 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaCoVL-FER: Landmark-Guided Contrastive Learning Network with Vision-Language Enhancement for Facial Expression Recognition
May 19, 2026Facial Expression Recognition (FER) in the wild is still challenging due to uncontrolled variations in pose, occlusion, and illumination. Most existing attention-based methods primarily rely on visual appearance cues, suffering from attention redundancy and instability, which limits their performance in complex scenarios. To address these issues, we propose a novel landmark-guided contrastive learning network with vision-language enhancement for FER (LaCoVL-FER), which integrates geometric priors from facial landmarks and semantic priors from a vision-language model. Specifically, a Landmark-Guided Adaptive Encoder (LGAE) is designed to introduce geometric priors through a Bi-branch Gated Cross Attention (BGCA) mechanism, which achieves adaptive fusion of landmark-based geometric and visual appearance features to produce expression-relevant features, thereby focusing on key facial regions and suppressing noise interference. In parallel, a Vision-Language Enhancement Strategy (VLES) is presented to leverage the expression-relevant features to refine the generalizable visual features extracted by the frozen pretrained CLIP image encoder, yielding expression-specific visual representations. Based on these representations, an Expression-Conditioned Prompting (ECP) mechanism is utilized to further adapt the textual features of fixed class-level prompts from the frozen pretrained CLIP text encoder, generating more instance-aware textual representations. These visual-textual representations are aligned as semantic priors to enhance the robustness and generalization of FER. Quantitative and qualitative experiments demonstrate that our LaCoVL-FER outperforms state-of-the-art methods on three representative real-world FER datasets, including RAF-DB, FERPlus, and AffectNet. The code is available at https://github.com/ylin06804/LaCoVL-FER.
A Lung Nodule Dataset with Histopathology-based Cancer Type Annotation
Jun 26, 2024Recently, Computer-Aided Diagnosis (CAD) systems have emerged as indispensable tools in clinical diagnostic workflows, significantly alleviating the burden on radiologists. Nevertheless, despite their integration into clinical settings, CAD systems encounter limitations. Specifically, while CAD systems can achieve high performance in the detection of lung nodules, they face challenges in accurately predicting multiple cancer types. This limitation can be attributed to the scarcity of publicly available datasets annotated with expert-level cancer type information. This research aims to bridge this gap by providing publicly accessible datasets and reliable tools for medical diagnosis, facilitating a finer categorization of different types of lung diseases so as to offer precise treatment recommendations. To achieve this objective, we curated a diverse dataset of lung Computed Tomography (CT) images, comprising 330 annotated nodules (nodules are labeled as bounding boxes) from 95 distinct patients. The quality of the dataset was evaluated using a variety of classical classification and detection models, and these promising results demonstrate that the dataset has a feasible application and further facilitate intelligent auxiliary diagnosis.
A Cross Spatio-Temporal Pathology-based Lung Nodule Dataset
Jun 26, 2024Recently, intelligent analysis of lung nodules with the assistant of computer aided detection (CAD) techniques can improve the accuracy rate of lung cancer diagnosis. However, existing CAD systems and pulmonary datasets mainly focus on Computed Tomography (CT) images from one single period, while ignoring the cross spatio-temporal features associated with the progression of nodules contained in imaging data from various captured periods of lung cancer. If the evolution patterns of nodules across various periods in the patients' CT sequences can be explored, it will play a crucial role in guiding the precise screening identification of lung cancer. Therefore, a cross spatio-temporal lung nodule dataset with pathological information for nodule identification and diagnosis is constructed, which contains 328 CT sequences and 362 annotated nodules from 109 patients. This comprehensive database is intended to drive research in the field of CAD towards more practical and robust methods, and also contribute to the further exploration of precision medicine related field. To ensure patient confidentiality, we have removed sensitive information from the dataset.
A Comprehensive Survey on Video Saliency Detection with Auditory Information: the Audio-visual Consistency Perceptual is the Key!
