 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaleEnv: Scaling Environment Synthesis from Scratch for Generalist Interactive Tool-Use Agent Training
Feb 06, 2026Training generalist agents capable of adapting to diverse scenarios requires interactive environments for self-exploration. However, interactive environments remain critically scarce, and existing synthesis methods suffer from significant limitations regarding environmental diversity and scalability. To address these challenges, we introduce ScaleEnv, a framework that constructs fully interactive environments and verifiable tasks entirely from scratch. Specifically, ScaleEnv ensures environment reliability through procedural testing, and guarantees task completeness and solvability via tool dependency graph expansion and executable action verification. By enabling agents to learn through exploration within ScaleEnv, we demonstrate significant performance improvements on unseen, multi-turn tool-use benchmarks such as $τ^2$-Bench and VitaBench, highlighting strong generalization capabilities. Furthermore, we investigate the relationship between increasing number of domains and model generalization performance, providing empirical evidence that scaling environmental diversity is critical for robust agent learning.
LongCat-Flash-Thinking-2601 Technical Report
Jan 23, 2026We introduce LongCat-Flash-Thinking-2601, a 560-billion-parameter open-source Mixture-of-Experts (MoE) reasoning model with superior agentic reasoning capability. LongCat-Flash-Thinking-2601 achieves state-of-the-art performance among open-source models on a wide range of agentic benchmarks, including agentic search, agentic tool use, and tool-integrated reasoning. Beyond benchmark performance, the model demonstrates strong generalization to complex tool interactions and robust behavior under noisy real-world environments. Its advanced capability stems from a unified training framework that combines domain-parallel expert training with subsequent fusion, together with an end-to-end co-design of data construction, environments, algorithms, and infrastructure spanning from pre-training to post-training. In particular, the model's strong generalization capability in complex tool-use are driven by our in-depth exploration of environment scaling and principled task construction. To optimize long-tailed, skewed generation and multi-turn agentic interactions, and to enable stable training across over 10,000 environments spanning more than 20 domains, we systematically extend our asynchronous reinforcement learning framework, DORA, for stable and efficient large-scale multi-environment training. Furthermore, recognizing that real-world tasks are inherently noisy, we conduct a systematic analysis and decomposition of real-world noise patterns, and design targeted training procedures to explicitly incorporate such imperfections into the training process, resulting in improved robustness for real-world applications. To further enhance performance on complex reasoning tasks, we introduce a Heavy Thinking mode that enables effective test-time scaling by jointly expanding reasoning depth and width through intensive parallel thinking.
