 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFollow Your Track: Precise Skeleton Animation Controlled by 3D Trajectories
Jun 24, 20264D generation aims to animate 3D objects with realistic motion, holding great promise for applications. Existing methods typically decouple 3D asset generation from motion synthesis: acquire a 3D asset, prepare a structural representation like mesh and Gaussians, and synthesize motion from text or video control signals. However, dense mesh and Gaussian representations incur high computational costs and are prone to temporal artifacts, limiting animation quality and duration to only short clips. Meanwhile, text lacks fine-grained spatial and temporal details such as timing and coordination, while video entangles motion with appearance and background. Together, these limitations result in 4D animations that suffer from poor temporal consistency, wrong identification, and limited controllability. We address these issues with \texttt{ACT}, a trajectory-conditioned framework for topology-general skeletal animation. ACT uses skeletons as a compact structured and compute-efficient representation and 3D point trajectories from monocular video as explicit motion guidance which provide detailed motion patterns without appearance entanglement. At the core of ACT is a Routed Trajectory Injector, which achieves accurate and robust trajectory-to-joint transfer through three complementary designs: prior-guided hard routing establishes precise skeleton-to-mesh correspondences, global routing enables holistic joint-track interaction for full-body motion awareness, and local windowed cross-attention enforces fine-grained temporal alignment, improving micro-timing and reducing motion misalignment across varying motion rates. Extensive experiments demonstrate that \texttt{ACT} significantly outperforms existing methods in fidelity and temporal consistency.
Composable Crystals: Controllable Materials Discovery via Concept Learning
May 14, 2026De novo crystal generation, a central task in materials discovery, aims to generate crystals that are simultaneously valid, stable, unique, and novel. Existing methods mainly rely on black-box stochastic sampling, providing limited control over how generated structures move beyond the observed distribution. In this paper, we introduce a concept-based compositional framework for crystal generation. We train a vector-quantized variational autoencoder to automatically discover a shared set of reusable crystal concepts, which serve as building blocks for guided generation. These learned concepts naturally exhibit interpretability from both local atomic environments and global symmetry patterns, and generalize to crystals from different distributions. By recombining such concepts, our framework enables controllable exploration of novel crystals beyond the training distribution, rather than relying solely on unconstrained random sampling. To further improve composition efficiency, we introduce a composition generator and iteratively refine it using high-quality samples generated by the model itself. The resulting concept compositions are then used to condition downstream crystal generation. Numerical experiments on MP-20 and Alex-MP-20 show that compositing concepts separately increase base model up to 53.2% and 51.7% on V.S.U.N metric, with particular gains in novelty.
Crys-JEPA: Accelerating Crystal Discovery via Embedding Screening and Generative Refinement
May 14, 2026De novo crystal generation seeks to discover materials that are not merely realistic, but also stable and novel. However, most existing generative models are trained to maximize the likelihood of observed crystals, which encourages samples to stay close to known materials yet not necessarily align with the criteria that matter in discovery. Through an empirical investigation, we show that current crystal generative models are caught in a pronounced stability--novelty trade-off: moving toward the observed distribution preserves stability but limits novelty, whereas moving away from it quickly destroys stability. This suggests that the useful region for discovering crystals that are both stable and novel is extremely narrow. To escape the trade-off, we introduce Crys-JEPA, a joint embedding predictive architecture for crystals that learns an energy-aware latent space preserving formation-energy differences. In this space, stability assessment can be reformulated as an embedding-based comparison against accessible training crystals, reducing the reliance on expensive energy evaluation and task-specific external references. Building on Crys-JEPA, we further develop a screening-and-refinement pipeline that identifies promising generated crystals and reintroduces them to refine the generative model. On MP-20 and Alex-MP-20 datasets, we achieve improvements over baselines up to 81.4% and 82.6% on V.S.U.N metric, respectively.
Chain of Modality: From Static Fusion to Dynamic Orchestration in Omni-MLLMs
Apr 16, 2026Omni-modal Large Language Models (Omni-MLLMs) promise a unified integration of diverse sensory streams. However, recent evaluations reveal a critical performance paradox: unimodal baselines frequently outperform joint multimodal inference. We trace this perceptual fragility to the static fusion topologies universally employed by current models, identifying two structural pathologies: positional bias in sequential inputs and alignment traps in interleaved formats, which systematically distort attention regardless of task semantics. To resolve this functional rigidity, we propose Chain of Modality (CoM), an agentic framework that transitions multimodal fusion from passive concatenation to dynamic orchestration. CoM adaptively orchestrates input topologies, switching among parallel, sequential, and interleaved pathways to neutralize structural biases. Furthermore, CoM bifurcates cognitive execution into two task-aligned pathways: a streamlined ``Direct-Decide'' path for direct perception and a structured ``Reason-Decide'' path for analytical auditing. Operating in either a training-free or a data-efficient SFT setting, CoM achieves robust and consistent generalization across diverse benchmarks.
