 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Training: Enabling Self-Evolution of Agents with MOBIMEM
Dec 15, 2025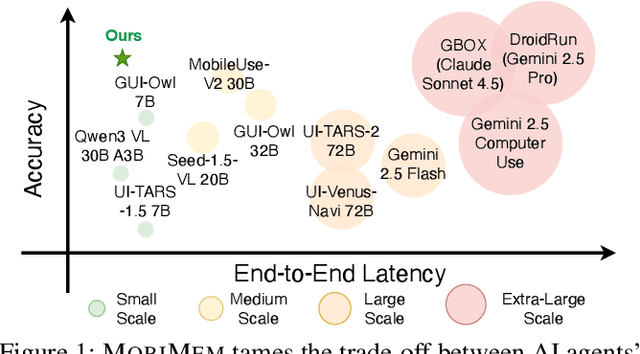
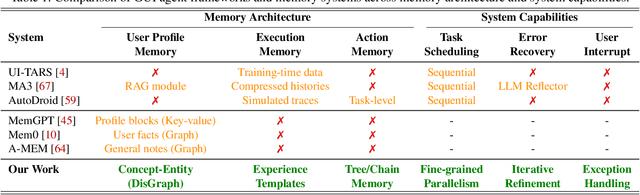
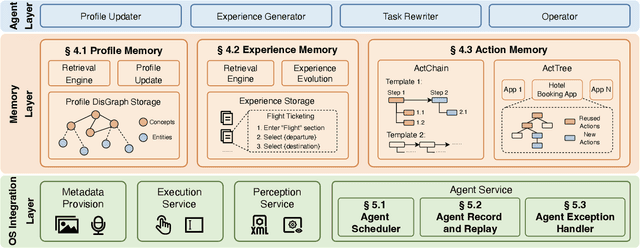
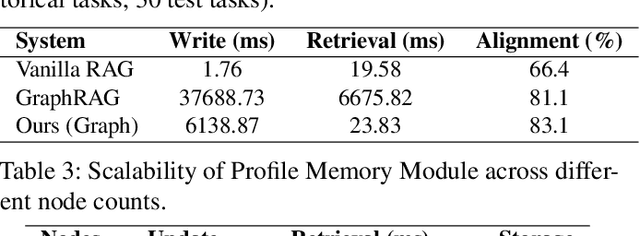
Large Language Model (LLM) agents are increasingly deployed to automate complex workflows in mobile and desktop environments. However, current model-centric agent architectures struggle to self-evolve post-deployment: improving personalization, capability, and efficiency typically requires continuous model retraining/fine-tuning, which incurs prohibitive computational overheads and suffers from an inherent trade-off between model accuracy and inference efficiency. To enable iterative self-evolution without model retraining, we propose MOBIMEM, a memory-centric agent system. MOBIMEM first introduces three specialized memory primitives to decouple agent evolution from model weights: (1) Profile Memory uses a lightweight distance-graph (DisGraph) structure to align with user preferences, resolving the accuracy-latency trade-off in user profile retrieval; (2) Experience Memory employs multi-level templates to instantiate execution logic for new tasks, ensuring capability generalization; and (3) Action Memory records fine-grained interaction sequences, reducing the reliance on expensive model inference. Building upon this memory architecture, MOBIMEM further integrates a suite of OS-inspired services to orchestrate execution: a scheduler that coordinates parallel sub-task execution and memory operations; an agent record-and-replay (AgentRR) mechanism that enables safe and efficient action reuse; and a context-aware exception handling that ensures graceful recovery from user interruptions and runtime errors. Evaluation on AndroidWorld and top-50 apps shows that MOBIMEM achieves 83.1% profile alignment with 23.83 ms retrieval time (280x faster than GraphRAG baselines), improves task success rates by up to 50.3%, and reduces end-to-end latency by up to 9x on mobile devices.
Get Experience from Practice: LLM Agents with Record & Replay
May 23, 2025AI agents, empowered by Large Language Models (LLMs) and communication protocols such as MCP and A2A, have rapidly evolved from simple chatbots to autonomous entities capable of executing complex, multi-step tasks, demonstrating great potential. However, the LLMs' inherent uncertainty and heavy computational resource requirements pose four significant challenges to the development of safe and efficient agents: reliability, privacy, cost and performance. Existing approaches, like model alignment, workflow constraints and on-device model deployment, can partially alleviate some issues but often with limitations, failing to fundamentally resolve these challenges. This paper proposes a new paradigm called AgentRR (Agent Record & Replay), which introduces the classical record-and-replay mechanism into AI agent frameworks. The core idea is to: 1. Record an agent's interaction trace with its environment and internal decision process during task execution, 2. Summarize this trace into a structured "experience" encapsulating the workflow and constraints, and 3. Replay these experiences in subsequent similar tasks to guide the agent's behavior. We detail a multi-level experience abstraction method and a check function mechanism in AgentRR: the former balances experience specificity and generality, while the latter serves as a trust anchor to ensure completeness and safety during replay. In addition, we explore multiple application modes of AgentRR, including user-recorded task demonstration, large-small model collaboration and privacy-aware agent execution, and envision an experience repository for sharing and reusing knowledge to further reduce deployment cost.