VitaBench: Benchmarking LLM Agents with Versatile Interactive Tasks in Real-world Applications
Sep 30, 2025As LLM-based agents are increasingly deployed in real-life scenarios, existing benchmarks fail to capture their inherent complexity of handling extensive information, leveraging diverse resources, and managing dynamic user interactions. To address this gap, we introduce VitaBench, a challenging benchmark that evaluates agents on versatile interactive tasks grounded in real-world settings. Drawing from daily applications in food delivery, in-store consumption, and online travel services, VitaBench presents agents with the most complex life-serving simulation environment to date, comprising 66 tools. Through a framework that eliminates domain-specific policies, we enable flexible composition of these scenarios and tools, yielding 100 cross-scenario tasks (main results) and 300 single-scenario tasks. Each task is derived from multiple real user requests and requires agents to reason across temporal and spatial dimensions, utilize complex tool sets, proactively clarify ambiguous instructions, and track shifting user intent throughout multi-turn conversations. Moreover, we propose a rubric-based sliding window evaluator, enabling robust assessment of diverse solution pathways in complex environments and stochastic interactions. Our comprehensive evaluation reveals that even the most advanced models achieve only 30% success rate on cross-scenario tasks, and less than 50% success rate on others. Overall, we believe VitaBench will serve as a valuable resource for advancing the development of AI agents in practical real-world applications. The code, dataset, and leaderboard are available at https://vitabench.github.io/
Neural Network-based Automatic Factor Construction
Aug 14, 2020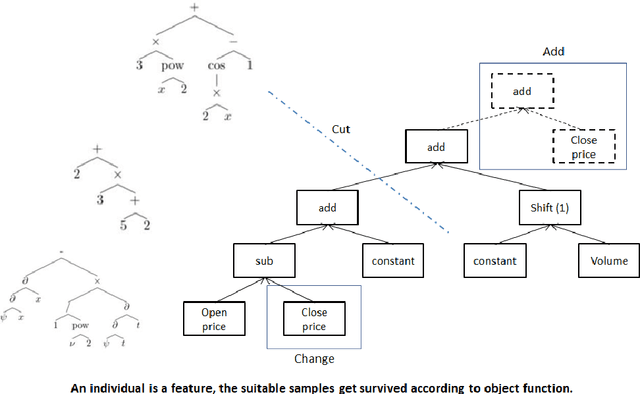
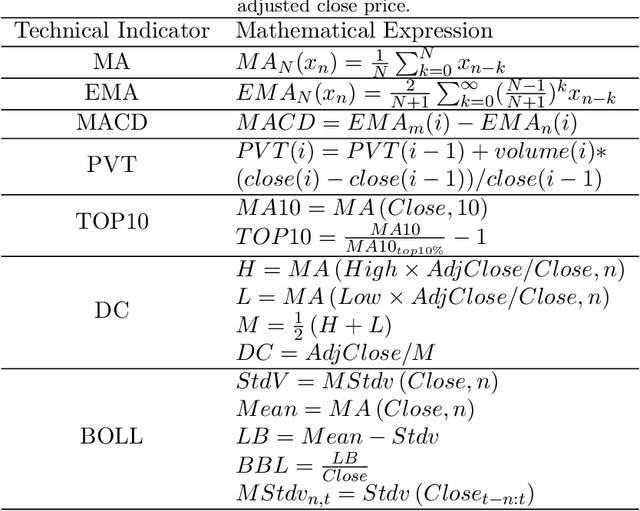
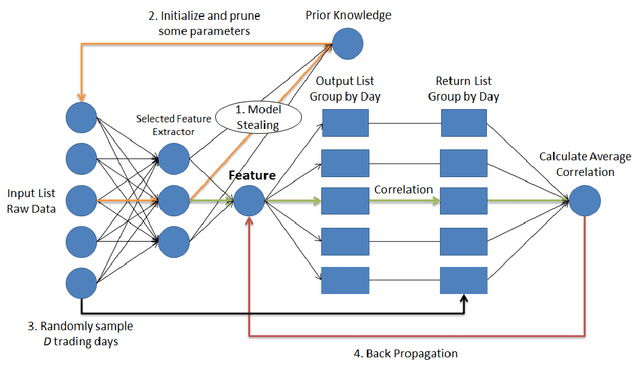
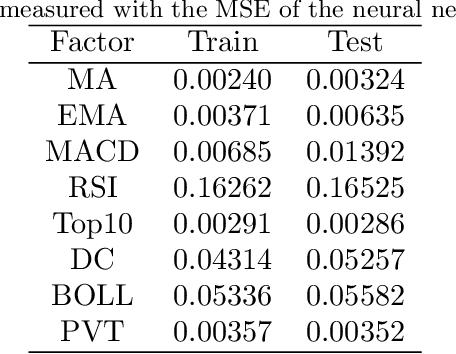
Instead of conducting manual factor construction based on traditional and behavioural finance analysis, academic researchers and quantitative investment managers have leveraged Genetic Programming (GP) as an automatic feature construction tool in recent years, which builds reverse polish mathematical expressions from trading data into new factors. However, with the development of deep learning, more powerful feature extraction tools are available. This paper proposes Neural Network-based Automatic Factor Construction (NNAFC), a tailored neural network framework that can automatically construct diversified financial factors based on financial domain knowledge and a variety of neural network structures. The experiment results show that NNAFC can construct more informative and diversified factors than GP, to effectively enrich the current factor pool. For the current market, both fully connected and recurrent neural network structures are better at extracting information from financial time series than convolution neural network structures. Moreover, new factors constructed by NNAFC can always improve the return, Sharpe ratio, and the max draw-down of a multi-factor quantitative investment strategy due to their introducing more information and diversification to the existing factor pool.
