 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMAE: A Massive Multitask Audio Editing Benchmark
Jun 05, 2026We introduce MMAE, a Massive Multitask Audio Editing benchmark, serving as the first comprehensive evaluation testbed designed for general-purpose instruction-based audio editing. Spurred by the shift toward intelligent creation, interactive editing has rapidly expanded from visual domains, pioneered by models like Nano-banana 2 for images and Gemini-Omni for video, into audio. However, the current evaluation infrastructure lags severely, remaining highly fragmented and restricted to specific subdomains or basic operations. Unlike existing benchmarks that are limited in scope, MMAE extends to a broad spectrum of real-world scenarios, encompassing 7 distinct audio modalities, including sound, speech, music, and their mixtures. Furthermore, we establish a comprehensive taxonomy spanning 6 levels of task complexity, from basic modifications to multi-hop reasoning and multi-round editing, 2 levels of granularity, and 8 distinct operation types. Meticulously curated through human-agent collaboration, MMAE comprises 2,000 high-fidelity samples paired with a pioneering rubric-based evaluation framework. By decomposing free-form tasks into 17,741 verifiable criteria, this robust rubric-based paradigm enables a precise, multi-dimensional assessment of both instruction following and context consistency. Our extensive evaluation of leading models reveals that current systems remain far from achieving reliable edits. Strikingly, the Exact Match Rate (EMR) consistently falls below 5% and plummets to an absolute 0% in complex, mixed-modality tasks, exposing critical bottlenecks in precise execution and structural robustness. We hope MMAE will serve as a catalyst for future advances in the intelligent creation community, providing a clear diagnostic roadmap and establishing a standardized, long-lasting evaluation paradigm for next-generation audio editing systems.
AcademiClaw: When Students Set Challenges for AI Agents
May 04, 2026Benchmarks within the OpenClaw ecosystem have thus far evaluated exclusively assistant-level tasks, leaving the academic-level capabilities of OpenClaw largely unexamined. We introduce AcademiClaw, a bilingual benchmark of 80 complex, long-horizon tasks sourced directly from university students' real academic workflows -- homework, research projects, competitions, and personal projects -- that they found current AI agents unable to solve effectively. Curated from 230 student-submitted candidates through rigorous expert review, the final task set spans 25+ professional domains, ranging from olympiad-level mathematics and linguistics problems to GPU-intensive reinforcement learning and full-stack system debugging, with 16 tasks requiring CUDA GPU execution. Each task executes in an isolated Docker sandbox and is scored on task completion by multi-dimensional rubrics combining six complementary techniques, with an independent five-category safety audit providing additional behavioral analysis. Experiments on six frontier models show that even the best achieves only a 55\% pass rate. Further analysis uncovers sharp capability boundaries across task domains, divergent behavioral strategies among models, and a disconnect between token consumption and output quality, providing fine-grained diagnostic signals beyond what aggregate metrics reveal. We hope that AcademiClaw and its open-sourced data and code can serve as a useful resource for the OpenClaw community, driving progress toward agents that are more capable and versatile across the full breadth of real-world academic demands. All data and code are available at https://github.com/GAIR-NLP/AcademiClaw.
Streamlining Biomedical Research with Specialized LLMs
Apr 15, 2025In this paper, we propose a novel system that integrates state-of-the-art, domain-specific large language models with advanced information retrieval techniques to deliver comprehensive and context-aware responses. Our approach facilitates seamless interaction among diverse components, enabling cross-validation of outputs to produce accurate, high-quality responses enriched with relevant data, images, tables, and other modalities. We demonstrate the system's capability to enhance response precision by leveraging a robust question-answering model, significantly improving the quality of dialogue generation. The system provides an accessible platform for real-time, high-fidelity interactions, allowing users to benefit from efficient human-computer interaction, precise retrieval, and simultaneous access to a wide range of literature and data. This dramatically improves the research efficiency of professionals in the biomedical and pharmaceutical domains and facilitates faster, more informed decision-making throughout the R\&D process. Furthermore, the system proposed in this paper is available at https://synapse-chat.patsnap.com.
