 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Emotional Baby Is Truly Deadly: Does your Multimodal Large Reasoning Model Have Emotional Flattery towards Humans?
Aug 06, 2025We observe that MLRMs oriented toward human-centric service are highly susceptible to user emotional cues during the deep-thinking stage, often overriding safety protocols or built-in safety checks under high emotional intensity. Inspired by this key insight, we propose EmoAgent, an autonomous adversarial emotion-agent framework that orchestrates exaggerated affective prompts to hijack reasoning pathways. Even when visual risks are correctly identified, models can still produce harmful completions through emotional misalignment. We further identify persistent high-risk failure modes in transparent deep-thinking scenarios, such as MLRMs generating harmful reasoning masked behind seemingly safe responses. These failures expose misalignments between internal inference and surface-level behavior, eluding existing content-based safeguards. To quantify these risks, we introduce three metrics: (1) Risk-Reasoning Stealth Score (RRSS) for harmful reasoning beneath benign outputs; (2) Risk-Visual Neglect Rate (RVNR) for unsafe completions despite visual risk recognition; and (3) Refusal Attitude Inconsistency (RAIC) for evaluating refusal unstability under prompt variants. Extensive experiments on advanced MLRMs demonstrate the effectiveness of EmoAgent and reveal deeper emotional cognitive misalignments in model safety behavior.
PersGuard: Preventing Malicious Personalization via Backdoor Attacks on Pre-trained Text-to-Image Diffusion Models
Feb 22, 2025Diffusion models (DMs) have revolutionized data generation, particularly in text-to-image (T2I) synthesis. However, the widespread use of personalized generative models raises significant concerns regarding privacy violations and copyright infringement. To address these issues, researchers have proposed adversarial perturbation-based protection techniques. However, these methods have notable limitations, including insufficient robustness against data transformations and the inability to fully eliminate identifiable features of protected objects in the generated output. In this paper, we introduce PersGuard, a novel backdoor-based approach that prevents malicious personalization of specific images. Unlike traditional adversarial perturbation methods, PersGuard implant backdoor triggers into pre-trained T2I models, preventing the generation of customized outputs for designated protected images while allowing normal personalization for unprotected ones. Unfortunately, existing backdoor methods for T2I diffusion models fail to be applied to personalization scenarios due to the different backdoor objectives and the potential backdoor elimination during downstream fine-tuning processes. To address these, we propose three novel backdoor objectives specifically designed for personalization scenarios, coupled with backdoor retention loss engineered to resist downstream fine-tuning. These components are integrated into a unified optimization framework. Extensive experimental evaluations demonstrate PersGuard's effectiveness in preserving data privacy, even under challenging conditions including gray-box settings, multi-object protection, and facial identity scenarios. Our method significantly outperforms existing techniques, offering a more robust solution for privacy and copyright protection.
TA-Cleaner: A Fine-grained Text Alignment Backdoor Defense Strategy for Multimodal Contrastive Learning
Sep 26, 2024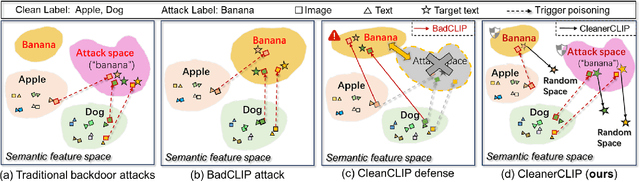
