 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhere Not to Learn: Prior-Aligned Training with Subset-based Attribution Constraints for Reliable Decision-Making
Jan 30, 2026Reliable models should not only predict correctly, but also justify decisions with acceptable evidence. Yet conventional supervised learning typically provides only class-level labels, allowing models to achieve high accuracy through shortcut correlations rather than the intended evidence. Human priors can help constrain such behavior, but aligning models to these priors remains challenging because learned representations often diverge from human perception. To address this challenge, we propose an attribution-based human prior alignment method. We encode human priors as input regions that the model is expected to rely on (e.g., bounding boxes), and leverage a highly faithful subset-selection-based attribution approach to expose the model's decision evidence during training. When the attribution region deviates substantially from the prior regions, we penalize reliance on off-prior evidence, encouraging the model to shift its attribution toward the intended regions. This is achieved through a training objective that imposes attribution constraints induced by the human prior. We validate our method on both image classification and click decision tasks in MLLM-based GUI agent models. Across conventional classification and autoregressive generation settings, human prior alignment consistently improves task accuracy while also enhancing the model's decision reasonability.
CoDS: Collaborative Perception via Digital Semantic Communication
Dec 27, 2025Semantic communication has been introduced into collaborative perception systems for autonomous driving, offering a promising approach to enhancing data transmission efficiency and robustness. Despite its potential, existing semantic communication approaches predominantly rely on analog transmission models, rendering these systems fundamentally incompatible with the digital architecture of modern vehicle-to-everything (V2X) networks and posing a significant barrier to real-world deployment. To bridge this critical gap, we propose CoDS, a novel collaborative perception framework based on digital semantic communication, designed to realize semantic-level transmission efficiency within practical digital communication systems. Specifically, we develop a semantic compression codec that extracts and compresses task-oriented semantic features while preserving downstream perception accuracy. Building on this, we propose a novel semantic analog-to-digital converter that converts these continuous semantic features into a discrete bitstream, ensuring integration with existing digital communication pipelines. Furthermore, we develop an uncertainty-aware network (UAN) that assesses the reliability of each received feature and discards those corrupted by decoding failures, thereby mitigating the cliff effect of conventional channel coding schemes under low signal-to-noise ratio (SNR) conditions. Extensive experiments demonstrate that CoDS significantly outperforms existing semantic communication and traditional digital communication schemes, achieving state-of-the-art perception performance while ensuring compatibility with practical digital V2X systems.
PhaseWin Search Framework Enable Efficient Object-Level Interpretation
Nov 14, 2025Attribution is essential for interpreting object-level foundation models. Recent methods based on submodular subset selection have achieved high faithfulness, but their efficiency limitations hinder practical deployment in real-world scenarios. To address this, we propose PhaseWin, a novel phase-window search algorithm that enables faithful region attribution with near-linear complexity. PhaseWin replaces traditional quadratic-cost greedy selection with a phased coarse-to-fine search, combining adaptive pruning, windowed fine-grained selection, and dynamic supervision mechanisms to closely approximate greedy behavior while dramatically reducing model evaluations. Theoretically, PhaseWin retains near-greedy approximation guarantees under mild monotone submodular assumptions. Empirically, PhaseWin achieves over 95% of greedy attribution faithfulness using only 20% of the computational budget, and consistently outperforms other attribution baselines across object detection and visual grounding tasks with Grounding DINO and Florence-2. PhaseWin establishes a new state of the art in scalable, high-faithfulness attribution for object-level multimodal models.
Where MLLMs Attend and What They Rely On: Explaining Autoregressive Token Generation
Sep 26, 2025Multimodal large language models (MLLMs) have demonstrated remarkable capabilities in aligning visual inputs with natural language outputs. Yet, the extent to which generated tokens depend on visual modalities remains poorly understood, limiting interpretability and reliability. In this work, we present EAGLE, a lightweight black-box framework for explaining autoregressive token generation in MLLMs. EAGLE attributes any selected tokens to compact perceptual regions while quantifying the relative influence of language priors and perceptual evidence. The framework introduces an objective function that unifies sufficiency (insight score) and indispensability (necessity score), optimized via greedy search over sparsified image regions for faithful and efficient attribution. Beyond spatial attribution, EAGLE performs modality-aware analysis that disentangles what tokens rely on, providing fine-grained interpretability of model decisions. Extensive experiments across open-source MLLMs show that EAGLE consistently outperforms existing methods in faithfulness, localization, and hallucination diagnosis, while requiring substantially less GPU memory. These results highlight its effectiveness and practicality for advancing the interpretability of MLLMs. The code is available at https://github.com/RuoyuChen10/EAGLE.
The Emotional Baby Is Truly Deadly: Does your Multimodal Large Reasoning Model Have Emotional Flattery towards Humans?
