 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePromptHub: Enhancing Multi-Prompt Visual In-Context Learning with Locality-Aware Fusion, Concentration and Alignment
Mar 19, 2026Visual In-Context Learning (VICL) aims to complete vision tasks by imitating pixel demonstrations. Recent work pioneered prompt fusion that combines the advantages of various demonstrations, which shows a promising way to extend VICL. Unfortunately, the patch-wise fusion framework and model-agnostic supervision hinder the exploitation of informative cues, thereby limiting performance gains. To overcome this deficiency, we introduce PromptHub, a framework that holistically strengthens multi-prompting through locality-aware fusion, concentration and alignment. PromptHub exploits spatial priors to capture richer contextual information, employs complementary concentration, alignment, and prediction objectives to mutually guide training, and incorporates data augmentation to further reinforce supervision. Extensive experiments on three fundamental vision tasks demonstrate the superiority of PromptHub. Moreover, we validate its universality, transferability, and robustness across out-of-distribution settings, and various retrieval scenarios. This work establishes a reliable locality-aware paradigm for prompt fusion, moving beyond prior patch-wise approaches. Code is available at https://github.com/luotc-why/ICLR26-PromptHub.
Splatwizard: A Benchmark Toolkit for 3D Gaussian Splatting Compression
Dec 31, 2025The recent advent of 3D Gaussian Splatting (3DGS) has marked a significant breakthrough in real-time novel view synthesis. However, the rapid proliferation of 3DGS-based algorithms has created a pressing need for standardized and comprehensive evaluation tools, especially for compression task. Existing benchmarks often lack the specific metrics necessary to holistically assess the unique characteristics of different methods, such as rendering speed, rate distortion trade-offs memory efficiency, and geometric accuracy. To address this gap, we introduce Splatwizard, a unified benchmark toolkit designed specifically for benchmarking 3DGS compression models. Splatwizard provides an easy-to-use framework to implement new 3DGS compression model and utilize state-of-the-art techniques proposed by previous work. Besides, an integrated pipeline that automates the calculation of key performance indicators, including image-based quality metrics, chamfer distance of reconstruct mesh, rendering frame rates, and computational resource consumption is included in the framework as well. Code is available at https://github.com/splatwizard/splatwizard
Image Gradient-Aided Photometric Stereo Network
Dec 16, 2024Photometric stereo (PS) endeavors to ascertain surface normals using shading clues from photometric images under various illuminations. Recent deep learning-based PS methods often overlook the complexity of object surfaces. These neural network models, which exclusively rely on photometric images for training, often produce blurred results in high-frequency regions characterized by local discontinuities, such as wrinkles and edges with significant gradient changes. To address this, we propose the Image Gradient-Aided Photometric Stereo Network (IGA-PSN), a dual-branch framework extracting features from both photometric images and their gradients. Furthermore, we incorporate an hourglass regression network along with supervision to regularize normal regression. Experiments on DiLiGenT benchmarks show that IGA-PSN outperforms previous methods in surface normal estimation, achieving a mean angular error of 6.46 while preserving textures and geometric shapes in complex regions.
* 13 pages, 5 figures, published to Springer
MambaVC: Learned Visual Compression with Selective State Spaces
May 28, 2024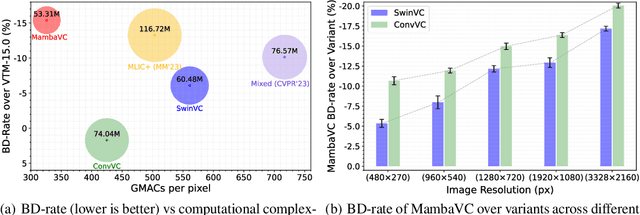
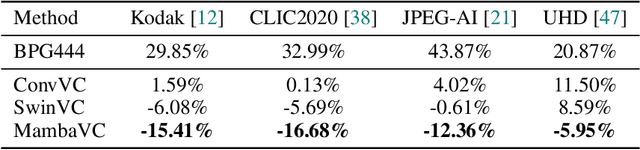
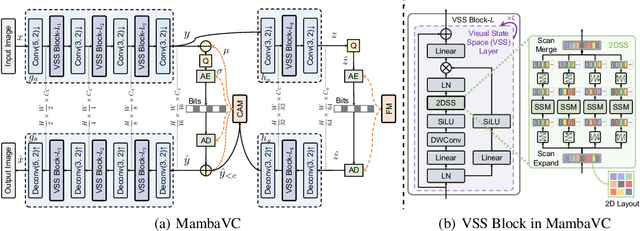
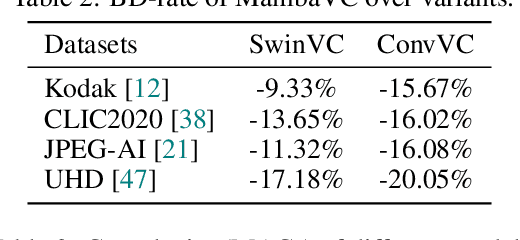
Learned visual compression is an important and active task in multimedia. Existing approaches have explored various CNN- and Transformer-based designs to model content distribution and eliminate redundancy, where balancing efficacy (i.e., rate-distortion trade-off) and efficiency remains a challenge. Recently, state-space models (SSMs) have shown promise due to their long-range modeling capacity and efficiency. Inspired by this, we take the first step to explore SSMs for visual compression. We introduce MambaVC, a simple, strong and efficient compression network based on SSM. MambaVC develops a visual state space (VSS) block with a 2D selective scanning (2DSS) module as the nonlinear activation function after each downsampling, which helps to capture informative global contexts and enhances compression. On compression benchmark datasets, MambaVC achieves superior rate-distortion performance with lower computational and memory overheads. Specifically, it outperforms CNN and Transformer variants by 9.3% and 15.6% on Kodak, respectively, while reducing computation by 42% and 24%, and saving 12% and 71% of memory. MambaVC shows even greater improvements with high-resolution images, highlighting its potential and scalability in real-world applications. We also provide a comprehensive comparison of different network designs, underscoring MambaVC's advantages. Code is available at https://github.com/QinSY123/2024-MambaVC.
