spatial-temporal subgraph reuse to improve search efficiency. Experiments show that PipeWeaver can enhance LMM training efficiency by up to 97.3% compared to state-of-the-art systems, and demonstrate excellent adaptivity to LMM training's data dynamicity.
Step-Audio: Unified Understanding and Generation in Intelligent Speech Interaction
Feb 18, 2025Real-time speech interaction, serving as a fundamental interface for human-machine collaboration, holds immense potential. However, current open-source models face limitations such as high costs in voice data collection, weakness in dynamic control, and limited intelligence. To address these challenges, this paper introduces Step-Audio, the first production-ready open-source solution. Key contributions include: 1) a 130B-parameter unified speech-text multi-modal model that achieves unified understanding and generation, with the Step-Audio-Chat version open-sourced; 2) a generative speech data engine that establishes an affordable voice cloning framework and produces the open-sourced lightweight Step-Audio-TTS-3B model through distillation; 3) an instruction-driven fine control system enabling dynamic adjustments across dialects, emotions, singing, and RAP; 4) an enhanced cognitive architecture augmented with tool calling and role-playing abilities to manage complex tasks effectively. Based on our new StepEval-Audio-360 evaluation benchmark, Step-Audio achieves state-of-the-art performance in human evaluations, especially in terms of instruction following. On open-source benchmarks like LLaMA Question, shows 9.3% average performance improvement, demonstrating our commitment to advancing the development of open-source multi-modal language technologies. Our code and models are available at https://github.com/stepfun-ai/Step-Audio.
CDMPP: A Device-Model Agnostic Framework for Latency Prediction of Tensor Programs
Nov 17, 2023
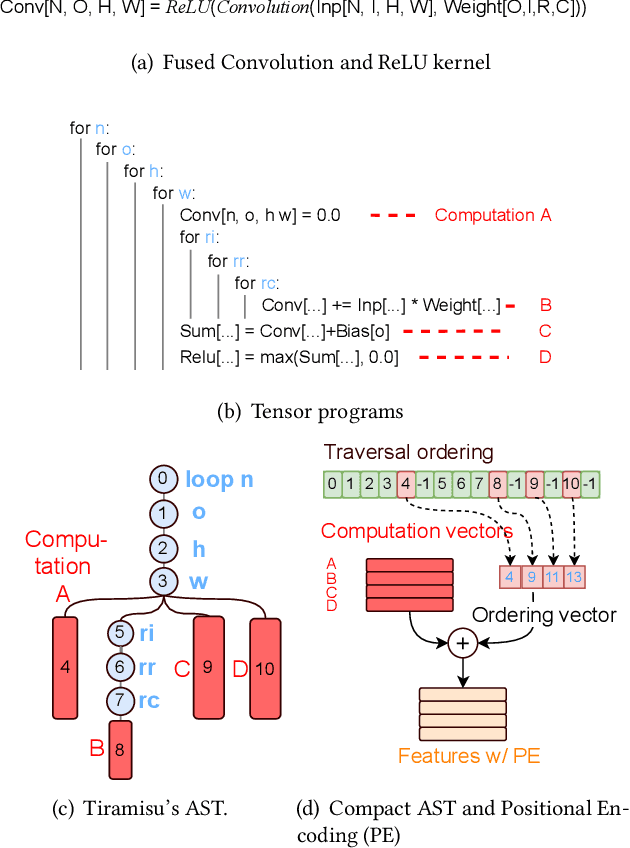
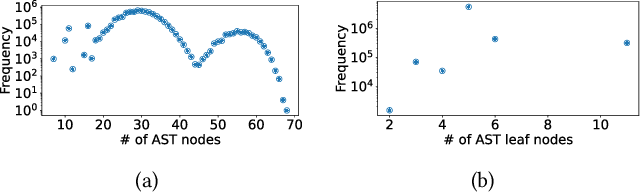
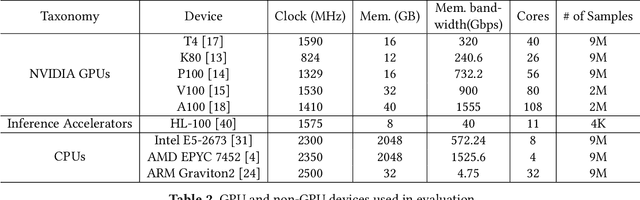
Deep Neural Networks (DNNs) have shown excellent performance in a wide range of machine learning applications. Knowing the latency of running a DNN model or tensor program on a specific device is useful in various tasks, such as DNN graph- or tensor-level optimization and device selection. Considering the large space of DNN models and devices that impede direct profiling of all combinations, recent efforts focus on building a predictor to model the performance of DNN models on different devices. However, none of the existing attempts have achieved a cost model that can accurately predict the performance of various tensor programs while supporting both training and inference accelerators. We propose CDMPP, an efficient tensor program latency prediction framework for both cross-model and cross-device prediction. We design an informative but efficient representation of tensor programs, called compact ASTs, and a pre-order-based positional encoding method, to capture the internal structure of tensor programs. We develop a domain-adaption-inspired method to learn domain-invariant representations and devise a KMeans-based sampling algorithm, for the predictor to learn from different domains (i.e., different DNN operators and devices). Our extensive experiments on a diverse range of DNN models and devices demonstrate that CDMPP significantly outperforms state-of-the-art baselines with 14.03% and 10.85% prediction error for cross-model and cross-device prediction, respectively, and one order of magnitude higher training efficiency. The implementation and the expanded dataset are available at https://github.com/joapolarbear/cdmpp.