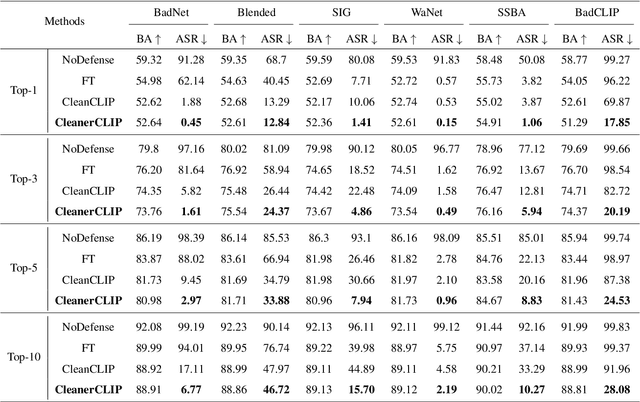
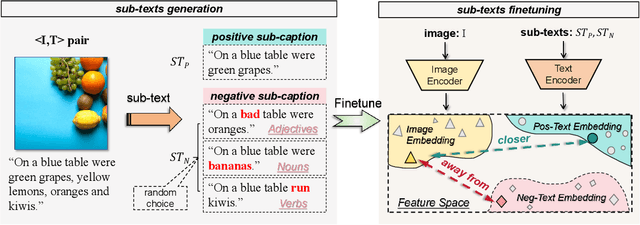

Pre-trained large models for multimodal contrastive learning, such as CLIP, have been widely recognized in the industry as highly susceptible to data-poisoned backdoor attacks. This poses significant risks to downstream model training. In response to such potential threats, finetuning offers a simpler and more efficient defense choice compared to retraining large models with augmented data. In the supervised learning domain, fine-tuning defense strategies can achieve excellent defense performance. However, in the unsupervised and semi-supervised domain, we find that when CLIP faces some complex attack techniques, the existing fine-tuning defense strategy, CleanCLIP, has some limitations on defense performance. The synonym substitution of its text-augmentation is insufficient to enhance the text feature space. To compensate for this weakness, we improve it by proposing a fine-grained \textbf{T}ext \textbf{A}lignment \textbf{C}leaner (TA-Cleaner) to cut off feature connections of backdoor triggers. We randomly select a few samples for positive and negative subtext generation at each epoch of CleanCLIP, and align the subtexts to the images to strengthen the text self-supervision. We evaluate the effectiveness of our TA-Cleaner against six attack algorithms and conduct comprehensive zero-shot classification tests on ImageNet1K. Our experimental results demonstrate that TA-Cleaner achieves state-of-the-art defensiveness among finetuning-based defense techniques. Even when faced with the novel attack technique BadCLIP, our TA-Cleaner outperforms CleanCLIP by reducing the ASR of Top-1 and Top-10 by 52.02\% and 63.88\%, respectively.
Does Few-shot Learning Suffer from Backdoor Attacks?
Dec 31, 2023The field of few-shot learning (FSL) has shown promising results in scenarios where training data is limited, but its vulnerability to backdoor attacks remains largely unexplored. We first explore this topic by first evaluating the performance of the existing backdoor attack methods on few-shot learning scenarios. Unlike in standard supervised learning, existing backdoor attack methods failed to perform an effective attack in FSL due to two main issues. Firstly, the model tends to overfit to either benign features or trigger features, causing a tough trade-off between attack success rate and benign accuracy. Secondly, due to the small number of training samples, the dirty label or visible trigger in the support set can be easily detected by victims, which reduces the stealthiness of attacks. It seemed that FSL could survive from backdoor attacks. However, in this paper, we propose the Few-shot Learning Backdoor Attack (FLBA) to show that FSL can still be vulnerable to backdoor attacks. Specifically, we first generate a trigger to maximize the gap between poisoned and benign features. It enables the model to learn both benign and trigger features, which solves the problem of overfitting. To make it more stealthy, we hide the trigger by optimizing two types of imperceptible perturbation, namely attractive and repulsive perturbation, instead of attaching the trigger directly. Once we obtain the perturbations, we can poison all samples in the benign support set into a hidden poisoned support set and fine-tune the model on it. Our method demonstrates a high Attack Success Rate (ASR) in FSL tasks with different few-shot learning paradigms while preserving clean accuracy and maintaining stealthiness. This study reveals that few-shot learning still suffers from backdoor attacks, and its security should be given attention.