PharmaGPT: Domain-Specific Large Language Models for Bio-Pharmaceutical and Chemistry
Jul 03, 2024



Large language models (LLMs) have revolutionized Natural Language Processing (NLP) by by minimizing the need for complex feature engineering. However, the application of LLMs in specialized domains like biopharmaceuticals and chemistry remains largely unexplored. These fields are characterized by intricate terminologies, specialized knowledge, and a high demand for precision areas where general purpose LLMs often fall short. In this study, we introduce PharmGPT, a suite of multilingual LLMs with 13 billion and 70 billion parameters, specifically trained on a comprehensive corpus of hundreds of billions of tokens tailored to the Bio-Pharmaceutical and Chemical sectors. Our evaluation shows that PharmGPT matches or surpasses existing general models on key benchmarks, such as NAPLEX, demonstrating its exceptional capability in domain-specific tasks. This advancement establishes a new benchmark for LLMs in the Bio-Pharmaceutical and Chemical fields, addressing the existing gap in specialized language modeling. Furthermore, this suggests a promising path for enhanced research and development in these specialized areas, paving the way for more precise and effective applications of NLP in specialized domains.
PharmGPT: Domain-Specific Large Language Models for Bio-Pharmaceutical and Chemistry
Jun 26, 2024Large language models (LLMs) have revolutionized Natural Language Processing (NLP) by by minimizing the need for complex feature engineering. However, the application of LLMs in specialized domains like biopharmaceuticals and chemistry remains largely unexplored. These fields are characterized by intricate terminologies, specialized knowledge, and a high demand for precision areas where general purpose LLMs often fall short. In this study, we introduce PharmGPT, a suite of multilingual LLMs with 13 billion and 70 billion parameters, specifically trained on a comprehensive corpus of hundreds of billions of tokens tailored to the Bio-Pharmaceutical