 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSA$^{2}$Net: Scale-Adaptive Structure-Affinity Transformation for Spine Segmentation from Ultrasound Volume Projection Imaging
Oct 30, 2025Spine segmentation, based on ultrasound volume projection imaging (VPI), plays a vital role for intelligent scoliosis diagnosis in clinical applications. However, this task faces several significant challenges. Firstly, the global contextual knowledge of spines may not be well-learned if we neglect the high spatial correlation of different bone features. Secondly, the spine bones contain rich structural knowledge regarding their shapes and positions, which deserves to be encoded into the segmentation process. To address these challenges, we propose a novel scale-adaptive structure-aware network (SA$^{2}$Net) for effective spine segmentation. First, we propose a scale-adaptive complementary strategy to learn the cross-dimensional long-distance correlation features for spinal images. Second, motivated by the consistency between multi-head self-attention in Transformers and semantic level affinity, we propose structure-affinity transformation to transform semantic features with class-specific affinity and combine it with a Transformer decoder for structure-aware reasoning. In addition, we adopt a feature mixing loss aggregation method to enhance model training. This method improves the robustness and accuracy of the segmentation process. The experimental results demonstrate that our SA$^{2}$Net achieves superior segmentation performance compared to other state-of-the-art methods. Moreover, the adaptability of SA$^{2}$Net to various backbones enhances its potential as a promising tool for advanced scoliosis diagnosis using intelligent spinal image analysis. The code and experimental demo are available at https://github.com/taetiseo09/SA2Net.
SGDFuse: SAM-Guided Diffusion for High-Fidelity Infrared and Visible Image Fusion
Aug 07, 2025Infrared and visible image fusion (IVIF) aims to combine the thermal radiation information from infrared images with the rich texture details from visible images to enhance perceptual capabilities for downstream visual tasks. However, existing methods often fail to preserve key targets due to a lack of deep semantic understanding of the scene, while the fusion process itself can also introduce artifacts and detail loss, severely compromising both image quality and task performance. To address these issues, this paper proposes SGDFuse, a conditional diffusion model guided by the Segment Anything Model (SAM), to achieve high-fidelity and semantically-aware image fusion. The core of our method is to utilize high-quality semantic masks generated by SAM as explicit priors to guide the optimization of the fusion process via a conditional diffusion model. Specifically, the framework operates in a two-stage process: it first performs a preliminary fusion of multi-modal features, and then utilizes the semantic masks from SAM jointly with the preliminary fused image as a condition to drive the diffusion model's coarse-to-fine denoising generation. This ensures the fusion process not only has explicit semantic directionality but also guarantees the high fidelity of the final result. Extensive experiments demonstrate that SGDFuse achieves state-of-the-art performance in both subjective and objective evaluations, as well as in its adaptability to downstream tasks, providing a powerful solution to the core challenges in image fusion. The code of SGDFuse is available at https://github.com/boshizhang123/SGDFuse.
Excavate the potential of Single-Scale Features: A Decomposition Network for Water-Related Optical Image Enhancement
Aug 06, 2025Underwater image enhancement (UIE) techniques aim to improve visual quality of images captured in aquatic environments by addressing degradation issues caused by light absorption and scattering effects, including color distortion, blurring, and low contrast. Current mainstream solutions predominantly employ multi-scale feature extraction (MSFE) mechanisms to enhance reconstruction quality through multi-resolution feature fusion. However, our extensive experiments demonstrate that high-quality image reconstruction does not necessarily rely on multi-scale feature fusion. Contrary to popular belief, our experiments show that single-scale feature extraction alone can match or surpass the performance of multi-scale methods, significantly reducing complexity. To comprehensively explore single-scale feature potential in underwater enhancement, we propose an innovative Single-Scale Decomposition Network (SSD-Net). This architecture introduces an asymmetrical decomposition mechanism that disentangles input image into clean layer along with degradation layer. The former contains scene-intrinsic information and the latter encodes medium-induced interference. It uniquely combines CNN's local feature extraction capabilities with Transformer's global modeling strengths through two core modules: 1) Parallel Feature Decomposition Block (PFDB), implementing dual-branch feature space decoupling via efficient attention operations and adaptive sparse transformer; 2) Bidirectional Feature Communication Block (BFCB), enabling cross-layer residual interactions for complementary feature mining and fusion. This synergistic design preserves feature decomposition independence while establishing dynamic cross-layer information pathways, effectively enhancing degradation decoupling capacity.
