 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTS-DP: Reinforcement Speculative Decoding For Temporal Adaptive Diffusion Policy Acceleration
Dec 13, 2025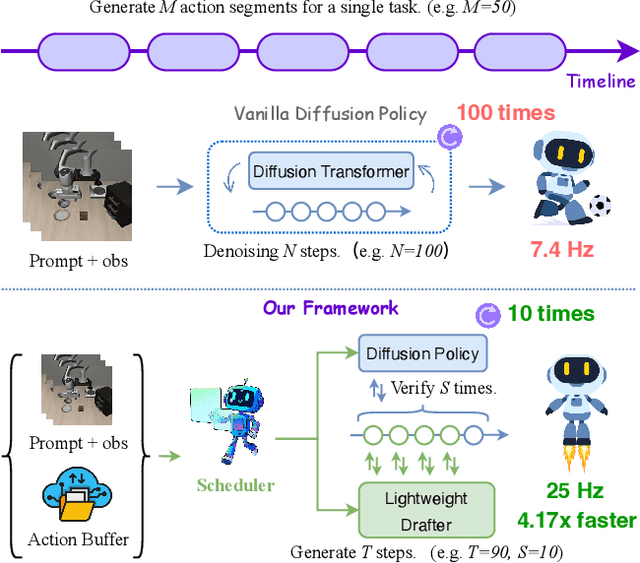
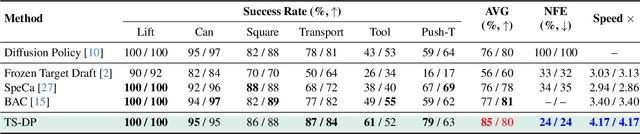

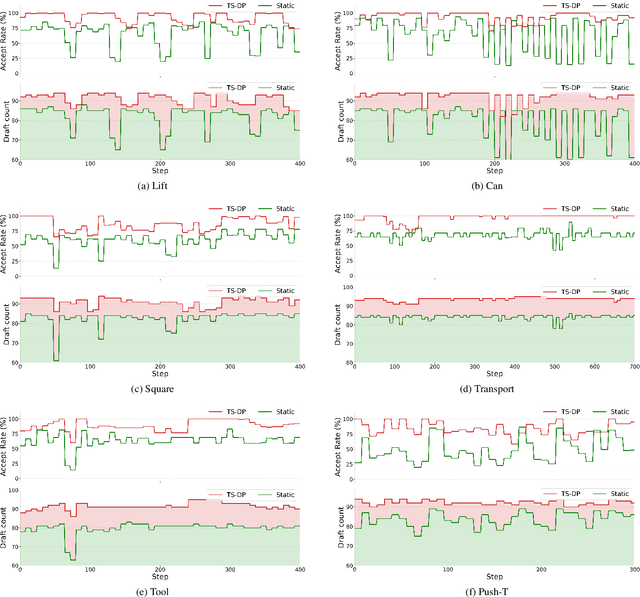
Diffusion Policy (DP) excels in embodied control but suffers from high inference latency and computational cost due to multiple iterative denoising steps. The temporal complexity of embodied tasks demands a dynamic and adaptable computation mode. Static and lossy acceleration methods, such as quantization, fail to handle such dynamic embodied tasks, while speculative decoding offers a lossless and adaptive yet underexplored alternative for DP. However, it is non-trivial to address the following challenges: how to match the base model's denoising quality at lower cost under time-varying task difficulty in embodied settings, and how to dynamically and interactively adjust computation based on task difficulty in such environments. In this paper, we propose Temporal-aware Reinforcement-based Speculative Diffusion Policy (TS-DP), the first framework that enables speculative decoding for DP with temporal adaptivity. First, to handle dynamic environments where task difficulty varies over time, we distill a Transformer-based drafter to imitate the base model and replace its costly denoising calls. Second, an RL-based scheduler further adapts to time-varying task difficulty by adjusting speculative parameters to maintain accuracy while improving efficiency. Extensive experiments across diverse embodied environments demonstrate that TS-DP achieves up to 4.17 times faster inference with over 94% accepted drafts, reaching an inference frequency of 25 Hz and enabling real-time diffusion-based control without performance degradation.
