 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Deepfake Detection Meets Graph Neural Network:a Unified and Lightweight Learning Framework
Aug 07, 2025The proliferation of generative video models has made detecting AI-generated and manipulated videos an urgent challenge. Existing detection approaches often fail to generalize across diverse manipulation types due to their reliance on isolated spatial, temporal, or spectral information, and typically require large models to perform well. This paper introduces SSTGNN, a lightweight Spatial-Spectral-Temporal Graph Neural Network framework that represents videos as structured graphs, enabling joint reasoning over spatial inconsistencies, temporal artifacts, and spectral distortions. SSTGNN incorporates learnable spectral filters and temporal differential modeling into a graph-based architecture, capturing subtle manipulation traces more effectively. Extensive experiments on diverse benchmark datasets demonstrate that SSTGNN not only achieves superior performance in both in-domain and cross-domain settings, but also offers strong robustness against unseen manipulations. Remarkably, SSTGNN accomplishes these results with up to 42.4$\times$ fewer parameters than state-of-the-art models, making it highly lightweight and scalable for real-world deployment.
Unsupervised Learning for Class Distribution Mismatch
May 11, 2025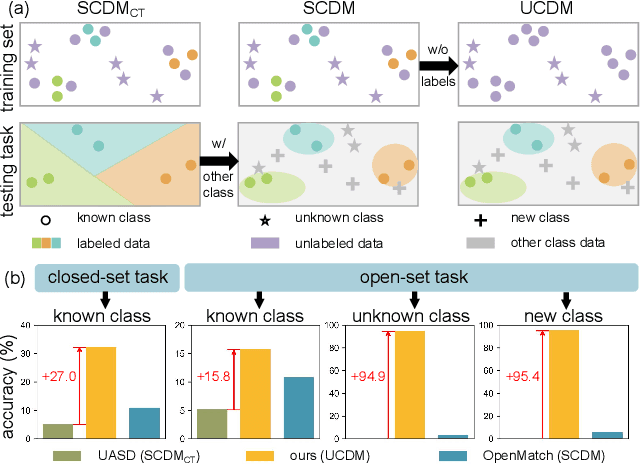

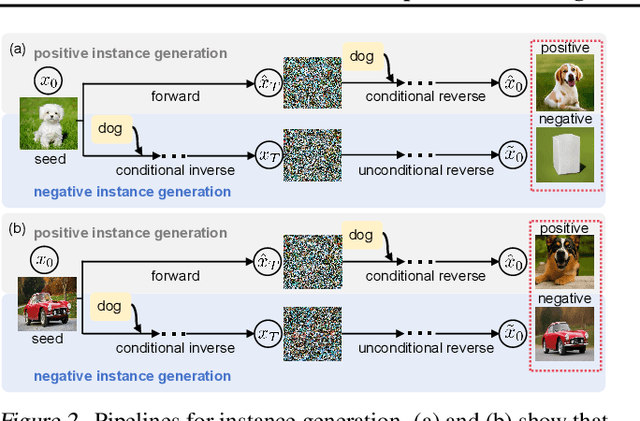

Class distribution mismatch (CDM) refers to the discrepancy between class distributions in training data and target tasks. Previous methods address this by designing classifiers to categorize classes known during training, while grouping unknown or new classes into an "other" category. However, they focus on semi-supervised scenarios and heavily rely on labeled data, limiting their applicability and performance. To address this, we propose Unsupervised Learning for Class Distribution Mismatch (UCDM), which constructs positive-negative pairs from unlabeled data for classifier training. Our approach randomly samples images and uses a diffusion model to add or erase semantic classes, synthesizing diverse training pairs. Additionally, we introduce a confidence-based labeling mechanism that iteratively assigns pseudo-labels to valuable real-world data and incorporates them into the training process. Extensive experiments on three datasets demonstrate UCDM's superiority over previous semi-supervised methods. Specifically, with a 60% mismatch proportion on Tiny-ImageNet dataset, our approach, without relying on labeled data, surpasses OpenMatch (with 40 labels per class) by 35.1%, 63.7%, and 72.5% in classifying known, unknown, and new classes.
Open-Sora 2.0: Training a Commercial-Level Video Generation Model in $200k
Mar 12, 2025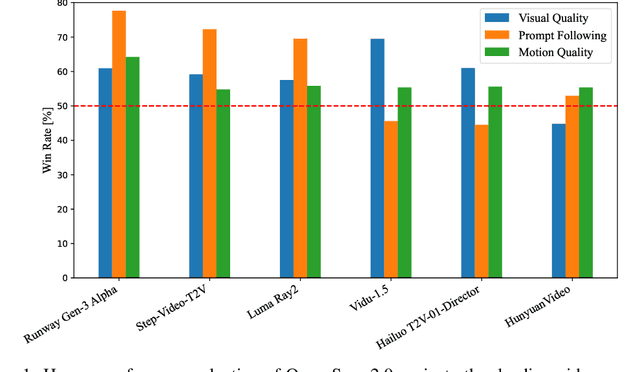