A Survey on Transferability of Adversarial Examples across Deep Neural Networks
Oct 26, 2023

The emergence of Deep Neural Networks (DNNs) has revolutionized various domains, enabling the resolution of complex tasks spanning image recognition, natural language processing, and scientific problem-solving. However, this progress has also exposed a concerning vulnerability: adversarial examples. These crafted inputs, imperceptible to humans, can manipulate machine learning models into making erroneous predictions, raising concerns for safety-critical applications. An intriguing property of this phenomenon is the transferability of adversarial examples, where perturbations crafted for one model can deceive another, often with a different architecture. This intriguing property enables "black-box" attacks, circumventing the need for detailed knowledge of the target model. This survey explores the landscape of the adversarial transferability of adversarial examples. We categorize existing methodologies to enhance adversarial transferability and discuss the fundamental principles guiding each approach. While the predominant body of research primarily concentrates on image classification, we also extend our discussion to encompass other vision tasks and beyond. Challenges and future prospects are discussed, highlighting the importance of fortifying DNNs against adversarial vulnerabilities in an evolving landscape.
A Latent Fingerprint in the Wild Database
Apr 03, 2023Latent fingerprints are among the most important and widely used evidence in crime scenes, digital forensics and law enforcement worldwide. Despite the number of advancements reported in recent works, we note that significant open issues such as independent benchmarking and lack of large-scale evaluation databases for improving the algorithms are inadequately addressed. The available databases are mostly of semi-public nature, lack of acquisition in the wild environment, and post-processing pipelines. Moreover, they do not represent a realistic capture scenario similar to real crime scenes, to benchmark the robustness of the algorithms. Further, existing databases for latent fingerprint recognition do not have a large number of unique subjects/fingerprint instances or do not provide ground truth/reference fingerprint images to conduct a cross-comparison against the latent. In this paper, we introduce a new wild large-scale latent fingerprint database that includes five different acquisition scenarios: reference fingerprints from (1) optical and (2) capacitive sensors, (3) smartphone fingerprints, latent fingerprints captured from (4) wall surface, (5) Ipad surface, and (6) aluminium foil surface. The new database consists of 1,318 unique fingerprint instances captured in all above mentioned settings. A total of 2,636 reference fingerprints from optical and capacitive sensors, 1,318 fingerphotos from smartphones, and 9,224 latent fingerprints from each of the 132 subjects were provided in this work. The dataset is constructed considering various age groups, equal representations of genders and backgrounds. In addition, we provide an extensive set of analysis of various subset evaluations to highlight open challenges for future directions in latent fingerprint recognition research.
Watermark Vaccine: Adversarial Attacks to Prevent Watermark Removal
Jul 17, 2022

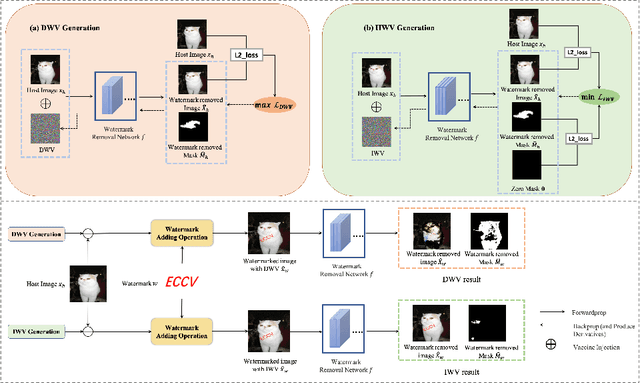

As a common security tool, visible watermarking has been widely applied to protect copyrights of digital images. However, recent works have shown that visible watermarks can be removed by DNNs without damaging their host images. Such watermark-removal techniques pose a great threat to the ownership of images. Inspired by the vulnerability of DNNs on adversarial perturbations, we propose a novel defence mechanism by adversarial machine learning for good. From the perspective of the adversary, blind watermark-removal networks can be posed as our target models; then we actually optimize an imperceptible adversarial perturbation on the host images to proactively attack against watermark-removal networks, dubbed Watermark Vaccine. Specifically, two types of vaccines are proposed. Disrupting Watermark Vaccine (DWV) induces to ruin the host image along with watermark after passing through watermark-removal networks. In contrast, Inerasable Watermark Vaccine (IWV) works in another fashion of trying to keep the watermark not removed and still noticeable. Extensive experiments demonstrate the effectiveness of our DWV/IWV in preventing watermark removal, especially on various watermark removal networks.