and Chemical sectors. Our evaluation shows that PharmGPT matches or surpasses existing general models on key benchmarks, such as NAPLEX, demonstrating its exceptional capability in domain-specific tasks. This advancement establishes a new benchmark for LLMs in the Bio-Pharmaceutical and Chemical fields, addressing the existing gap in specialized language modeling. Furthermore, this suggests a promising path for enhanced research and development in these specialized areas, paving the way for more precise and effective applications of NLP in specialized domains.
PatentGPT: A Large Language Model for Intellectual Property
Apr 30, 2024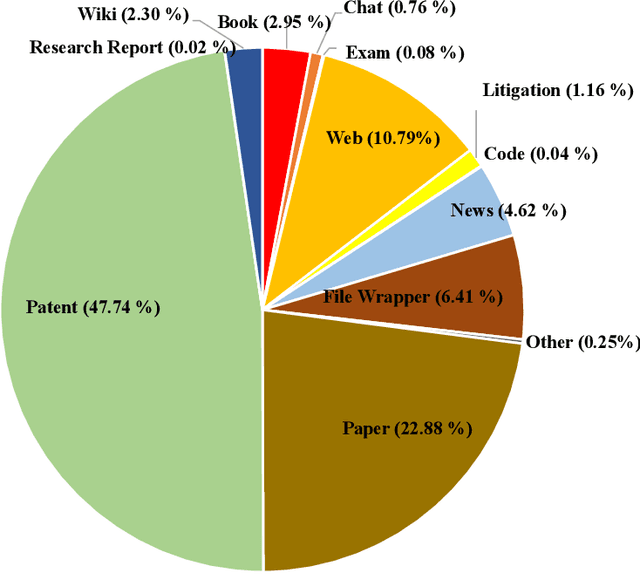

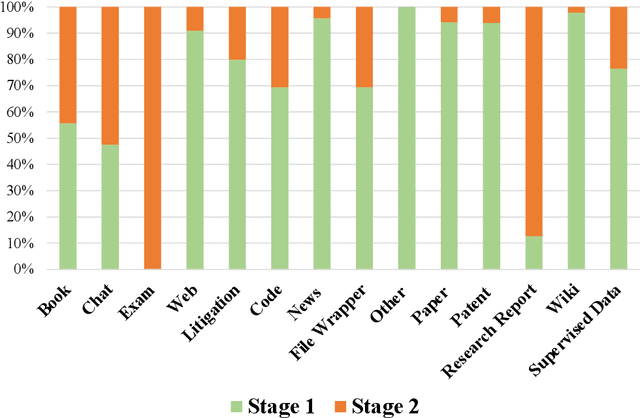
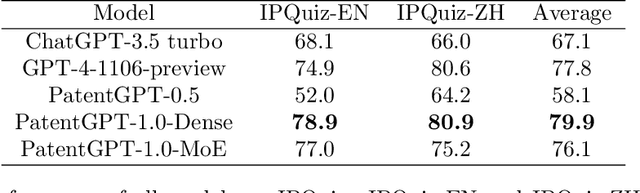
In recent years, large language models have attracted significant attention due to their exceptional performance across a multitude of natural language process tasks, and have been widely applied in various fields. However, the application of large language models in the Intellectual Property (IP) space is challenging due to the strong need for specialized knowledge, privacy protection, processing of extremely long text in this field. In this technical report, we present for the first time a low-cost, standardized procedure for training IP-oriented LLMs, meeting the unique requirements of the IP domain. Using this standard process, we have trained the PatentGPT series models based on open-source pretrained models. By evaluating them on the open-source IP-oriented benchmark MOZIP, our domain-specific LLMs outperforms GPT-4, indicating the effectiveness of the proposed training procedure and the expertise of the PatentGPT models in the IP demain. What is impressive is that our model significantly outperformed GPT-4 on the 2019 China Patent Agent Qualification Examination by achieving a score of 65, reaching the level of human experts. Additionally, the PatentGPT model, which utilizes the SMoE architecture, achieves performance comparable to that of GPT-4 in the IP domain and demonstrates a better cost-performance ratio on long-text tasks, potentially serving as an alternative to GPT-4 within the IP domain.