SP-VLA: A Joint Model Scheduling and Token Pruning Approach for VLA Model Acceleration
Jun 15, 2025Vision-Language-Action (VLA) models have attracted increasing attention for their strong control capabilities. However, their high computational cost and low execution frequency hinder their suitability for real-time tasks such as robotic manipulation and autonomous navigation. Existing VLA acceleration methods primarily focus on structural optimization, overlooking the fact that these models operate in sequential decision-making environments. As a result, temporal redundancy in sequential action generation and spatial redundancy in visual input remain unaddressed. To this end, we propose SP-VLA, a unified framework that accelerates VLA models by jointly scheduling models and pruning tokens. Specifically, we design an action-aware model scheduling mechanism that reduces temporal redundancy by dynamically switching between VLA model and a lightweight generator. Inspired by the human motion pattern of focusing on key decision points while relying on intuition for other actions, we categorize VLA actions into deliberative and intuitive, assigning the former to the VLA model and the latter to the lightweight generator, enabling frequency-adaptive execution through collaborative model scheduling. To address spatial redundancy, we further develop a spatio-semantic dual-aware token pruning method. Tokens are classified into spatial and semantic types and pruned based on their dual-aware importance to accelerate VLA inference. These two mechanisms work jointly to guide the VLA in focusing on critical actions and salient visual information, achieving effective acceleration while maintaining high accuracy. Experimental results demonstrate that our method achieves up to 1.5$\times$ acceleration with less than 3% drop in accuracy, outperforming existing approaches in multiple tasks.
Mitigating Group-Level Fairness Disparities in Federated Visual Language Models
May 03, 2025Visual language models (VLMs) have shown remarkable capabilities in multimodal tasks but face challenges in maintaining fairness across demographic groups, particularly when deployed in federated learning (FL) environments. This paper addresses the critical issue of group fairness in federated VLMs by introducing FVL-FP, a novel framework that combines FL with fair prompt tuning techniques. We focus on mitigating demographic biases while preserving model performance through three innovative components: (1) Cross-Layer Demographic Fair Prompting (CDFP), which adjusts potentially biased embeddings through counterfactual regularization; (2) Demographic Subspace Orthogonal Projection (DSOP), which removes demographic bias in image representations by mapping fair prompt text to group subspaces; and (3) Fair-aware Prompt Fusion (FPF), which dynamically balances client contributions based on both performance and fairness metrics. Extensive evaluations across four benchmark datasets demonstrate that our approach reduces demographic disparity by an average of 45\% compared to standard FL approaches, while maintaining task performance within 6\% of state-of-the-art results. FVL-FP effectively addresses the challenges of non-IID data distributions in federated settings and introduces minimal computational overhead while providing significant fairness benefits. Our work presents a parameter-efficient solution to the critical challenge of ensuring equitable performance across demographic groups in privacy-preserving multimodal systems.