L3: DIMM-PIM Integrated Architecture and Coordination for Scalable Long-Context LLM Inference
Apr 24, 2025Large Language Models (LLMs) increasingly require processing long text sequences, but GPU memory limitations force difficult trade-offs between memory capacity and bandwidth. While HBM-based acceleration offers high bandwidth, its capacity remains constrained. Offloading data to host-side DIMMs improves capacity but introduces costly data swapping overhead. We identify that the critical memory bottleneck lies in the decoding phase of multi-head attention (MHA) exclusively, which demands substantial capacity for storing KV caches and high bandwidth for attention computation. Our key insight reveals this operation uniquely aligns with modern DIMM-based processing-in-memory (PIM) architectures, which offers scalability of both capacity and bandwidth. Based on this observation and insight, we propose L3, a hardware-software co-designed system integrating DIMM-PIM and GPU devices. L3 introduces three innovations: First, hardware redesigns resolve data layout mismatches and computational element mismatches in DIMM-PIM, enhancing LLM inference utilization. Second, communication optimization enables hiding the data transfer overhead with the computation. Third, an adaptive scheduler coordinates GPU-DIMM-PIM operations to maximize parallelism between devices. Evaluations using real-world traces show L3 achieves up to 6.1$\times$ speedup over state-of-the-art HBM-PIM solutions while significantly improving batch sizes.
PipeWeaver: Addressing Data Dynamicity in Large Multimodal Model Training with Dynamic Interleaved Pipeline
Apr 19, 2025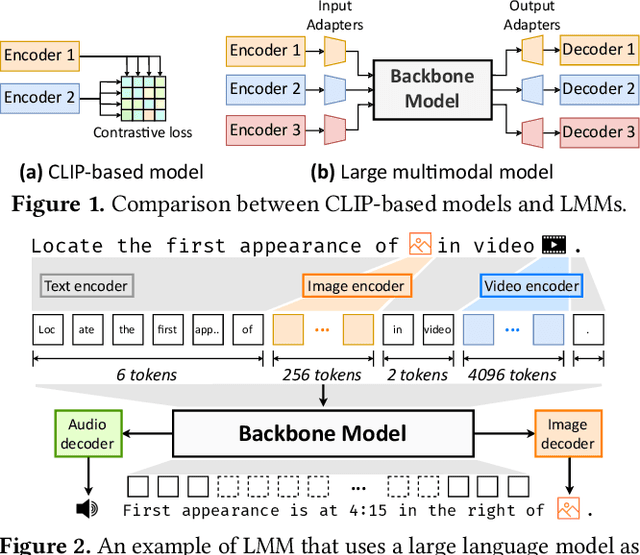
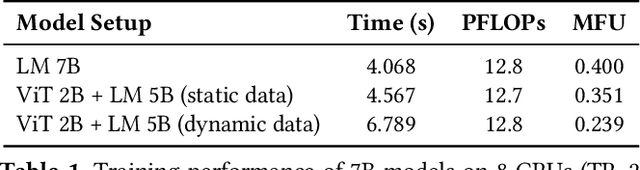


Large multimodal models (LMMs) have demonstrated excellent capabilities in both understanding and generation tasks with various modalities. While these models can accept flexible combinations of input data, their training efficiency suffers from two major issues: pipeline stage imbalance caused by heterogeneous model architectures, and training data dynamicity stemming from the diversity of multimodal data. In this paper, we present PipeWeaver, a dynamic pipeline scheduling framework designed for LMM training. The core of PipeWeaver is dynamic interleaved pipeline, which searches for pipeline schedules dynamically tailored to current training batches. PipeWeaver addresses issues of LMM training with two techniques: adaptive modality-aware partitioning and efficient pipeline schedule search within a hierarchical schedule space. Meanwhile, PipeWeaver utilizes SEMU (Step Emulator), a training simulator for multimodal models, for accurate performance estimations, accelerated by spatial-temporal subgraph reuse to improve search efficiency. Experiments show that PipeWeaver can enhance LMM training efficiency by up to 97.3% compared to state-of-the-art systems, and demonstrate excellent adaptivity to LMM training's data dynamicity.