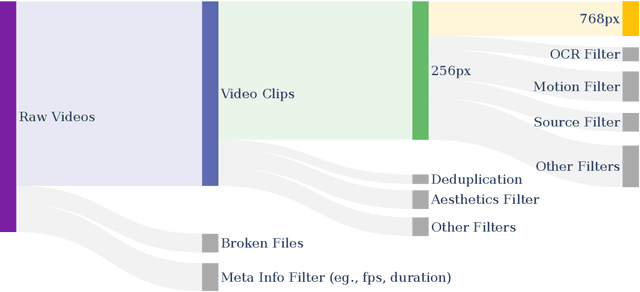

Video generation models have achieved remarkable progress in the past year. The quality of AI video continues to improve, but at the cost of larger model size, increased data quantity, and greater demand for training compute. In this report, we present Open-Sora 2.0, a commercial-level video generation model trained for only $200k. With this model, we demonstrate that the cost of training a top-performing video generation model is highly controllable. We detail all techniques that contribute to this efficiency breakthrough, including data curation, model architecture, training strategy, and system optimization. According to human evaluation results and VBench scores, Open-Sora 2.0 is comparable to global leading video generation models including the open-source HunyuanVideo and the closed-source Runway Gen-3 Alpha. By making Open-Sora 2.0 fully open-source, we aim to democratize access to advanced video generation technology, fostering broader innovation and creativity in content creation. All resources are publicly available at: https://github.com/hpcaitech/Open-Sora.
Sparse MeZO: Less Parameters for Better Performance in Zeroth-Order LLM Fine-Tuning
Feb 24, 2024



While fine-tuning large language models (LLMs) for specific tasks often yields impressive results, it comes at the cost of memory inefficiency due to back-propagation in gradient-based training. Memory-efficient Zeroth-order (MeZO) optimizers, recently proposed to address this issue, only require forward passes during training, making them more memory-friendly. However, the quality of gradient estimates in zeroth order optimization often depends on the data dimensionality, potentially explaining why MeZO still exhibits significant performance drops compared to standard fine-tuning across various tasks. Inspired by the success of Parameter-Efficient Fine-Tuning (PEFT), this paper introduces Sparse MeZO, a novel memory-efficient zeroth-order optimization approach that applies ZO only to a carefully chosen subset of parameters. We propose a simple yet effective parameter selection scheme that yields significant performance gains with Sparse-MeZO. Additionally, we develop a memory-optimized implementation for sparse masking, ensuring the algorithm requires only inference-level memory consumption, allowing Sparse-MeZO to fine-tune LLaMA-30b on a single A100 GPU. Experimental results illustrate that Sparse-MeZO consistently improves both performance and convergence speed over MeZO without any overhead. For example, it achieves a 9\% absolute accuracy improvement and 3.5x speedup over MeZO on the RTE task.
An Efficient 2D Method for Training Super-Large Deep Learning Models
Apr 12, 2021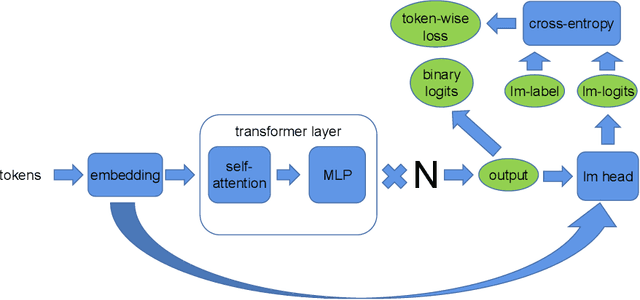
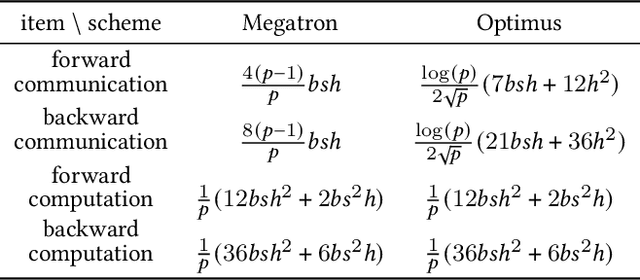
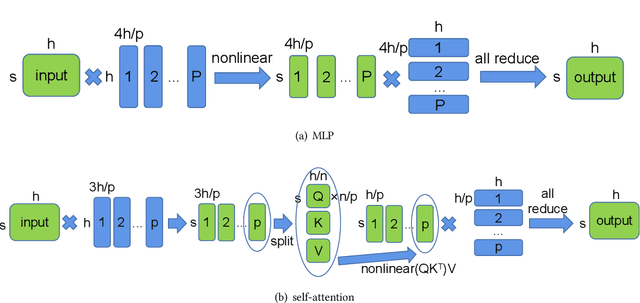

Huge neural network models have shown unprecedented performance in real-world applications. However, due to memory constraints, model parallelism must be utilized to host large models that would otherwise not fit into the memory of a single device. Previous methods like Megatron partition the parameters of the entire model among multiple devices, while each device has to accommodate the redundant activations in forward and backward pass. In this work, we propose Optimus, a highly efficient and scalable 2D-partition paradigm of model parallelism that would facilitate the training of infinitely large language models. In Optimus, activations are partitioned and distributed among devices, further reducing redundancy. In terms of isoefficiency, Optimus significantly outperforms Megatron. On 64 GPUs of TACC Frontera, Optimus achieves 1.48X speedup for training, 1.78X speedup for inference, and 8X increase in maximum batch size over Megatron. Optimus surpasses Megatron in scaling efficiency by a great margin. The code is available at https://github.com/xuqifan897/Optimus.