Aug 06, 2025We observe that MLRMs oriented toward human-centric service are highly susceptible to user emotional cues during the deep-thinking stage, often overriding safety protocols or built-in safety checks under high emotional intensity. Inspired by this key insight, we propose EmoAgent, an autonomous adversarial emotion-agent framework that orchestrates exaggerated affective prompts to hijack reasoning pathways. Even when visual risks are correctly identified, models can still produce harmful completions through emotional misalignment. We further identify persistent high-risk failure modes in transparent deep-thinking scenarios, such as MLRMs generating harmful reasoning masked behind seemingly safe responses. These failures expose misalignments between internal inference and surface-level behavior, eluding existing content-based safeguards. To quantify these risks, we introduce three metrics: (1) Risk-Reasoning Stealth Score (RRSS) for harmful reasoning beneath benign outputs; (2) Risk-Visual Neglect Rate (RVNR) for unsafe completions despite visual risk recognition; and (3) Refusal Attitude Inconsistency (RAIC) for evaluating refusal unstability under prompt variants. Extensive experiments on advanced MLRMs demonstrate the effectiveness of EmoAgent and reveal deeper emotional cognitive misalignments in model safety behavior.
SComCP: Task-Oriented Semantic Communication for Collaborative Perception
Jul 01, 2025Reliable detection of surrounding objects is critical for the safe operation of connected automated vehicles (CAVs). However, inherent limitations such as the restricted perception range and occlusion effects compromise the reliability of single-vehicle perception systems in complex traffic environments. Collaborative perception has emerged as a promising approach by fusing sensor data from surrounding CAVs with diverse viewpoints, thereby improving environmental awareness. Although collaborative perception holds great promise, its performance is bottlenecked by wireless communication constraints, as unreliable and bandwidth-limited channels hinder the transmission of sensor data necessary for real-time perception. To address these challenges, this paper proposes SComCP, a novel task-oriented semantic communication framework for collaborative perception. Specifically, SComCP integrates an importance-aware feature selection network that selects and transmits semantic features most relevant to the perception task, significantly reducing communication overhead without sacrificing accuracy. Furthermore, we design a semantic codec network based on a joint source and channel coding (JSCC) architecture, which enables bidirectional transformation between semantic features and noise-tolerant channel symbols, thereby ensuring stable perception under adverse wireless conditions. Extensive experiments demonstrate the effectiveness of the proposed framework. In particular, compared to existing approaches, SComCP can maintain superior perception performance across various channel conditions, especially in low signal-to-noise ratio (SNR) scenarios. In addition, SComCP exhibits strong generalization capability, enabling the framework to maintain high performance across diverse channel conditions, even when trained with a specific channel model.
3D Scene-Camera Representation with Joint Camera Photometric Optimization
Jun 26, 2025Representing scenes from multi-view images is a crucial task in computer vision with extensive applications. However, inherent photometric distortions in the camera imaging can significantly degrade image quality. Without accounting for these distortions, the 3D scene representation may inadvertently incorporate erroneous information unrelated to the scene, diminishing the quality of the representation. In this paper, we propose a novel 3D scene-camera representation with joint camera photometric optimization. By introducing internal and external photometric model, we propose a full photometric model and corresponding camera representation. Based on simultaneously optimizing the parameters of the camera representation, the proposed method effectively separates scene-unrelated information from the 3D scene representation. Additionally, during the optimization of the photometric parameters, we introduce a depth regularization to prevent the 3D scene representation from fitting scene-unrelated information. By incorporating the camera model as part of the mapping process, the proposed method constructs a complete map that includes both the scene radiance field and the camera photometric model. Experimental results demonstrate that the proposed method can achieve high-quality 3D scene representations, even under conditions of imaging degradation, such as vignetting and dirt.
Unpacking Positional Encoding in Transformers: A Spectral Analysis of Content-Position Coupling
May 19, 2025Positional encoding (PE) is essential for enabling Transformers to model sequential structure. However, the mechanisms by which different PE schemes couple token content and positional information-and how these mechanisms influence model dynamics-remain theoretically underexplored. In this work, we present a unified framework that analyzes PE through the spectral properties of Toeplitz and related matrices derived from attention logits. We show that multiplicative content-position coupling-exemplified by Rotary Positional Encoding (RoPE) via a Hadamard product with a Toeplitz matrix-induces spectral contraction, which theoretically improves optimization stability and efficiency. Guided by this theory, we construct synthetic tasks that contrast content-position dependent and content-position independent settings, and evaluate a range of PE methods. Our experiments reveal strong alignment with theory: RoPE consistently outperforms other methods on position-sensitive tasks and induces "single-head deposit" patterns in early layers, indicating localized positional processing. Further analyses show that modifying the method and timing of PE coupling, such as MLA in Deepseek-V3, can effectively mitigate this concentration. These results establish explicit content-relative mixing with relative-position Toeplitz signals as a key principle for effective PE design and provide new insight into how positional structure is integrated in Transformer architectures.