Alpha Discovery Neural Network based on Prior Knowledge
Jan 03, 2020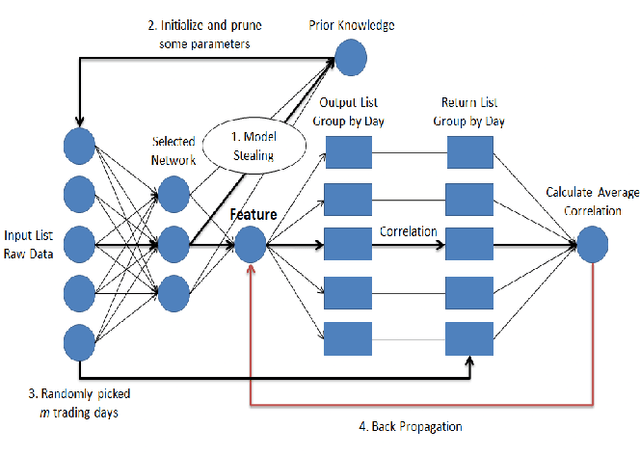

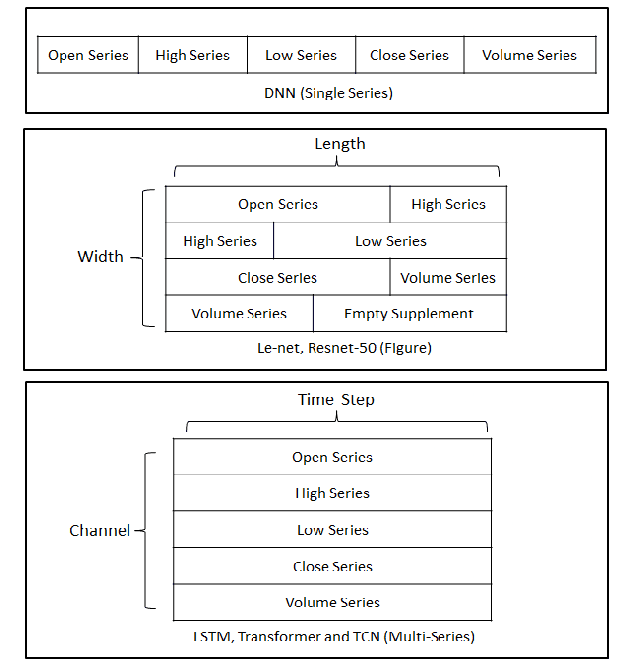
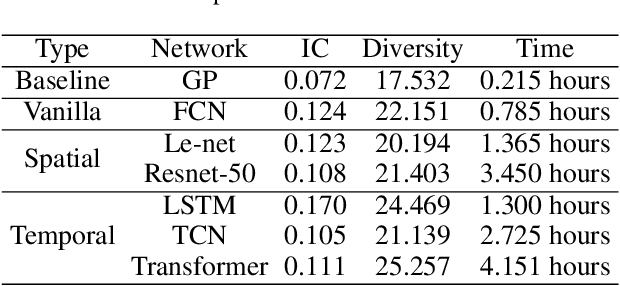
In financial automatic feature construction task, genetic programming is the state-of-the-art-technic. It uses reverse polish expression to represent features and then uses genetic programming to simulate the evolution process. With the development of deep learning, there are more powerful feature extractors for option. And we think that comprehending the relationship between different feature extractors and data shall be the key. In this work, we put prior knowledge into alpha discovery neural network, combined with different kinds of feature extractors to do this task. We find that in the same type of network, simple network structure can produce more informative features than sophisticated network structure, and it costs less training time. However, complex network is good at providing more diversified features. In both experiment and real business environment, fully-connected network and recurrent network are good at extracting information from financial time series, but convolution network structure can not effectively extract this information.