 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Multimodal Metaphor Understanding: A Chinese Dataset and Model for Metaphor Mapping Identification
Jan 05, 2025



Metaphors play a crucial role in human communication, yet their comprehension remains a significant challenge for natural language processing (NLP) due to the cognitive complexity involved. According to Conceptual Metaphor Theory (CMT), metaphors map a target domain onto a source domain, and understanding this mapping is essential for grasping the nature of metaphors. While existing NLP research has focused on tasks like metaphor detection and sentiment analysis of metaphorical expressions, there has been limited attention to the intricate process of identifying the mappings between source and target domains. Moreover, non-English multimodal metaphor resources remain largely neglected in the literature, hindering a deeper understanding of the key elements involved in metaphor interpretation. To address this gap, we developed a Chinese multimodal metaphor advertisement dataset (namely CM3D) that includes annotations of specific target and source domains. This dataset aims to foster further research into metaphor comprehension, particularly in non-English languages. Furthermore, we propose a Chain-of-Thought (CoT) Prompting-based Metaphor Mapping Identification Model (CPMMIM), which simulates the human cognitive process for identifying these mappings. Drawing inspiration from CoT reasoning and Bi-Level Optimization (BLO), we treat the task as a hierarchical identification problem, enabling more accurate and interpretable metaphor mapping. Our experimental results demonstrate the effectiveness of CPMMIM, highlighting its potential for advancing metaphor comprehension in NLP. Our dataset and code are both publicly available to encourage further advancements in this field.
Development of Automated Neural Network Prediction for Echocardiographic Left ventricular Ejection Fraction
Mar 18, 2024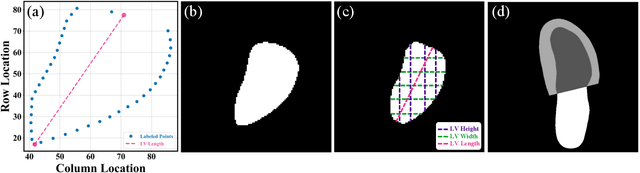

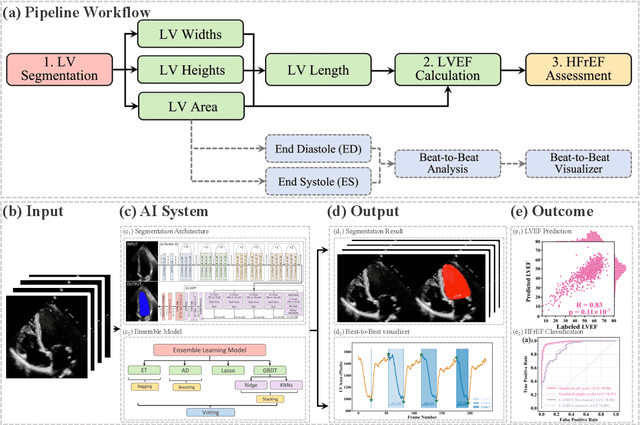
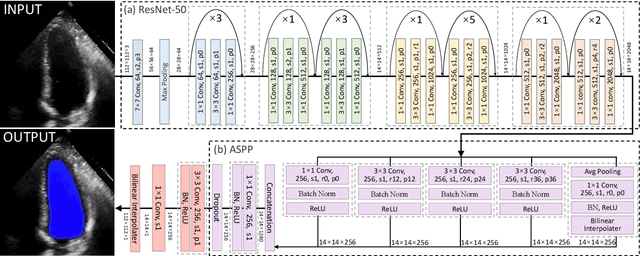
The echocardiographic measurement of left ventricular ejection fraction (LVEF) is fundamental to the diagnosis and classification of patients with heart failure (HF). In order to quantify LVEF automatically and accurately, this paper proposes a new pipeline method based on deep neural networks and ensemble learning. Within the pipeline, an Atrous Convolutional Neural Network (ACNN) was first trained to segment the left ventricle (LV), before employing the area-length formulation based on the ellipsoid single-plane model to calculate LVEF values. This formulation required inputs of LV area, derived from segmentation using an improved Jeffrey's method, as well as LV length, derived from a novel ensemble learning model. To further improve the pipeline's accuracy, an automated peak detection algorithm was used to identify end-diastolic and end-systolic frames, avoiding issues with human error. Subsequently, single-beat LVEF values were averaged across all cardiac cycles to obtain the final LVEF. This method was developed and internally validated in an open-source dataset containing 10,030 echocardiograms. The Pearson's correlation coefficient was 0.83 for LVEF prediction compared to expert human analysis (p<0.001), with a subsequent area under the receiver operator curve (AUROC) of 0.98 (95% confidence interval 0.97 to 0.99) for categorisation of HF with reduced ejection (HFrEF; LVEF<40%). In an external dataset with 200 echocardiograms, this method achieved an AUC of 0.90 (95% confidence interval 0.88 to 0.91) for HFrEF assessment. This study demonstrates that an automated neural network-based calculation of LVEF is comparable to expert clinicians performing time-consuming, frame-by-frame manual evaluation of cardiac systolic function.
A Latent Fingerprint in the Wild Database
Apr 03, 2023Latent fingerprints are among the most important and widely used evidence in crime scenes, digital forensics and law enforcement worldwide. Despite the number of advancements reported in recent works, we note that significant open issues such as independent benchmarking and lack of large-scale evaluation databases for improving the algorithms are inadequately addressed. The available databases are mostly of semi-public nature, lack of acquisition in the wild environment, and post-processing pipelines. Moreover, they do not represent a realistic capture scenario similar to real crime scenes, to benchmark the robustness of the algorithms. Further, existing databases for latent fingerprint recognition do not have a large number of unique subjects/fingerprint instances or do not provide ground truth/reference fingerprint images to conduct a cross-comparison against the latent. In this paper, we introduce a new wild large-scale latent fingerprint database that includes five different acquisition scenarios: reference fingerprints from (1) optical and (2) capacitive sensors, (3) smartphone fingerprints, latent fingerprints captured from (4) wall surface, (5) Ipad surface, and (6) aluminium foil surface. The new database consists of 1,318 unique fingerprint instances captured in all above mentioned settings. A total of 2,636 reference fingerprints from optical and capacitive sensors, 1,318 fingerphotos from smartphones, and 9,224 latent fingerprints from each of the 132 subjects were provided in this work. The dataset is constructed considering various age groups, equal representations of genders and backgrounds. In addition, we provide an extensive set of analysis of various subset evaluations to highlight open challenges for future directions in latent fingerprint recognition research.