Diffusion Prior Interpolation for Flexibility Real-World Face Super-Resolution
Dec 21, 2024
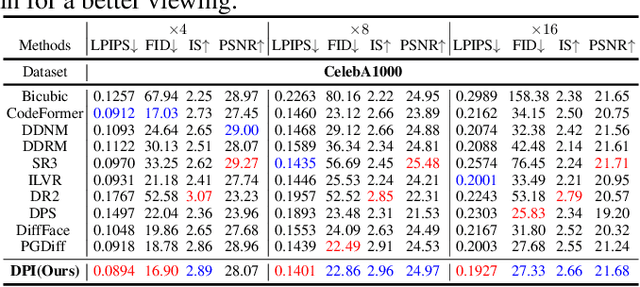
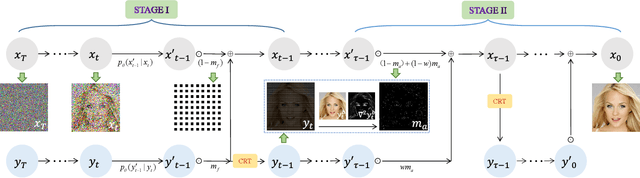
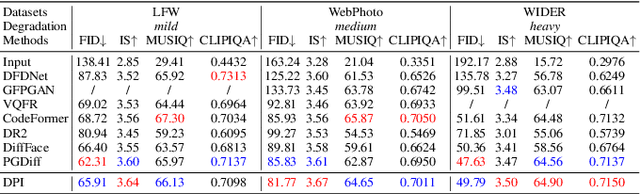
Diffusion models represent the state-of-the-art in generative modeling. Due to their high training costs, many works leverage pre-trained diffusion models' powerful representations for downstream tasks, such as face super-resolution (FSR), through fine-tuning or prior-based methods. However, relying solely on priors without supervised training makes it challenging to meet the pixel-level accuracy requirements of discrimination task. Although prior-based methods can achieve high fidelity and high-quality results, ensuring consistency remains a significant challenge. In this paper, we propose a masking strategy with strong and weak constraints and iterative refinement for real-world FSR, termed Diffusion Prior Interpolation (DPI). We introduce conditions and constraints on consistency by masking different sampling stages based on the structural characteristics of the face. Furthermore, we propose a condition Corrector (CRT) to establish a reciprocal posterior sampling process, enhancing FSR performance by mutual refinement of conditions and samples. DPI can balance consistency and diversity and can be seamlessly integrated into pre-trained models. In extensive experiments conducted on synthetic and real datasets, along with consistency validation in face recognition, DPI demonstrates superiority over SOTA FSR methods. The code is available at \url{https://github.com/JerryYann/DPI}.
EMS: Adaptive Evict-then-Merge Strategy for Head-wise KV Cache Compression Based on Global-Local Importance
Dec 11, 2024As large language models (LLMs) continue to advance, the demand for higher quality and faster processing of long contexts across various applications is growing. KV cache is widely adopted as it stores previously generated key and value tokens, effectively reducing redundant computations during inference. However, as memory overhead becomes a significant concern, efficient compression of KV cache has gained increasing attention. Most existing methods perform compression from two perspectives: identifying important tokens and designing compression strategies. However, these approaches often produce biased distributions of important tokens due to the influence of accumulated attention scores or positional encoding. Furthermore, they overlook the sparsity and redundancy across different heads, which leads to difficulties in preserving the most effective information at the head level. To this end, we propose EMS to overcome these limitations, while achieving better KV cache compression under extreme compression ratios. Specifically, we introduce a Global-Local score that combines accumulated attention scores from both global and local KV tokens to better identify the token importance. For the compression strategy, we design an adaptive and unified Evict-then-Merge framework that accounts for the sparsity and redundancy of KV tokens across different heads. Additionally, we implement the head-wise parallel compression through a zero-class mechanism to enhance efficiency. Extensive experiments demonstrate our SOTA performance even under extreme compression ratios. EMS consistently achieves the lowest perplexity, improves scores by over 1.28 points across four LLMs on LongBench under a 256 cache budget, and preserves 95% retrieval accuracy with a cache budget less than 2% of the context length in the Needle-in-a-Haystack task.