Jun 20, 2022
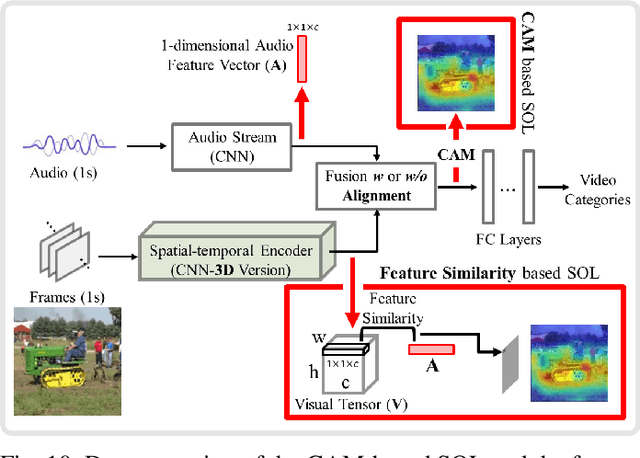
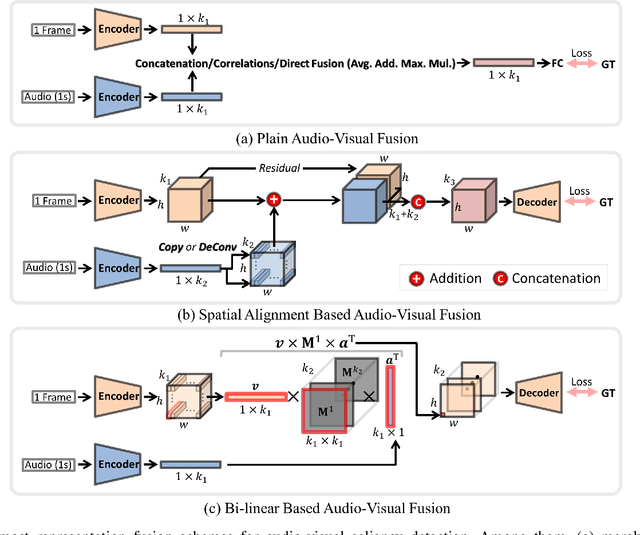
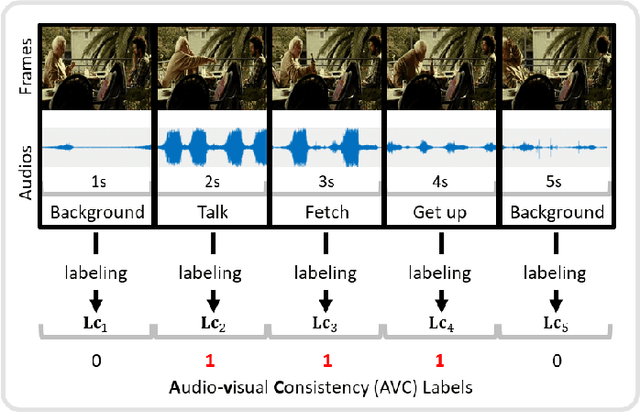
Video saliency detection (VSD) aims at fast locating the most attractive objects/things/patterns in a given video clip. Existing VSD-related works have mainly relied on the visual system but paid less attention to the audio aspect, while, actually, our audio system is the most vital complementary part to our visual system. Also, audio-visual saliency detection (AVSD), one of the most representative research topics for mimicking human perceptual mechanisms, is currently in its infancy, and none of the existing survey papers have touched on it, especially from the perspective of saliency detection. Thus, the ultimate goal of this paper is to provide an extensive review to bridge the gap between audio-visual fusion and saliency detection. In addition, as another highlight of this review, we have provided a deep insight into key factors which could directly determine the performances of AVSD deep models, and we claim that the audio-visual consistency degree (AVC) -- a long-overlooked issue, can directly influence the effectiveness of using audio to benefit its visual counterpart when performing saliency detection. Moreover, in order to make the AVC issue more practical and valuable for future followers, we have newly equipped almost all existing publicly available AVSD datasets with additional frame-wise AVC labels. Based on these upgraded datasets, we have conducted extensive quantitative evaluations to ground our claim on the importance of AVC in the AVSD task. In a word, both our ideas and new sets serve as a convenient platform with preliminaries and guidelines, all of which are very potential to facilitate future works in promoting state-of-the-art (SOTA) performance further.