Perceptual Image Compression with Cooperative Cross-Modal Side Information
Nov 28, 2023



The explosion of data has resulted in more and more associated text being transmitted along with images. Inspired by from distributed source coding, many works utilize image side information to enhance image compression. However, existing methods generally do not consider using text as side information to enhance perceptual compression of images, even though the benefits of multimodal synergy have been widely demonstrated in research. This begs the following question: How can we effectively transfer text-level semantic dependencies to help image compression, which is only available to the decoder? In this work, we propose a novel deep image compression method with text-guided side information to achieve a better rate-perception-distortion tradeoff. Specifically, we employ the CLIP text encoder and an effective Semantic-Spatial Aware block to fuse the text and image features. This is done by predicting a semantic mask to guide the learned text-adaptive affine transformation at the pixel level. Furthermore, we design a text-conditional generative adversarial networks to improve the perceptual quality of reconstructed images. Extensive experiments involving four datasets and ten image quality assessment metrics demonstrate that the proposed approach achieves superior results in terms of rate-perception trade-off and semantic distortion.
Progressive Learning with Visual Prompt Tuning for Variable-Rate Image Compression
Nov 28, 2023In this paper, we propose a progressive learning paradigm for transformer-based variable-rate image compression. Our approach covers a wide range of compression rates with the assistance of the Layer-adaptive Prompt Module (LPM). Inspired by visual prompt tuning, we use LPM to extract prompts for input images and hidden features at the encoder side and decoder side, respectively, which are fed as additional information into the Swin Transformer layer of a pre-trained transformer-based image compression model to affect the allocation of attention region and the bits, which in turn changes the target compression ratio of the model. To ensure the network is more lightweight, we involves the integration of prompt networks with less convolutional layers. Exhaustive experiments show that compared to methods based on multiple models, which are optimized separately for different target rates, the proposed method arrives at the same performance with 80% savings in parameter storage and 90% savings in datasets. Meanwhile, our model outperforms all current variable bitrate image methods in terms of rate-distortion performance and approaches the state-of-the-art fixed bitrate image compression methods trained from scratch.
Learned Distributed Image Compression with Multi-Scale Patch Matching in Feature Domai
Sep 06, 2022
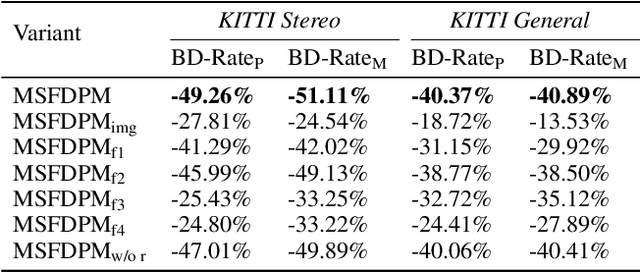
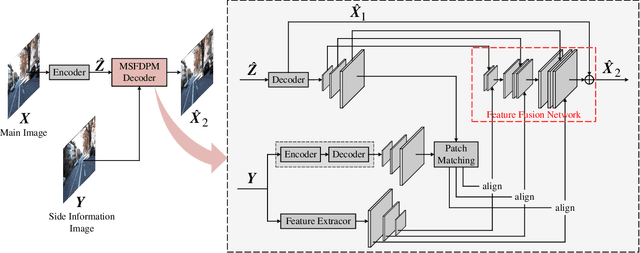

Beyond achieving higher compression efficiency over classical image compression codecs, deep image compression is expected to be improved with additional side information, e.g., another image from a different perspective of the same scene. To better utilize the side information under the distributed compression scenario, the existing method (Ayzik and Avidan 2020) only implements patch matching at the image domain to solve the parallax problem caused by the difference in viewing points. However, the patch matching at the image domain is not robust to the variance of scale, shape, and illumination caused by the different viewing angles, and can not make full use of the rich texture information of the side information image. To resolve this issue, we propose Multi-Scale Feature Domain Patch Matching (MSFDPM) to fully utilizes side information at the decoder of the distributed image compression model. Specifically, MSFDPM consists of a side information feature extractor, a multi-scale feature domain patch matching module, and a multi-scale feature fusion network. Furthermore, we reuse inter-patch correlation from the shallow layer to accelerate the patch matching of the deep layer. Finally, we nd that our patch matching in a multi-scale feature domain further improves compression rate by about 20% compared with the patch matching method at image domain (Ayzik and Avidan 2020).