 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePipeWeaver: Addressing Data Dynamicity in Large Multimodal Model Training with Dynamic Interleaved Pipeline
Paper and Code
Apr 19, 2025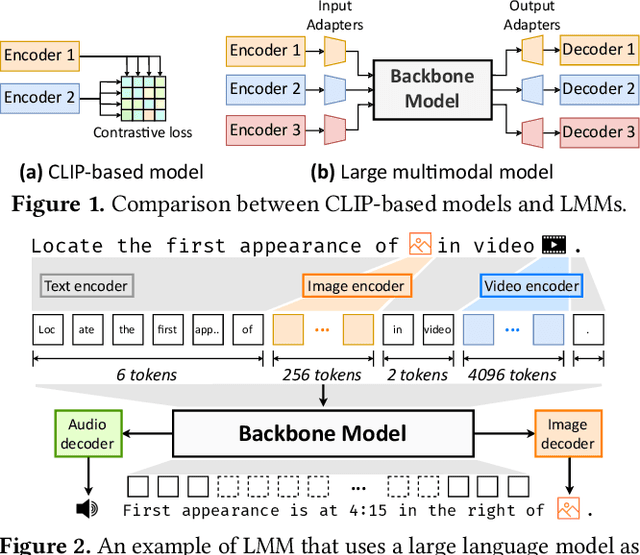
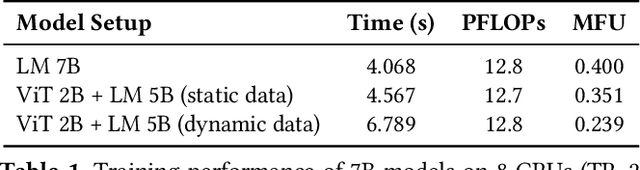


Large multimodal models (LMMs) have demonstrated excellent capabilities in both understanding and generation tasks with various modalities. While these models can accept flexible combinations of input data, their training efficiency suffers from two major issues: pipeline stage imbalance caused by heterogeneous model architectures, and training data dynamicity stemming from the diversity of multimodal data. In this paper, we present PipeWeaver, a dynamic pipeline scheduling framework designed for LMM training. The core of PipeWeaver is dynamic interleaved pipeline, which searches for pipeline schedules dynamically tailored to current training batches. PipeWeaver addresses issues of LMM training with two techniques: adaptive modality-aware partitioning and efficient pipeline schedule search within a hierarchical schedule space. Meanwhile, PipeWeaver utilizes SEMU (Step Emulator), a training simulator for multimodal models, for accurate performance estimations, accelerated by spatial-temporal subgraph reuse to improve search efficiency. Experiments show that PipeWeaver can enhance LMM training efficiency by up to 97.3% compared to state-of-the-art systems, and demonstrate excellent adaptivity to LMM training's data dynamicity.