One Perturbation is Enough: On Generating Universal Adversarial Perturbations against Vision-Language Pre-training Models
Jun 08, 2024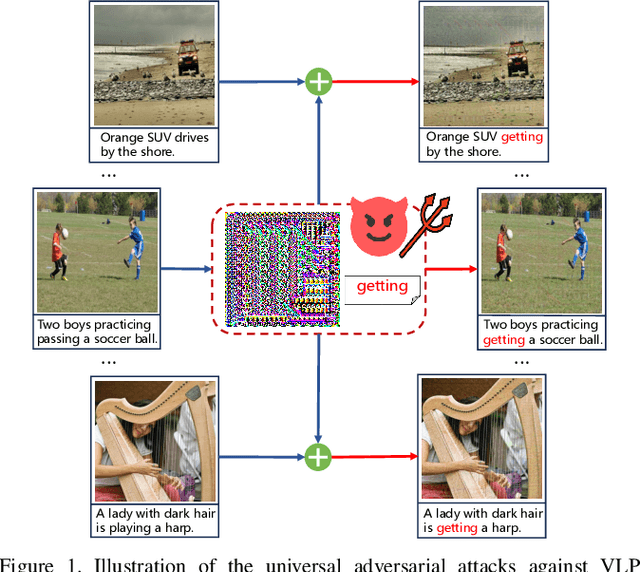
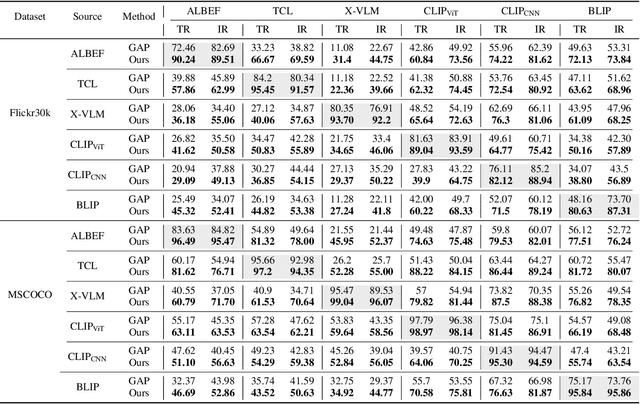
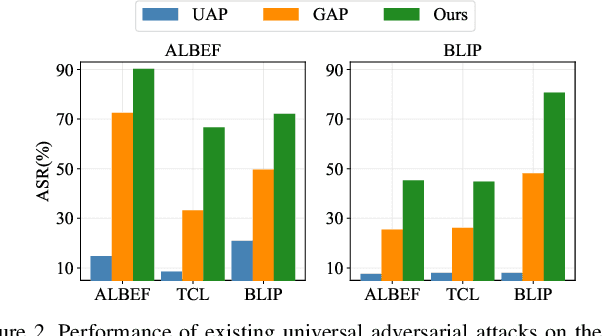
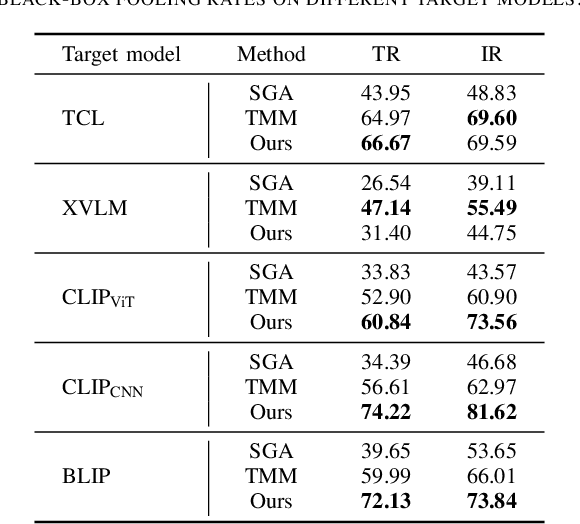
Vision-Language Pre-training (VLP) models trained on large-scale image-text pairs have demonstrated unprecedented capability in many practical applications. However, previous studies have revealed that VLP models are vulnerable to adversarial samples crafted by a malicious adversary. While existing attacks have achieved great success in improving attack effect and transferability, they all focus on instance-specific attacks that generate perturbations for each input sample. In this paper, we show that VLP models can be vulnerable to a new class of universal adversarial perturbation (UAP) for all input samples. Although initially transplanting existing UAP algorithms to perform attacks showed effectiveness in attacking discriminative models, the results were unsatisfactory when applied to VLP models. To this end, we revisit the multimodal alignments in VLP model training and propose the Contrastive-training Perturbation Generator with Cross-modal conditions (C-PGC). Specifically, we first design a generator that incorporates cross-modal information as conditioning input to guide the training. To further exploit cross-modal interactions, we propose to formulate the training objective as a multimodal contrastive learning paradigm based on our constructed positive and negative image-text pairs. By training the conditional generator with the designed loss, we successfully force the adversarial samples to move away from its original area in the VLP model's feature space, and thus essentially enhance the attacks. Extensive experiments show that our method achieves remarkable attack performance across various VLP models and Vision-and-Language (V+L) tasks. Moreover, C-PGC exhibits outstanding black-box transferability and achieves impressive results in fooling prevalent large VLP models including LLaVA and Qwen-VL.