Prototype-Driven Structure Synergy Network for Remote Sensing Images Segmentation
Aug 06, 2025
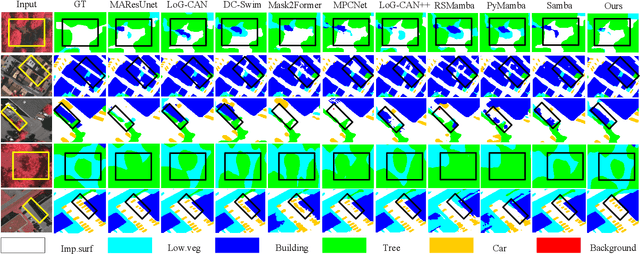
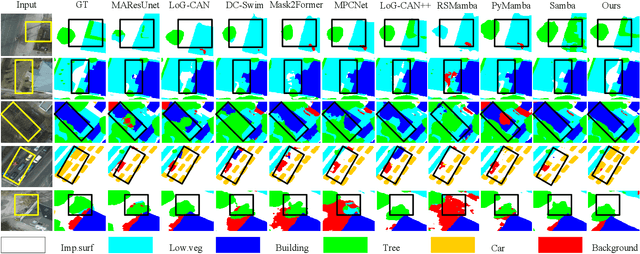
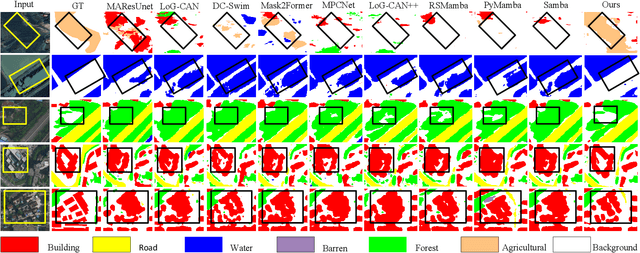
In the semantic segmentation of remote sensing images, acquiring complete ground objects is critical for achieving precise analysis. However, this task is severely hindered by two major challenges: high intra-class variance and high inter-class similarity. Traditional methods often yield incomplete segmentation results due to their inability to effectively unify class representations and distinguish between similar features. Even emerging class-guided approaches are limited by coarse class prototype representations and a neglect of target structural information. Therefore, this paper proposes a Prototype-Driven Structure Synergy Network (PDSSNet). The design of this network is based on a core concept, a complete ground object is jointly defined by its invariant class semantics and its variant spatial structure. To implement this, we have designed three key modules. First, the Adaptive Prototype Extraction Module (APEM) ensures semantic accuracy from the source by encoding the ground truth to extract unbiased class prototypes. Subsequently, the designed Semantic-Structure Coordination Module (SSCM) follows a hierarchical semantics-first, structure-second principle. This involves first establishing a global semantic cognition, then leveraging structural information to constrain and refine the semantic representation, thereby ensuring the integrity of class information. Finally, the Channel Similarity Adjustment Module (CSAM) employs a dynamic step-size adjustment mechanism to focus on discriminative features between classes. Extensive experiments demonstrate that PDSSNet outperforms state-of-the-art methods. The source code is available at https://github.com/wangjunyi-1/PDSSNet.
Aerial Multi-View Stereo via Adaptive Depth Range Inference and Normal Cues
Jun 06, 2025Three-dimensional digital urban reconstruction from multi-view aerial images is a critical application where deep multi-view stereo (MVS) methods outperform traditional techniques. However, existing methods commonly overlook the key differences between aerial and close-range settings, such as varying depth ranges along epipolar lines and insensitive feature-matching associated with low-detailed aerial images. To address these issues, we propose an Adaptive Depth Range MVS (ADR-MVS), which integrates monocular geometric cues to improve multi-view depth estimation accuracy. The key component of ADR-MVS is the depth range predictor, which generates adaptive range maps from depth and normal estimates using cross-attention discrepancy learning. In the first stage, the range map derived from monocular cues breaks through predefined depth boundaries, improving feature-matching discriminability and mitigating convergence to local optima. In later stages, the inferred range maps are progressively narrowed, ultimately aligning with the cascaded MVS framework for precise depth regression. Moreover, a normal-guided cost aggregation operation is specially devised for aerial stereo images to improve geometric awareness within the cost volume. Finally, we introduce a normal-guided depth refinement module that surpasses existing RGB-guided techniques. Experimental results demonstrate that ADR-MVS achieves state-of-the-art performance on the WHU, LuoJia-MVS, and M\"unchen datasets, while exhibits superior computational complexity.