ClawLess: A Security Model of AI Agents
Apr 07, 2026Autonomous AI agents powered by Large Language Models can reason, plan, and execute complex tasks, but their ability to autonomously retrieve information and run code introduces significant security risks. Existing approaches attempt to regulate agent behavior through training or prompting, which does not offer fundamental security guarantees. We present ClawLess, a security framework that enforces formally verified policies on AI agents under a worst-case threat model where the agent itself may be adversarial. ClawLess formalizes a fine-grained security model over system entities, trust scopes, and permissions to express dynamic policies that adapt to agents' runtime behavior. These policies are translated into concrete security rules and enforced through a user-space kernel augmented with BPF-based syscall interception. This approach bridges the formal security model with practical enforcement, ensuring security regardless of the agent's internal design.
MI-DETR: A Strong Baseline for Moving Infrared Small Target Detection with Bio-Inspired Motion Integration
Mar 05, 2026Infrared small target detection (ISTD) is challenging because tiny, low-contrast targets are easily obscured by complex and dynamic backgrounds. Conventional multi-frame approaches typically learn motion implicitly through deep neural networks, often requiring additional motion supervision or explicit alignment modules. We propose Motion Integration DETR (MI-DETR), a bio-inspired dual-pathway detector that processes one infrared frame per time step while explicitly modeling motion. First, a retina-inspired cellular automaton (RCA) converts raw frame sequences into a motion map defined on the same pixel grid as the appearance image, enabling parvocellular-like appearance and magnocellular-like motion pathways to be supervised by a single set of bounding boxes without extra motion labels or alignment operations. Second, a Parvocellular-Magnocellular Interconnection (PMI) Block facilitates bidirectional feature interaction between the two pathways, providing a biologically motivated intermediate interconnection mechanism. Finally, a RT-DETR decoder operates on features from the two pathways to produce detection results. Surprisingly, our proposed simple yet effective approach yields strong performance on three commonly used ISTD benchmarks. MI-DETR achieves 70.3% mAP@50 and 72.7% F1 on IRDST-H (+26.35 mAP@50 over the best multi-frame baseline), 98.0% mAP@50 on DAUB-R, and 88.3% mAP@50 on ITSDT-15K, demonstrating the effectiveness of biologically inspired motion-appearance integration. Code is available at https://github.com/nliu-25/MI-DETR.
SVD-Preconditioned Gradient Descent Method for Solving Nonlinear Least Squares Problems
Feb 07, 2026This paper introduces a novel optimization algorithm designed for nonlinear least-squares problems. The method is derived by preconditioning the gradient descent direction using the Singular Value Decomposition (SVD) of the Jacobian. This SVD-based preconditioner is then integrated with the first- and second-moment adaptive learning rate mechanism of the Adam optimizer. We establish the local linear convergence of the proposed method under standard regularity assumptions and prove global convergence for a modified version of the algorithm under suitable conditions. The effectiveness of the approach is demonstrated experimentally across a range of tasks, including function approximation, partial differential equation (PDE) solving, and image classification on the CIFAR-10 dataset. Results show that the proposed method consistently outperforms standard Adam, achieving faster convergence and lower error in both regression and classification settings.
RAGNet: Large-scale Reasoning-based Affordance Segmentation Benchmark towards General Grasping
Jul 31, 2025



General robotic grasping systems require accurate object affordance perception in diverse open-world scenarios following human instructions. However, current studies suffer from the problem of lacking reasoning-based large-scale affordance prediction data, leading to considerable concern about open-world effectiveness. To address this limitation, we build a large-scale grasping-oriented affordance segmentation benchmark with human-like instructions, named RAGNet. It contains 273k images, 180 categories, and 26k reasoning instructions. The images cover diverse embodied data domains, such as wild, robot, ego-centric, and even simulation data. They are carefully annotated with an affordance map, while the difficulty of language instructions is largely increased by removing their category name and only providing functional descriptions. Furthermore, we propose a comprehensive affordance-based grasping framework, named AffordanceNet, which consists of a VLM pre-trained on our massive affordance data and a grasping network that conditions an affordance map to grasp the target. Extensive experiments on affordance segmentation benchmarks and real-robot manipulation tasks show that our model has a powerful open-world generalization ability. Our data and code is available at https://github.com/wudongming97/AffordanceNet.