Streamlining Biomedical Research with Specialized LLMs
Apr 15, 2025In this paper, we propose a novel system that integrates state-of-the-art, domain-specific large language models with advanced information retrieval techniques to deliver comprehensive and context-aware responses. Our approach facilitates seamless interaction among diverse components, enabling cross-validation of outputs to produce accurate, high-quality responses enriched with relevant data, images, tables, and other modalities. We demonstrate the system's capability to enhance response precision by leveraging a robust question-answering model, significantly improving the quality of dialogue generation. The system provides an accessible platform for real-time, high-fidelity interactions, allowing users to benefit from efficient human-computer interaction, precise retrieval, and simultaneous access to a wide range of literature and data. This dramatically improves the research efficiency of professionals in the biomedical and pharmaceutical domains and facilitates faster, more informed decision-making throughout the R\&D process. Furthermore, the system proposed in this paper is available at https://synapse-chat.patsnap.com.
AutoEval: A Practical Framework for Autonomous Evaluation of Mobile Agents
Mar 04, 2025



Accurate and systematic evaluation of mobile agents can significantly advance their development and real-world applicability. However, existing benchmarks for mobile agents lack practicality and scalability due to the extensive manual effort required to define task reward signals and implement corresponding evaluation codes. To this end, we propose AutoEval, an autonomous agent evaluation framework that tests a mobile agent without any manual effort. First, we design a Structured Substate Representation to describe the UI state changes while agent execution, such that task reward signals can be automatically generated. Second, we utilize a Judge System that can autonomously evaluate agents' performance given the automatically generated task reward signals. By providing only a task description, our framework evaluates agents with fine-grained performance feedback to that task without any extra manual effort. We implement a prototype of our framework and validate the automatically generated task reward signals, finding over 93% coverage to human-annotated reward signals. Moreover, to prove the effectiveness of our autonomous Judge System, we manually verify its judge results and demonstrate that it achieves 94% accuracy. Finally, we evaluate the state-of-the-art mobile agents using our framework, providing detailed insights into their performance characteristics and limitations.
PharmaGPT: Domain-Specific Large Language Models for Bio-Pharmaceutical and Chemistry
Jul 03, 2024



Large language models (LLMs) have revolutionized Natural Language Processing (NLP) by by minimizing the need for complex feature engineering. However, the application of LLMs in specialized domains like biopharmaceuticals and chemistry remains largely unexplored. These fields are characterized by intricate terminologies, specialized knowledge, and a high demand for precision areas where general purpose LLMs often fall short. In this study, we introduce PharmGPT, a suite of multilingual LLMs with 13 billion and 70 billion parameters, specifically trained on a comprehensive corpus of hundreds of billions of tokens tailored to the Bio-Pharmaceutical and Chemical sectors. Our evaluation shows that PharmGPT matches or surpasses existing general models on key benchmarks, such as NAPLEX, demonstrating its exceptional capability in domain-specific tasks. This advancement establishes a new benchmark for LLMs in the Bio-Pharmaceutical and Chemical fields, addressing the existing gap in specialized language modeling. Furthermore, this suggests a promising path for enhanced research and development in these specialized areas, paving the way for more precise and effective applications of NLP in specialized domains.
PharmGPT: Domain-Specific Large Language Models for Bio-Pharmaceutical and Chemistry
Jun 26, 2024Large language models (LLMs) have revolutionized Natural Language Processing (NLP) by by minimizing the need for complex feature engineering. However, the application of LLMs in specialized domains like biopharmaceuticals and chemistry remains largely unexplored. These fields are characterized by intricate terminologies, specialized knowledge, and a high demand for precision areas where general purpose LLMs often fall short. In this study, we introduce PharmGPT, a suite of multilingual LLMs with 13 billion and 70 billion parameters, specifically trained on a comprehensive corpus of hundreds of billions of tokens tailored to the Bio-Pharmaceutical and Chemical sectors. Our evaluation shows that PharmGPT matches or surpasses existing general models on key benchmarks, such as NAPLEX, demonstrating its exceptional capability in domain-specific tasks. This advancement establishes a new benchmark for LLMs in the Bio-Pharmaceutical and Chemical fields, addressing the existing gap in specialized language modeling. Furthermore, this suggests a promising path for enhanced research and development in these specialized areas, paving the way for more precise and effective applications of NLP in specialized domains.