FNIN: A Fourier Neural Operator-based Numerical Integration Network for Surface-form-gradients
Jan 21, 2025
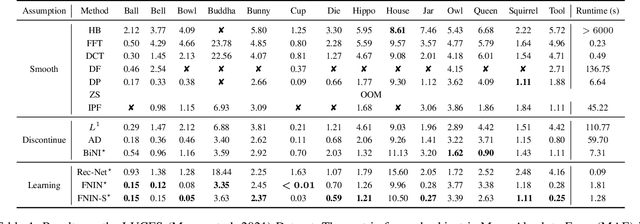
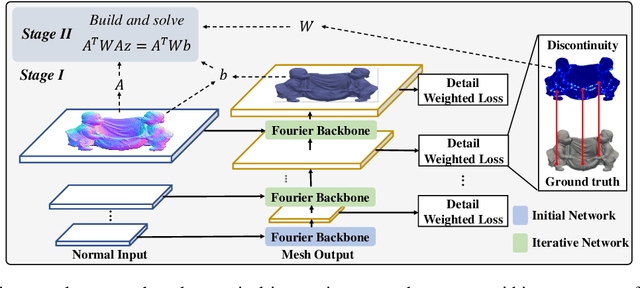
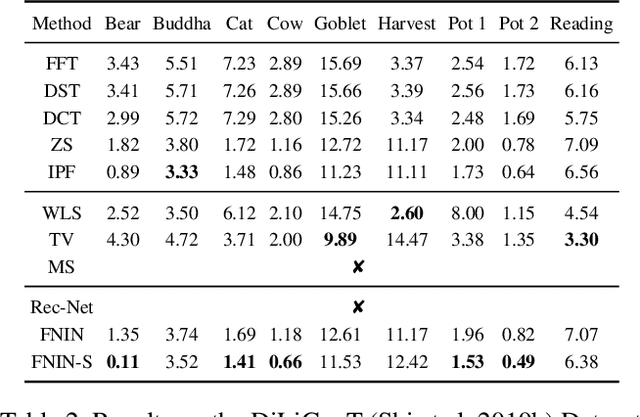
Surface-from-gradients (SfG) aims to recover a three-dimensional (3D) surface from its gradients. Traditional methods encounter significant challenges in achieving high accuracy and handling high-resolution inputs, particularly facing the complex nature of discontinuities and the inefficiencies associated with large-scale linear solvers. Although recent advances in deep learning, such as photometric stereo, have enhanced normal estimation accuracy, they do not fully address the intricacies of gradient-based surface reconstruction. To overcome these limitations, we propose a Fourier neural operator-based Numerical Integration Network (FNIN) within a two-stage optimization framework. In the first stage, our approach employs an iterative architecture for numerical integration, harnessing an advanced Fourier neural operator to approximate the solution operator in Fourier space. Additionally, a self-learning attention mechanism is incorporated to effectively detect and handle discontinuities. In the second stage, we refine the surface reconstruction by formulating a weighted least squares problem, addressing the identified discontinuities rationally. Extensive experiments demonstrate that our method achieves significant improvements in both accuracy and efficiency compared to current state-of-the-art solvers. This is particularly evident in handling high-resolution images with complex data, achieving errors of fewer than 0.1 mm on tested objects.
Image Gradient-Aided Photometric Stereo Network
Dec 16, 2024Photometric stereo (PS) endeavors to ascertain surface normals using shading clues from photometric images under various illuminations. Recent deep learning-based PS methods often overlook the complexity of object surfaces. These neural network models, which exclusively rely on photometric images for training, often produce blurred results in high-frequency regions characterized by local discontinuities, such as wrinkles and edges with significant gradient changes. To address this, we propose the Image Gradient-Aided Photometric Stereo Network (IGA-PSN), a dual-branch framework extracting features from both photometric images and their gradients. Furthermore, we incorporate an hourglass regression network along with supervision to regularize normal regression. Experiments on DiLiGenT benchmarks show that IGA-PSN outperforms previous methods in surface normal estimation, achieving a mean angular error of 6.46 while preserving textures and geometric shapes in complex regions.