A Map-matching Algorithm with Extraction of Multi-group Information for Low-frequency Data
Sep 18, 2022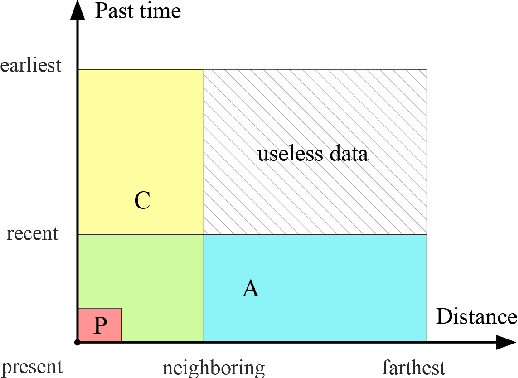
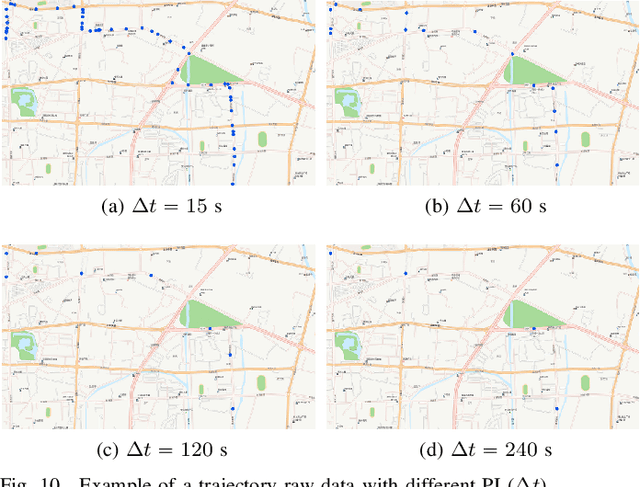
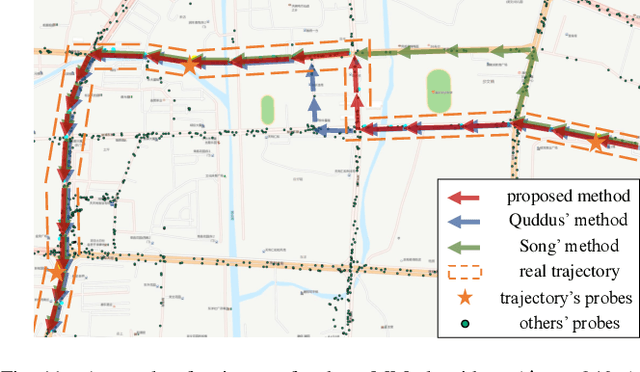
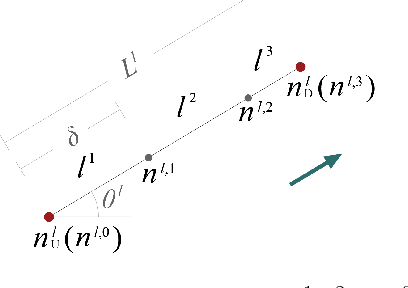
The growing use of probe vehicles generates a huge number of GNSS data. Limited by the satellite positioning technology, further improving the accuracy of map-matching is challenging work, especially for low-frequency trajectories. When matching a trajectory, the ego vehicle's spatial-temporal information of the present trip is the most useful with the least amount of data. In addition, there are a large amount of other data, e.g., other vehicles' state and past prediction results, but it is hard to extract useful information for matching maps and inferring paths. Most map-matching studies only used the ego vehicle's data and ignored other vehicles' data. Based on it, this paper designs a new map-matching method to make full use of "Big data". We first sort all data into four groups according to their spatial and temporal distance from the present matching probe which allows us to sort for their usefulness. Then we design three different methods to extract valuable information (scores) from them: a score for speed and bearing, a score for historical usage, and a score for traffic state using the spectral graph Markov neutral network. Finally, we use a modified top-K shortest-path method to search the candidate paths within an ellipse region and then use the fused score to infer the path (projected location). We test the proposed method against baseline algorithms using a real-world dataset in China. The results show that all scoring methods can enhance map-matching accuracy. Furthermore, our method outperforms the others, especially when GNSS probing frequency is less than 0.01 Hz.
Neural Network-based Automatic Factor Construction
Aug 14, 2020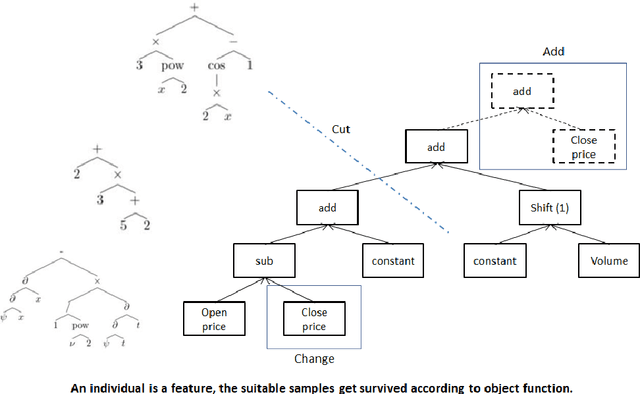
