 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZipGait: Bridging Skeleton and Silhouette with Diffusion Model for Advancing Gait Recognition
Aug 22, 2024Current gait recognition research predominantly focuses on extracting appearance features effectively, but the performance is severely compromised by the vulnerability of silhouettes under unconstrained scenes. Consequently, numerous studies have explored how to harness information from various models, particularly by sufficiently utilizing the intrinsic information of skeleton sequences. While these model-based methods have achieved significant performance, there is still a huge gap compared to appearance-based methods, which implies the potential value of bridging silhouettes and skeletons. In this work, we make the first attempt to reconstruct dense body shapes from discrete skeleton distributions via the diffusion model, demonstrating a new approach that connects cross-modal features rather than focusing solely on intrinsic features to improve model-based methods. To realize this idea, we propose a novel gait diffusion model named DiffGait, which has been designed with four specific adaptations suitable for gait recognition. Furthermore, to effectively utilize the reconstructed silhouettes and skeletons, we introduce Perception Gait Integration (PGI) to integrate different gait features through a two-stage process. Incorporating those modifications leads to an efficient model-based gait recognition framework called ZipGait. Through extensive experiments on four public benchmarks, ZipGait demonstrates superior performance, outperforming the state-of-the-art methods by a large margin under both cross-domain and intra-domain settings, while achieving significant plug-and-play performance improvements.
GaitMA: Pose-guided Multi-modal Feature Fusion for Gait Recognition
Jul 20, 2024Gait recognition is a biometric technology that recognizes the identity of humans through their walking patterns. Existing appearance-based methods utilize CNN or Transformer to extract spatial and temporal features from silhouettes, while model-based methods employ GCN to focus on the special topological structure of skeleton points. However, the quality of silhouettes is limited by complex occlusions, and skeletons lack dense semantic features of the human body. To tackle these problems, we propose a novel gait recognition framework, dubbed Gait Multi-model Aggregation Network (GaitMA), which effectively combines two modalities to obtain a more robust and comprehensive gait representation for recognition. First, skeletons are represented by joint/limb-based heatmaps, and features from silhouettes and skeletons are respectively extracted using two CNN-based feature extractors. Second, a co-attention alignment module is proposed to align the features by element-wise attention. Finally, we propose a mutual learning module, which achieves feature fusion through cross-attention, Wasserstein loss is further introduced to ensure the effective fusion of two modalities. Extensive experimental results demonstrate the superiority of our model on Gait3D, OU-MVLP, and CASIA-B.
CLIP-Hand3D: Exploiting 3D Hand Pose Estimation via Context-Aware Prompting
Sep 28, 2023



Contrastive Language-Image Pre-training (CLIP) starts to emerge in many computer vision tasks and has achieved promising performance. However, it remains underexplored whether CLIP can be generalized to 3D hand pose estimation, as bridging text prompts with pose-aware features presents significant challenges due to the discrete nature of joint positions in 3D space. In this paper, we make one of the first attempts to propose a novel 3D hand pose estimator from monocular images, dubbed as CLIP-Hand3D, which successfully bridges the gap between text prompts and irregular detailed pose distribution. In particular, the distribution order of hand joints in various 3D space directions is derived from pose labels, forming corresponding text prompts that are subsequently encoded into text representations. Simultaneously, 21 hand joints in the 3D space are retrieved, and their spatial distribution (in x, y, and z axes) is encoded to form pose-aware features. Subsequently, we maximize semantic consistency for a pair of pose-text features following a CLIP-based contrastive learning paradigm. Furthermore, a coarse-to-fine mesh regressor is designed, which is capable of effectively querying joint-aware cues from the feature pyramid. Extensive experiments on several public hand benchmarks show that the proposed model attains a significantly faster inference speed while achieving state-of-the-art performance compared to methods utilizing the similar scale backbone.
Incorporating Lambertian Priors into Surface Normals Measurement
Jul 15, 2021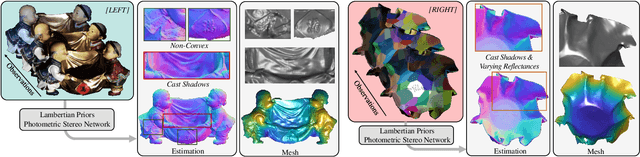
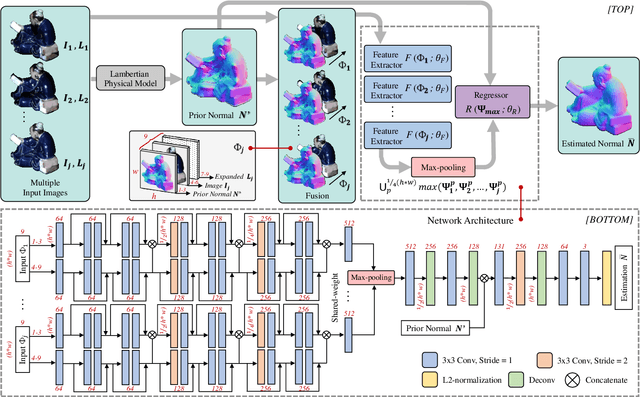
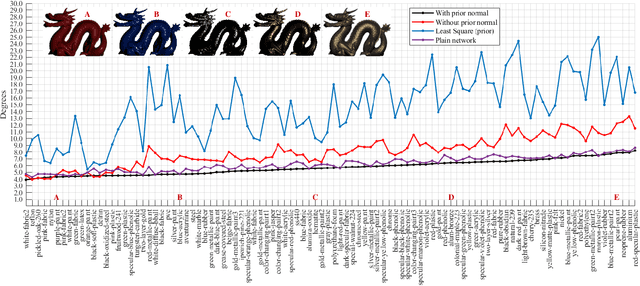
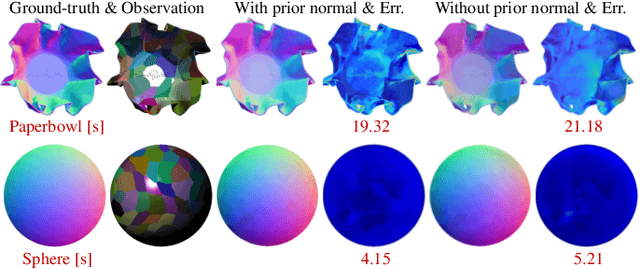
The goal of photometric stereo is to measure the precise surface normal of a 3D object from observations with various shading cues. However, non-Lambertian surfaces influence the measurement accuracy due to irregular shading cues. Despite deep neural networks have been employed to simulate the performance of non-Lambertian surfaces, the error in specularities, shadows, and crinkle regions is hard to be reduced. In order to address this challenge, we here propose a photometric stereo network that incorporates Lambertian priors to better measure the surface normal. In this paper, we use the initial normal under the Lambertian assumption as the prior information to refine the normal measurement, instead of solely applying the observed shading cues to deriving the surface normal. Our method utilizes the Lambertian information to reparameterize the network weights and the powerful fitting ability of deep neural networks to correct these errors caused by general reflectance properties. Our explorations include: the Lambertian priors (1) reduce the learning hypothesis space, making our method learn the mapping in the same surface normal space and improving the accuracy of learning, and (2) provides the differential features learning, improving the surfaces reconstruction of details. Extensive experiments verify the effectiveness of the proposed Lambertian prior photometric stereo network in accurate surface normal measurement, on the challenging benchmark dataset.