 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMambaVC: Learned Visual Compression with Selective State Spaces
Paper and Code
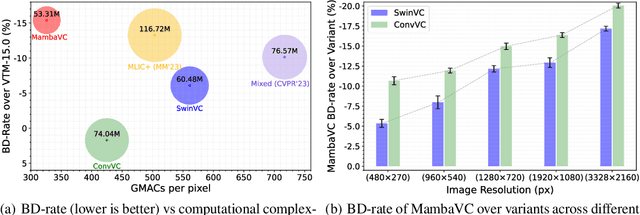
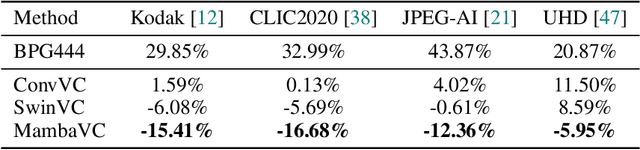
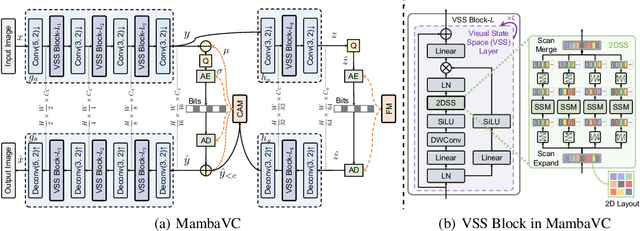
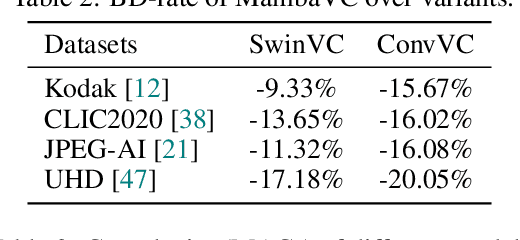
Learned visual compression is an important and active task in multimedia. Existing approaches have explored various CNN- and Transformer-based designs to model content distribution and eliminate redundancy, where balancing efficacy (i.e., rate-distortion trade-off) and efficiency remains a challenge. Recently, state-space models (SSMs) have shown promise due to their long-range modeling capacity and efficiency. Inspired by this, we take the first step to explore SSMs for visual compression. We introduce MambaVC, a simple, strong and efficient compression network based on SSM. MambaVC develops a visual state space (VSS) block with a 2D selective scanning (2DSS) module as the nonlinear activation function after each downsampling, which helps to capture informative global contexts and enhances compression. On compression benchmark datasets, MambaVC achieves superior rate-distortion performance with lower computational and memory overheads. Specifically, it outperforms CNN and Transformer variants by 9.3% and 15.6% on Kodak, respectively, while reducing computation by 42% and 24%, and saving 12% and 71% of memory. MambaVC shows even greater improvements with high-resolution images, highlighting its potential and scalability in real-world applications. We also provide a comprehensive comparison of different network designs, underscoring MambaVC's advantages. Code is available at https://github.com/QinSY123/2024-MambaVC.