Photovoltaic Defect Image Generator with Boundary Alignment Smoothing Constraint for Domain Shift Mitigation
May 09, 2025Accurate defect detection of photovoltaic (PV) cells is critical for ensuring quality and efficiency in intelligent PV manufacturing systems. However, the scarcity of rich defect data poses substantial challenges for effective model training. While existing methods have explored generative models to augment datasets, they often suffer from instability, limited diversity, and domain shifts. To address these issues, we propose PDIG, a Photovoltaic Defect Image Generator based on Stable Diffusion (SD). PDIG leverages the strong priors learned from large-scale datasets to enhance generation quality under limited data. Specifically, we introduce a Semantic Concept Embedding (SCE) module that incorporates text-conditioned priors to capture the relational concepts between defect types and their appearances. To further enrich the domain distribution, we design a Lightweight Industrial Style Adaptor (LISA), which injects industrial defect characteristics into the SD model through cross-disentangled attention. At inference, we propose a Text-Image Dual-Space Constraints (TIDSC) module, enforcing the quality of generated images via positional consistency and spatial smoothing alignment. Extensive experiments demonstrate that PDIG achieves superior realism and diversity compared to state-of-the-art methods. Specifically, our approach improves Frechet Inception Distance (FID) by 19.16 points over the second-best method and significantly enhances the performance of downstream defect detection tasks.
FaceInsight: A Multimodal Large Language Model for Face Perception
Apr 22, 2025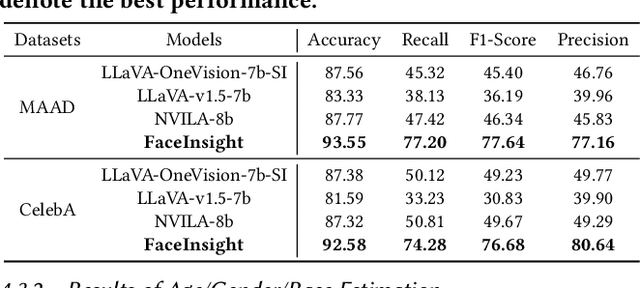
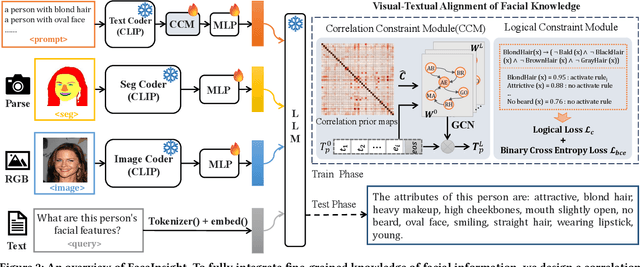
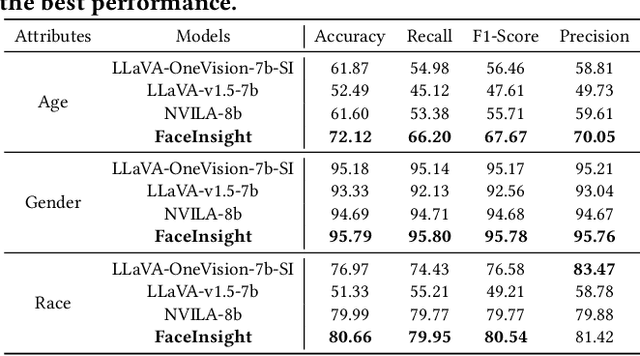
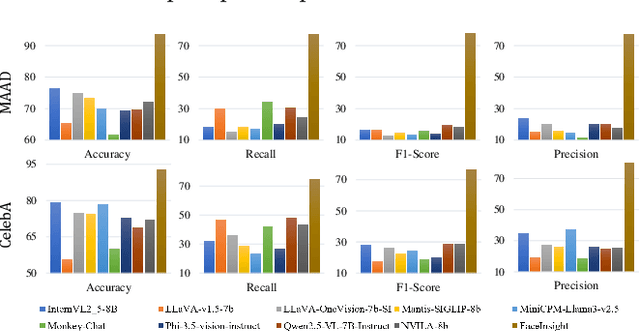
Recent advances in multimodal large language models (MLLMs) have demonstrated strong capabilities in understanding general visual content. However, these general-domain MLLMs perform poorly in face perception tasks, often producing inaccurate or misleading responses to face-specific queries. To address this gap, we propose FaceInsight, the versatile face perception MLLM that provides fine-grained facial information. Our approach introduces visual-textual alignment of facial knowledge to model both uncertain dependencies and deterministic relationships among facial information, mitigating the limitations of language-driven reasoning. Additionally, we incorporate face segmentation maps as an auxiliary perceptual modality, enriching the visual input with localized structural cues to enhance semantic understanding. Comprehensive experiments and analyses across three face perception tasks demonstrate that FaceInsight consistently outperforms nine compared MLLMs under both training-free and fine-tuned settings.