* Accepted by EuroSys 2024
dPRO: A Generic Profiling and Optimization System for Expediting Distributed DNN Training
May 18, 2022



Distributed training using multiple devices (e.g., GPUs) has been widely adopted for learning DNN models over large datasets. However, the performance of large-scale distributed training tends to be far from linear speed-up in practice. Given the complexity of distributed systems, it is challenging to identify the root cause(s) of inefficiency and exercise effective performance optimizations when unexpected low training speed occurs. To date, there exists no software tool which diagnoses performance issues and helps expedite distributed DNN training, while the training can be run using different deep learning frameworks. This paper proposes dPRO, a toolkit that includes: (1) an efficient profiler that collects runtime traces of distributed DNN training across multiple frameworks, especially fine-grained communication traces, and constructs global data flow graphs including detailed communication operations for accurate replay; (2) an optimizer that effectively identifies performance bottlenecks and explores optimization strategies (from computation, communication, and memory aspects) for training acceleration. We implement dPRO on multiple deep learning frameworks (TensorFlow, MXNet) and representative communication schemes (AllReduce and Parameter Server). Extensive experiments show that dPRO predicts the performance of distributed training in various settings with < 5% errors in most cases and finds optimization strategies with up to 3.48x speed-up over the baselines.
Distributed Machine Learning through Heterogeneous Edge Systems
Nov 16, 2019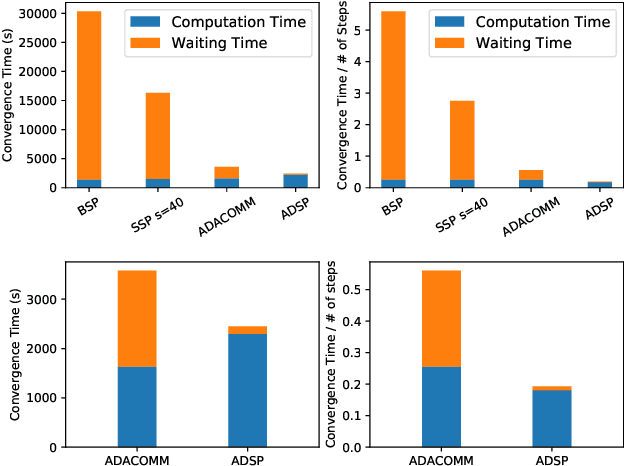
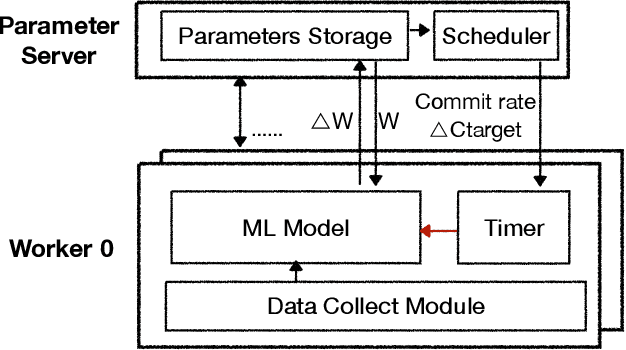
Many emerging AI applications request distributed machine learning (ML) among edge systems (e.g., IoT devices and PCs at the edge of the Internet), where data cannot be uploaded to a central venue for model training, due to their large volumes and/or security/privacy concerns. Edge devices are intrinsically heterogeneous in computing capacity, posing significant challenges to parameter synchronization for parallel training with the parameter server (PS) architecture. This paper proposes ADSP, a parameter synchronization scheme for distributed machine learning (ML) with heterogeneous edge systems. Eliminating the significant waiting time occurring with existing parameter synchronization models, the core idea of ADSP is to let faster edge devices continue training, while committing their model updates at strategically decided intervals. We design algorithms that decide time points for each worker to commit its model update, and ensure not only global model convergence but also faster convergence. Our testbed implementation and experiments show that ADSP outperforms existing parameter synchronization models significantly in terms of ML model convergence time, scalability and adaptability to large heterogeneity.