Incorporating Lambertian Priors into Surface Normals Measurement
Jul 15, 2021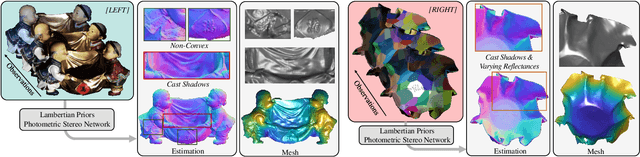
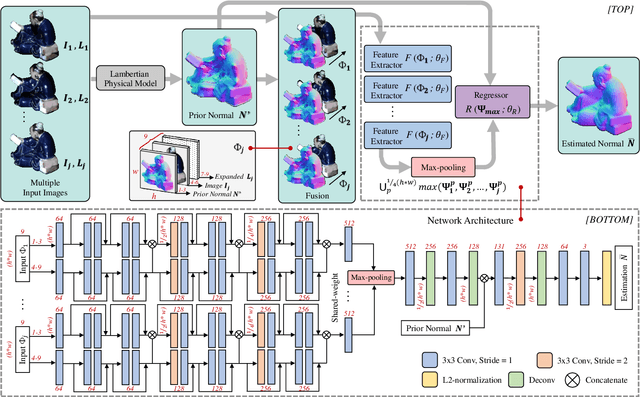
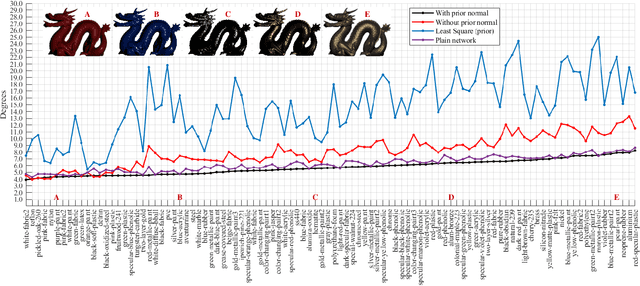
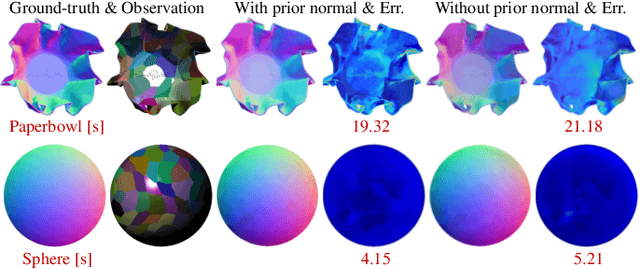
The goal of photometric stereo is to measure the precise surface normal of a 3D object from observations with various shading cues. However, non-Lambertian surfaces influence the measurement accuracy due to irregular shading cues. Despite deep neural networks have been employed to simulate the performance of non-Lambertian surfaces, the error in specularities, shadows, and crinkle regions is hard to be reduced. In order to address this challenge, we here propose a photometric stereo network that incorporates Lambertian priors to better measure the surface normal. In this paper, we use the initial normal under the Lambertian assumption as the prior information to refine the normal measurement, instead of solely applying the observed shading cues to deriving the surface normal. Our method utilizes the Lambertian information to reparameterize the network weights and the powerful fitting ability of deep neural networks to correct these errors caused by general reflectance properties. Our explorations include: the Lambertian priors (1) reduce the learning hypothesis space, making our method learn the mapping in the same surface normal space and improving the accuracy of learning, and (2) provides the differential features learning, improving the surfaces reconstruction of details. Extensive experiments verify the effectiveness of the proposed Lambertian prior photometric stereo network in accurate surface normal measurement, on the challenging benchmark dataset.
Cascade one-vs-rest detection network for fine-grained recognition without part annotations
Aug 23, 2017

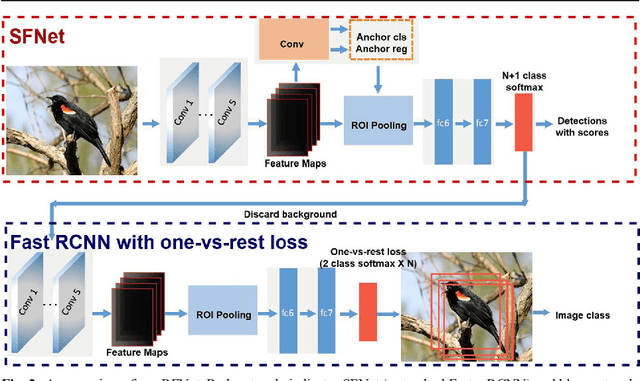

Fine-grained recognition is a challenging task due to the small intra-category variances. Most of top-performing fine-grained recognition methods leverage parts of objects for better performance. Therefore, part annotations which are extremely computationally expensive are required. In this paper, we propose a novel cascaded deep CNN detection framework for fine-grained recognition which is trained to detect the whole object without considering parts. Nevertheless, most of current top-performing detection networks use the N+1 class (N object categories plus background) softmax loss, and the background category with much more training samples dominates the feature learning progress so that the features are not good for object categories with fewer samples. To bridge this gap, we introduce a cascaded structure to eliminate background and exploit a one-vs-rest loss to capture more minute variances among different subordinate categories. Experiments show that our proposed recognition framework achieves comparable performance with state-of-the-art, part-free, fine-grained recognition methods on the CUB-200-2011 Bird dataset. Moreover, our method even outperforms most of part-based methods while does not need part annotations at the training stage and is free from any annotations at test stage.