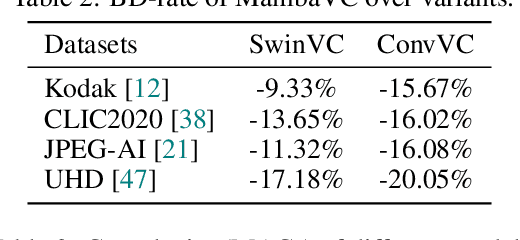
MambaVC: Learned Visual Compression with Selective State Spaces
May 28, 2024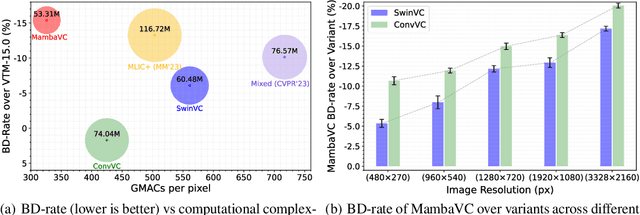
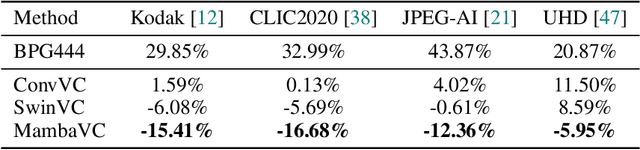
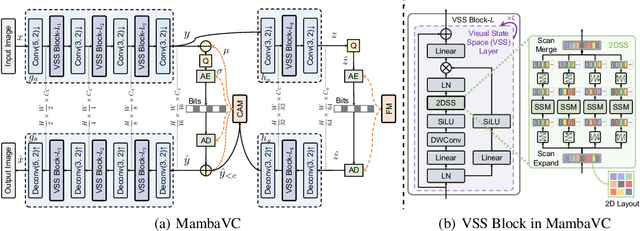
Learned visual compression is an important and active task in multimedia. Existing approaches have explored various CNN- and Transformer-based designs to model content distribution and eliminate redundancy, where balancing efficacy (i.e., rate-distortion trade-off) and efficiency remains a challenge. Recently, state-space models (SSMs) have shown promise due to their long-range modeling capacity and efficiency. Inspired by this, we take the first step to explore SSMs for visual compression. We introduce MambaVC, a simple, strong and efficient compression network based on SSM. MambaVC develops a visual state space (VSS) block with a 2D selective scanning (2DSS) module as the nonlinear activation function after each downsampling, which helps to capture informative global contexts and enhances compression. On compression benchmark datasets, MambaVC achieves superior rate-distortion performance with lower computational and memory overheads. Specifically, it outperforms CNN and Transformer variants by 9.3% and 15.6% on Kodak, respectively, while reducing computation by 42% and 24%, and saving 12% and 71% of memory. MambaVC shows even greater improvements with high-resolution images, highlighting its potential and scalability in real-world applications. We also provide a comprehensive comparison of different network designs, underscoring MambaVC's advantages. Code is available at https://github.com/QinSY123/2024-MambaVC.
Theoretically Principled Federated Learning for Balancing Privacy and Utility
May 24, 2023We propose a general learning framework for the protection mechanisms that protects privacy via distorting model parameters, which facilitates the trade-off between privacy and utility. The algorithm is applicable to arbitrary privacy measurements that maps from the distortion to a real value. It can achieve personalized utility-privacy trade-off for each model parameter, on each client, at each communication round in federated learning. Such adaptive and fine-grained protection can improve the effectiveness of privacy-preserved federated learning. Theoretically, we show that gap between the utility loss of the protection hyperparameter output by our algorithm and that of the optimal protection hyperparameter is sub-linear in the total number of iterations. The sublinearity of our algorithm indicates that the average gap between the performance of our algorithm and that of the optimal performance goes to zero when the number of iterations goes to infinity. Further, we provide the convergence rate of our proposed algorithm. We conduct empirical results on benchmark datasets to verify that our method achieves better utility than the baseline methods under the same privacy budget.