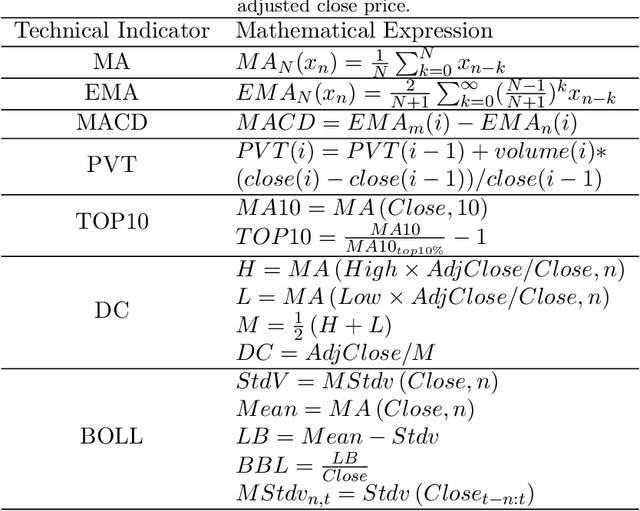
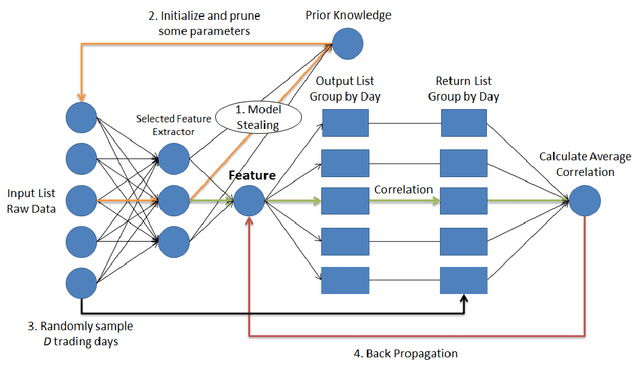
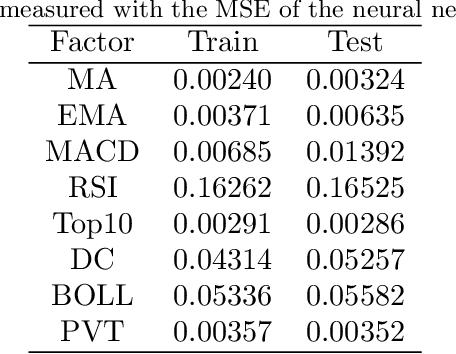
Instead of conducting manual factor construction based on traditional and behavioural finance analysis, academic researchers and quantitative investment managers have leveraged Genetic Programming (GP) as an automatic feature construction tool in recent years, which builds reverse polish mathematical expressions from trading data into new factors. However, with the development of deep learning, more powerful feature extraction tools are available. This paper proposes Neural Network-based Automatic Factor Construction (NNAFC), a tailored neural network framework that can automatically construct diversified financial factors based on financial domain knowledge and a variety of neural network structures. The experiment results show that NNAFC can construct more informative and diversified factors than GP, to effectively enrich the current factor pool. For the current market, both fully connected and recurrent neural network structures are better at extracting information from financial time series than convolution neural network structures. Moreover, new factors constructed by NNAFC can always improve the return, Sharpe ratio, and the max draw-down of a multi-factor quantitative investment strategy due to their introducing more information and diversification to the existing factor pool.
Prior knowledge distillation based on financial time series
Jun 17, 2020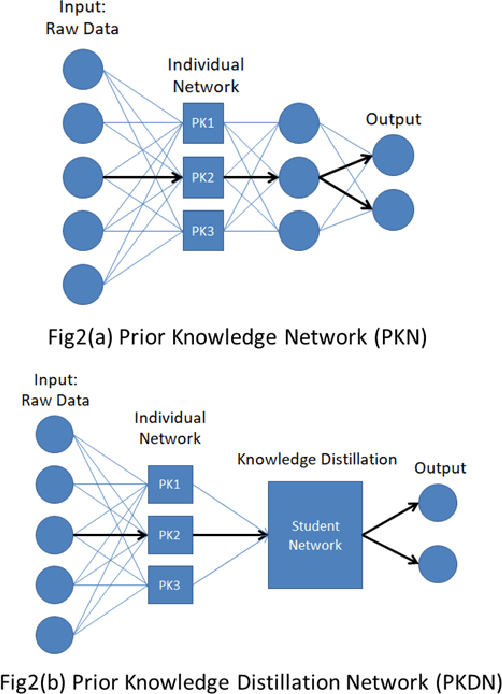


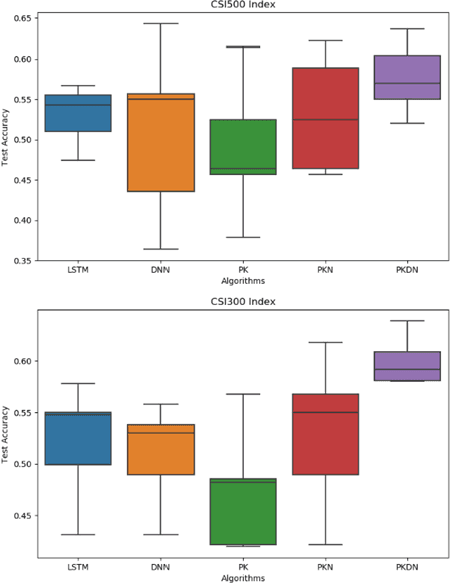
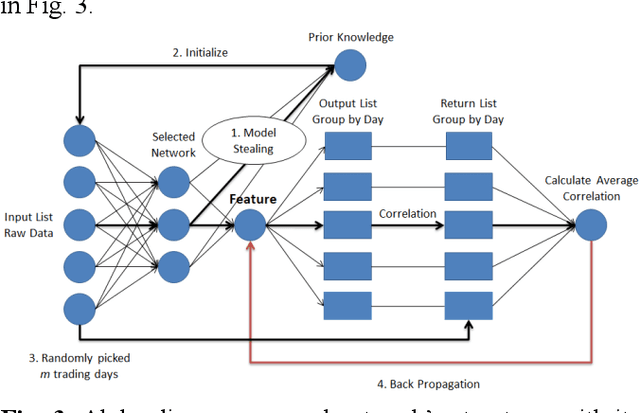
One of the major characteristics of financial time series is that they contain a large amount of non-stationary noise, which is challenging for deep neural networks. People normally use various features to address this problem. However, the performance of these features depends on the choice of hyper-parameters. In this paper, we propose to use neural networks to represent these indicators and train a large network constructed