 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpecForge: A Flexible and Efficient Open-Source Training Framework for Speculative Decoding
Mar 19, 2026Large language models incur high inference latency due to sequential autoregressive decoding. Speculative decoding alleviates this bottleneck by using a lightweight draft model to propose multiple tokens for batched verification. However, its adoption has been limited by the lack of high-quality draft models and scalable training infrastructure. We introduce SpecForge, an open-source, production-oriented framework for training speculative decoding models with full support for EAGLE-3. SpecForge incorporates target-draft decoupling, hybrid parallelism, optimized training kernels, and integration with production-grade inference engines, enabling up to 9.9x faster EAGLE-3 training for Qwen3-235B-A22B. In addition, we release SpecBundle, a suite of production-grade EAGLE-3 draft models trained with SpecForge for mainstream open-source LLMs. Through a systematic study of speculative decoding training recipes, SpecBundle addresses the scarcity of high-quality drafts in the community, and our draft models achieve up to 4.48x end-to-end inference speedup on SGLang, establishing SpecForge as a practical foundation for real-world speculative decoding deployment.
DSB: Dynamic Sliding Block Scheduling for Diffusion LLMs
Feb 05, 2026Diffusion large language models (dLLMs) have emerged as a promising alternative for text generation, distinguished by their native support for parallel decoding. In practice, block inference is crucial for avoiding order misalignment in global bidirectional decoding and improving output quality. However, the widely-used fixed, predefined block (naive) schedule is agnostic to semantic difficulty, making it a suboptimal strategy for both quality and efficiency: it can force premature commitments to uncertain positions while delaying easy positions near block boundaries. In this work, we analyze the limitations of naive block scheduling and disclose the importance of dynamically adapting the schedule to semantic difficulty for reliable and efficient inference. Motivated by this, we propose Dynamic Sliding Block (DSB), a training-free block scheduling method that uses a sliding block with a dynamic size to overcome the rigidity of the naive block. To further improve efficiency, we introduce DSB Cache, a training-free KV-cache mechanism tailored to DSB. Extensive experiments across multiple models and benchmarks demonstrate that DSB, together with DSB Cache, consistently improves both generation quality and inference efficiency for dLLMs. Code is released at https://github.com/lizhuo-luo/DSB.
ReSpec: Towards Optimizing Speculative Decoding in Reinforcement Learning Systems
Oct 30, 2025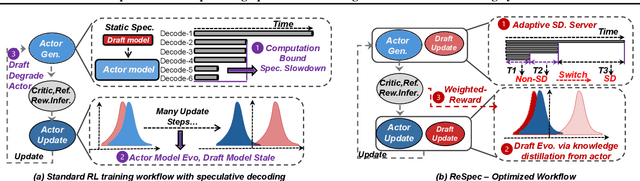


Adapting large language models (LLMs) via reinforcement learning (RL) is often bottlenecked by the generation stage, which can consume over 75\% of the training time. Speculative decoding (SD) accelerates autoregressive generation in serving systems, but its behavior under RL training remains largely unexplored. We identify three critical gaps that hinder the naive integration of SD into RL systems: diminishing speedups at large batch sizes, drafter staleness under continual actor updates, and drafter-induced policy degradation. To address these gaps, we present ReSpec, a system that adapts SD to RL through three complementary mechanisms: dynamically tuning SD configurations, evolving the drafter via knowledge distillation, and weighting updates by rollout rewards. On Qwen models (3B--14B), ReSpec achieves up to 4.5x speedup while preserving reward convergence and training stability, providing a practical solution for efficient RL-based LLM adaptation.
TetriServe: Efficient DiT Serving for Heterogeneous Image Generation
Oct 02, 2025Diffusion Transformer (DiT) models excel at generating highquality images through iterative denoising steps, but serving them under strict Service Level Objectives (SLOs) is challenging due to their high computational cost, particularly at large resolutions. Existing serving systems use fixed degree sequence parallelism, which is inefficient for heterogeneous workloads with mixed resolutions and deadlines, leading to poor GPU utilization and low SLO attainment. In this paper, we propose step-level sequence parallelism to dynamically adjust the parallel degree of individual requests according to their deadlines. We present TetriServe, a DiT serving system that implements this strategy for highly efficient image generation. Specifically, TetriServe introduces a novel round-based scheduling mechanism that improves SLO attainment: (1) discretizing time into fixed rounds to make deadline-aware scheduling tractable, (2) adapting parallelism at the step level and minimize GPU hour consumption, and (3) jointly packing requests to minimize late completions. Extensive evaluation on state-of-the-art DiT models shows that TetriServe achieves up to 32% higher SLO attainment compared to existing solutions without degrading image quality.
Open-Sora: Democratizing Efficient Video Production for All
Dec 29, 2024
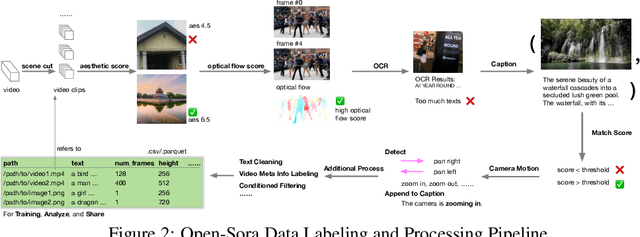
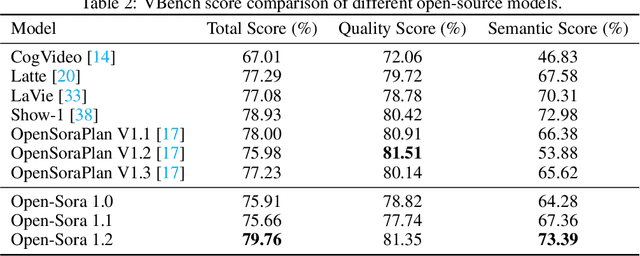
Vision and language are the two foundational senses for humans, and they build up our cognitive ability and intelligence. While significant breakthroughs have been made in AI language ability, artificial visual intelligence, especially the ability to generate and simulate the world we see, is far lagging behind. To facilitate the development and accessibility of artificial visual intelligence, we created Open-Sora, an open-source video generation model designed to produce high-fidelity video content. Open-Sora supports a wide spectrum of visual generation tasks, including text-to-image generation, text-to-video generation, and image-to-video generation. The model leverages advanced deep learning architectures and training/inference techniques to enable flexible video synthesis, which could generate video content of up to 15 seconds, up to 720p resolution, and arbitrary aspect ratios. Specifically, we introduce Spatial-Temporal Diffusion Transformer (STDiT), an efficient diffusion framework for videos that decouples spatial and temporal attention. We also introduce a highly compressive 3D autoencoder to make representations compact and further accelerate training with an ad hoc training strategy. Through this initiative, we aim to foster innovation, creativity, and inclusivity within the community of AI content creation. By embracing the open-source principle, Open-Sora democratizes full access to all the training/inference/data preparation codes as well as model weights. All resources are publicly available at: https://github.com/hpcaitech/Open-Sora.
GliDe with a CaPE: A Low-Hassle Method to Accelerate Speculative Decoding
Feb 03, 2024