PowerInfer-2: Fast Large Language Model Inference on a Smartphone
Jun 12, 2024



This paper introduces PowerInfer-2, a framework designed for high-speed inference of Large Language Models (LLMs) on smartphones, particularly effective for models whose sizes exceed the device's memory capacity. The key insight of PowerInfer-2 is to utilize the heterogeneous computation, memory, and I/O resources in smartphones by decomposing traditional matrix computations into fine-grained neuron cluster computations. Specifically, PowerInfer-2 features a polymorphic neuron engine that adapts computational strategies for various stages of LLM inference. Additionally, it introduces segmented neuron caching and fine-grained neuron-cluster-level pipelining, which effectively minimize and conceal the overhead caused by I/O operations. The implementation and evaluation of PowerInfer-2 demonstrate its capability to support a wide array of LLM models on two smartphones, achieving up to a 29.2x speed increase compared with state-of-the-art frameworks. Notably, PowerInfer-2 is the first system to serve the TurboSparse-Mixtral-47B model with a generation rate of 11.68 tokens per second on a smartphone. For models that fit entirely within the memory, PowerInfer-2 can achieve approximately a 40% reduction in memory usage while maintaining inference speeds comparable to llama.cpp and MLC-LLM. For more details, including a demonstration video, please visit the project site at www.powerinfer.ai/v2.
PatentGPT: A Large Language Model for Intellectual Property
Apr 30, 2024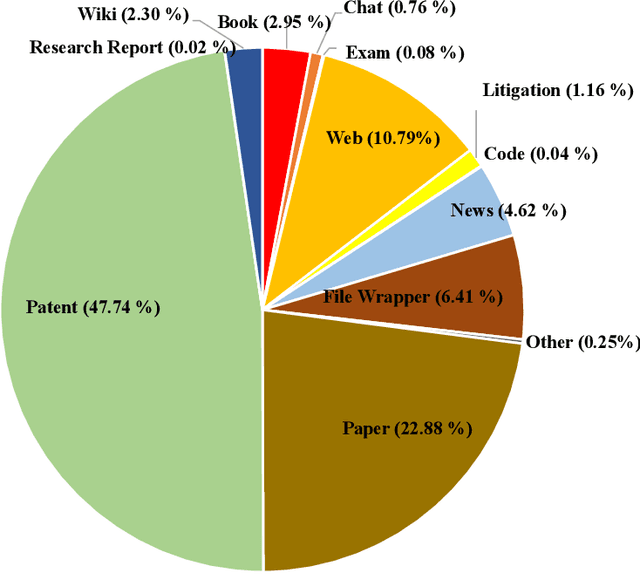

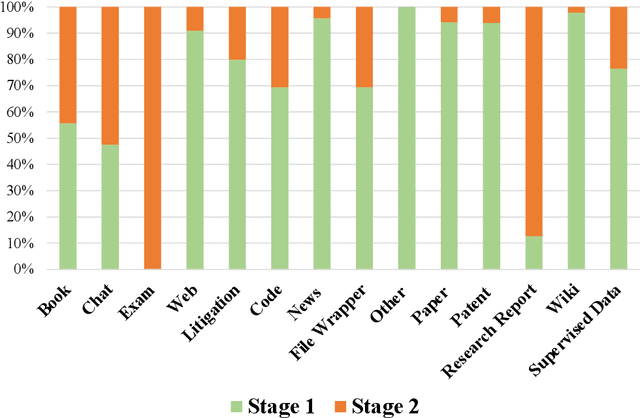
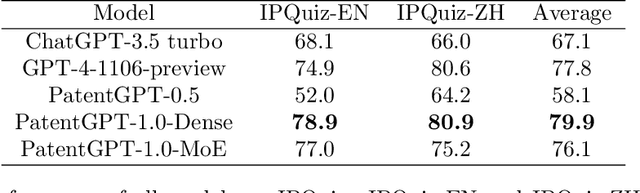
In recent years, large language models have attracted significant attention due to their exceptional performance across a multitude of natural language process tasks, and have been widely applied in various fields. However, the application of large language models in the Intellectual Property (IP) space is challenging due to the strong need for specialized knowledge, privacy protection, processing of extremely long text in this field. In this technical report, we present for the first time a low-cost, standardized procedure for training IP-oriented LLMs, meeting the unique requirements of the IP domain. Using this standard process, we have trained the PatentGPT series models based on open-source pretrained models. By evaluating them on the open-source IP-oriented benchmark MOZIP, our domain-specific LLMs outperforms GPT-4, indicating the effectiveness of the proposed training procedure and the expertise of the PatentGPT models in the IP demain. What is impressive is that our model significantly outperformed GPT-4 on the 2019 China Patent Agent Qualification Examination by achieving a score of 65, reaching the level of human experts. Additionally, the PatentGPT model, which utilizes the SMoE architecture, achieves performance comparable to that of GPT-4 in the IP domain and demonstrates a better cost-performance ratio on long-text tasks, potentially serving as an alternative to GPT-4 within the IP domain.