 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrior knowledge distillation based on financial time series
Paper and Code
Jun 17, 2020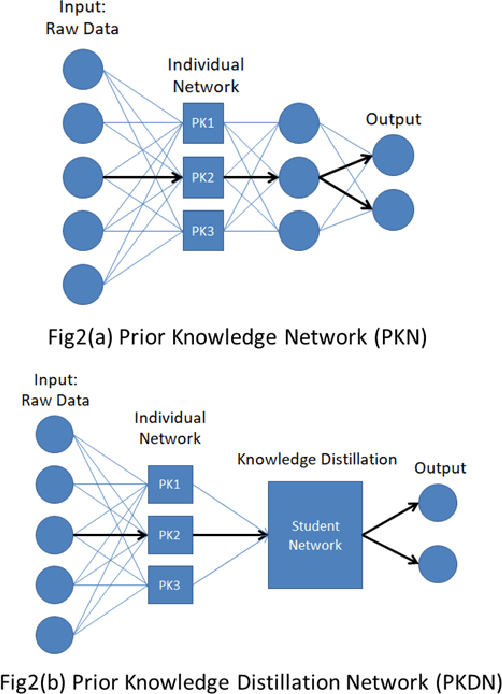


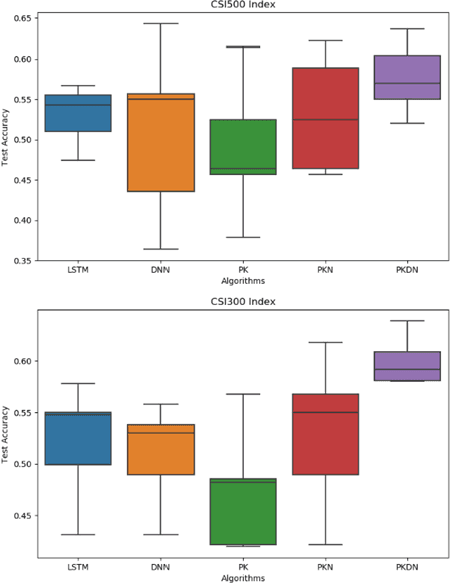
One of the major characteristics of financial time series is that they contain a large amount of non-stationary noise, which is challenging for deep neural networks. People normally use various features to address this problem. However, the performance of these features depends on the choice of hyper-parameters. In this paper, we propose to use neural networks to represent these indicators and train a large network constructed of smaller networks as feature layers to fine-tune the prior knowledge represented by the indicators. During back propagation, prior knowledge is transferred from human logic to machine logic via gradient descent. Prior knowledge is the deep belief of neural network and teaches the network to not be affected by non-stationary noise. Moreover, co-distillation is applied to distill the structure into a much smaller size to reduce redundant features and the risk of overfitting. In addition, the decisions of the smaller networks in terms of gradient descent are more robust and cautious than those of large networks. In numerical experiments, we find that our algorithm is faster and more accurate than traditional methods on real financial datasets. We also conduct experiments to verify and comprehend the method.