* 13 pages, 5 figures, published to Springer
Frequency-Aware Guidance for Blind Image Restoration via Diffusion Models
Nov 19, 2024



Blind image restoration remains a significant challenge in low-level vision tasks. Recently, denoising diffusion models have shown remarkable performance in image synthesis. Guided diffusion models, leveraging the potent generative priors of pre-trained models along with a differential guidance loss, have achieved promising results in blind image restoration. However, these models typically consider data consistency solely in the spatial domain, often resulting in distorted image content. In this paper, we propose a novel frequency-aware guidance loss that can be integrated into various diffusion models in a plug-and-play manner. Our proposed guidance loss, based on 2D discrete wavelet transform, simultaneously enforces content consistency in both the spatial and frequency domains. Experimental results demonstrate the effectiveness of our method in three blind restoration tasks: blind image deblurring, imaging through turbulence, and blind restoration for multiple degradations. Notably, our method achieves a significant improvement in PSNR score, with a remarkable enhancement of 3.72\,dB in image deblurring. Moreover, our method exhibits superior capability in generating images with rich details and reduced distortion, leading to the best visual quality.
RMAFF-PSN: A Residual Multi-Scale Attention Feature Fusion Photometric Stereo Network
Apr 14, 2024
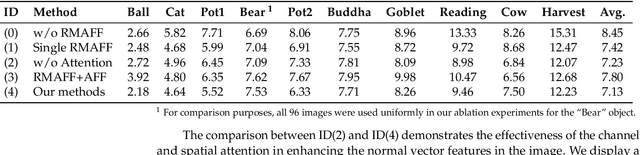

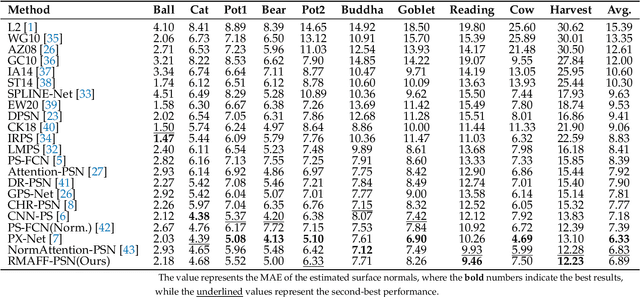
Predicting accurate normal maps of objects from two-dimensional images in regions of complex structure and spatial material variations is challenging using photometric stereo methods due to the influence of surface reflection properties caused by variations in object geometry and surface materials. To address this issue, we propose a photometric stereo network called a RMAFF-PSN that uses residual multiscale attentional feature fusion to handle the ``difficult'' regions of the object. Unlike previous approaches that only use stacked convolutional layers to extract deep features from the input image, our method integrates feature information from different resolution stages and scales of the image. This approach preserves more physical information, such as texture and geometry of the object in complex regions, through shallow-deep stage feature extraction, double branching enhancement, and attention optimization. To test the network structure under real-world conditions, we propose a new real dataset called Simple PS data, which contains multiple objects with varying structures and materials. Experimental results on a publicly available benchmark dataset demonstrate that our method outperforms most existing calibrated photometric stereo methods for the same number of input images, especially in the case of highly non-convex object structures. Our method also obtains good results under sparse lighting conditions.
* 17 pages,12 figures
Deep Learning Methods for Calibrated Photometric Stereo and Beyond: A Survey
Dec 16, 2022



Photometric stereo recovers the surface normals of an object from multiple images with varying shading cues, i.e., modeling the relationship between surface orientation and intensity at each pixel. Photometric stereo prevails in superior per-pixel resolution and fine reconstruction details. However, it is a complicated problem because of the non-linear relationship caused by non-Lambertian surface reflectance. Recently, various deep learning methods have shown a powerful ability in the context of photometric stereo against non-Lambertian surfaces. This paper provides a comprehensive review of existing deep learning-based calibrated photometric stereo methods. We first analyze these methods from different perspectives, including input processing, supervision, and network architecture. We summarize the performance of deep learning photometric stereo models on the most widely-used benchmark data set. This demonstrates the advanced performance of deep learning-based photometric stereo methods. Finally, we give suggestions and propose future research trends based on the limitations of existing models.