TAViS: Text-bridged Audio-Visual Segmentation with Foundation Models
Jun 13, 2025Audio-Visual Segmentation (AVS) faces a fundamental challenge of effectively aligning audio and visual modalities. While recent approaches leverage foundation models to address data scarcity, they often rely on single-modality knowledge or combine foundation models in an off-the-shelf manner, failing to address the cross-modal alignment challenge. In this paper, we present TAViS, a novel framework that \textbf{couples} the knowledge of multimodal foundation models (ImageBind) for cross-modal alignment and a segmentation foundation model (SAM2) for precise segmentation. However, effectively combining these models poses two key challenges: the difficulty in transferring the knowledge between SAM2 and ImageBind due to their different feature spaces, and the insufficiency of using only segmentation loss for supervision. To address these challenges, we introduce a text-bridged design with two key components: (1) a text-bridged hybrid prompting mechanism where pseudo text provides class prototype information while retaining modality-specific details from both audio and visual inputs, and (2) an alignment supervision strategy that leverages text as a bridge to align shared semantic concepts within audio-visual modalities. Our approach achieves superior performance on single-source, multi-source, semantic datasets, and excels in zero-shot settings.
Unsupervised Learning for Class Distribution Mismatch
May 11, 2025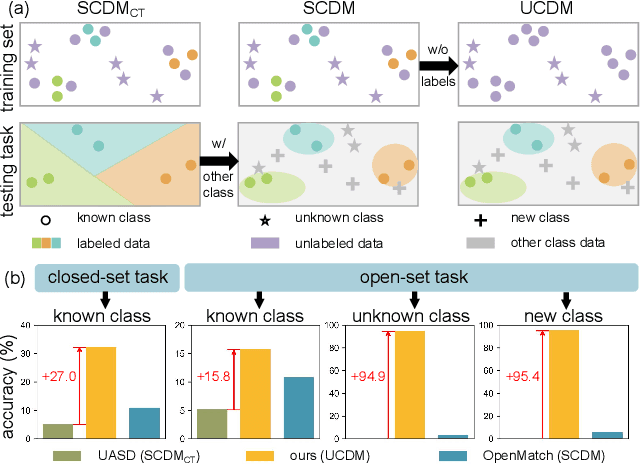

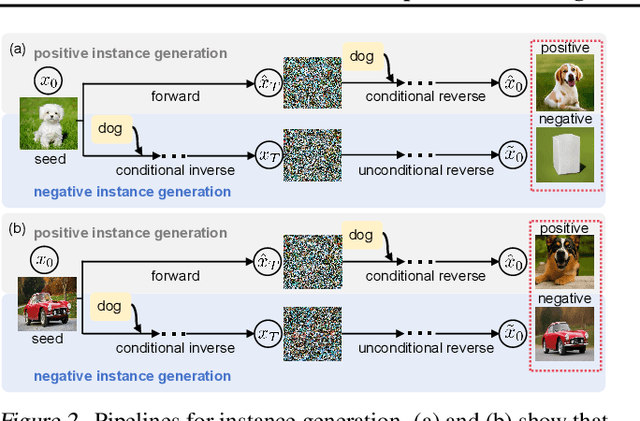

Class distribution mismatch (CDM) refers to the discrepancy between class distributions in training data and target tasks. Previous methods address this by designing classifiers to categorize classes known during training, while grouping unknown or new classes into an "other" category. However, they focus on semi-supervised scenarios and heavily rely on labeled data, limiting their applicability and performance. To address this, we propose Unsupervised Learning for Class Distribution Mismatch (UCDM), which constructs positive-negative pairs from unlabeled data for classifier training. Our approach randomly samples images and uses a diffusion model to add or erase semantic classes, synthesizing diverse training pairs. Additionally, we introduce a confidence-based labeling mechanism that iteratively assigns pseudo-labels to valuable real-world data and incorporates them into the training process. Extensive experiments on three datasets demonstrate UCDM's superiority over previous semi-supervised methods. Specifically, with a 60% mismatch proportion on Tiny-ImageNet dataset, our approach, without relying on labeled data, surpasses OpenMatch (with 40 labels per class) by 35.1%, 63.7%, and 72.5% in classifying known, unknown, and new classes.