Contrastive Masked Autoencoders for Self-Supervised Video Hashing
Nov 23, 2022



Self-Supervised Video Hashing (SSVH) models learn to generate short binary representations for videos without ground-truth supervision, facilitating large-scale video retrieval efficiency and attracting increasing research attention. The success of SSVH lies in the understanding of video content and the ability to capture the semantic relation among unlabeled videos. Typically, state-of-the-art SSVH methods consider these two points in a two-stage training pipeline, where they firstly train an auxiliary network by instance-wise mask-and-predict tasks and secondly train a hashing model to preserve the pseudo-neighborhood structure transferred from the auxiliary network. This consecutive training strategy is inflexible and also unnecessary. In this paper, we propose a simple yet effective one-stage SSVH method called ConMH, which incorporates video semantic information and video similarity relationship understanding in a single stage. To capture video semantic information for better hashing learning, we adopt an encoder-decoder structure to reconstruct the video from its temporal-masked frames. Particularly, we find that a higher masking ratio helps video understanding. Besides, we fully exploit the similarity relationship between videos by maximizing agreement between two augmented views of a video, which contributes to more discriminative and robust hash codes. Extensive experiments on three large-scale video datasets (i.e., FCVID, ActivityNet and YFCC) indicate that ConMH achieves state-of-the-art results. Code is available at https://github.com/huangmozhi9527/ConMH.
PILC: Practical Image Lossless Compression with an End-to-end GPU Oriented Neural Framework
Jun 10, 2022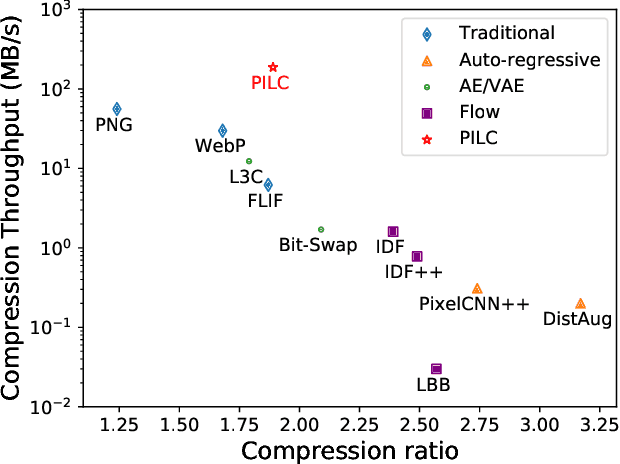

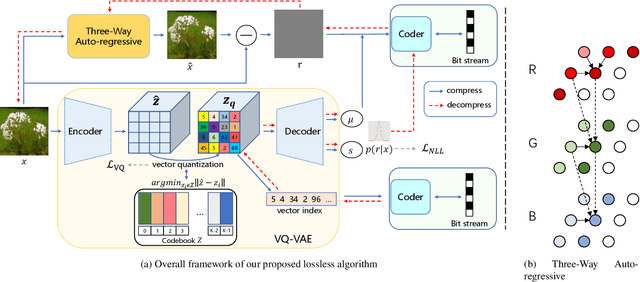

Generative model based image lossless compression algorithms have seen a great success in improving compression ratio. However, the throughput for most of them is less than 1 MB/s even with the most advanced AI accelerated chips, preventing them from most real-world applications, which often require 100 MB/s. In this paper, we propose PILC, an end-to-end image lossless compression framework that achieves 200 MB/s for both compression and decompression with a single NVIDIA Tesla V100 GPU, 10 times faster than the most efficient one before. To obtain this result, we first develop an AI codec that combines auto-regressive model and VQ-VAE which performs well in lightweight setting, then we design a low complexity entropy coder that works well with our codec. Experiments show that our framework compresses better than PNG by a margin of 30% in multiple datasets. We believe this is an important step to bring AI compression forward to commercial use.