of smaller networks as feature layers to fine-tune the prior knowledge represented by the indicators. During back propagation, prior knowledge is transferred from human logic to machine logic via gradient descent. Prior knowledge is the deep belief of neural network and teaches the network to not be affected by non-stationary noise. Moreover, co-distillation is applied to distill the structure into a much smaller size to reduce redundant features and the risk of overfitting. In addition, the decisions of the smaller networks in terms of gradient descent are more robust and cautious than those of large networks. In numerical experiments, we find that our algorithm is faster and more accurate than traditional methods on real financial datasets. We also conduct experiments to verify and comprehend the method.
Automatic financial feature construction based on neural network
Jan 30, 2020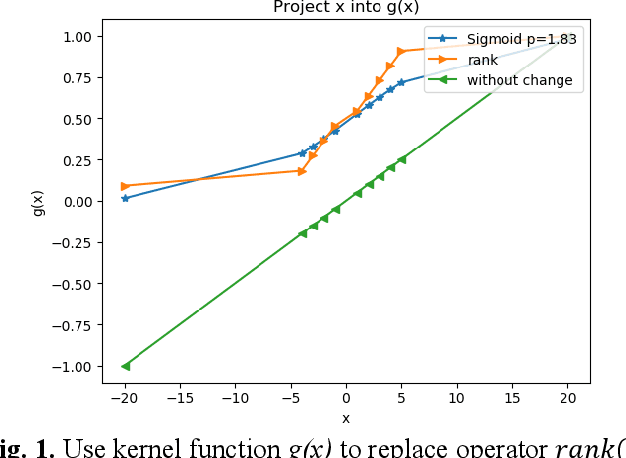
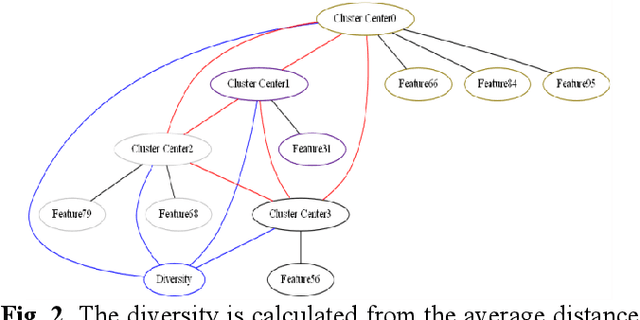
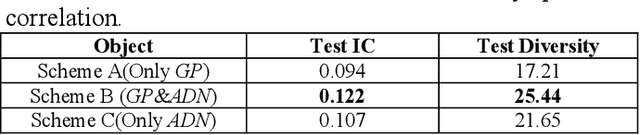
In automatic financial feature construction task, the state of the art technic leverages reverse polish expression to represent the features, then use genetic programming (GP) to conduct its evolution process. In this paper, we propose a new framework based on neural network, alpha discovery neural network (ADNN). In this work, we made several contributions. Firstly, in this task, we make full use of neural network's overwhelming advantage in feature extraction to construct highly informative features. Secondly, we use domain knowledge to design the object function, batch size, and sampling rules. Thirdly, we use pre-training to replace the GP's evolution process. According to neural network's universal approximation theorem, pre-training can conduct a more effective and explainable evolution process. Experiment shows that ADNN can remarkably produce more diversified and higher informative features than GP. Besides, ADNN can serve as a data augmentation algorithm. It further improves the the performance of financial features constructed by GP.