Speculative decoding is a relatively new decoding framework that leverages small and efficient draft models to reduce the latency of LLMs. In this study, we introduce GliDe and CaPE, two low-hassle modifications to vanilla speculative decoding to further improve the decoding speed of a frozen LLM. Specifically, GliDe is a modified draft model architecture that reuses the cached keys and values from the target LLM, while CaPE is a proposal expansion method that uses the draft model's confidence scores to help select additional candidate tokens for verification. Extensive experiments on different benchmarks demonstrate that our proposed GliDe draft model significantly reduces the expected decoding latency. Additional evaluation using walltime reveals that GliDe can accelerate Vicuna models up to 2.17x and further extend the improvement to 2.61x with CaPE. We will release our code, data, and the trained draft models.
Colossal-Auto: Unified Automation of Parallelization and Activation Checkpoint for Large-scale Models
Feb 22, 2023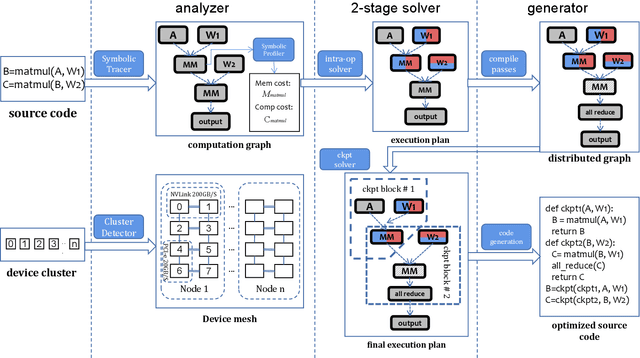
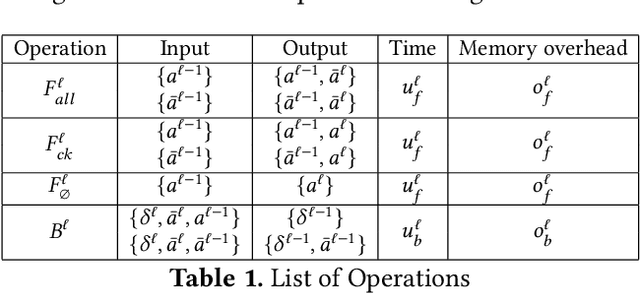
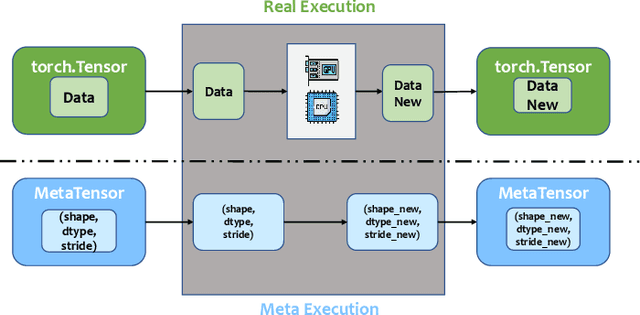

In recent years, large-scale models have demonstrated state-of-the-art performance across various domains. However, training such models requires various techniques to address the problem of limited computing power and memory on devices such as GPUs. Some commonly used techniques include pipeline parallelism, tensor parallelism, and activation checkpointing. While existing works have focused on finding efficient distributed execution plans (Zheng et al. 2022) and activation checkpoint scheduling (Herrmann et al. 2019, Beaumont et al. 2021}, there has been no method proposed to optimize these two plans jointly. Moreover, ahead-of-time compilation relies heavily on accurate memory and computing overhead estimation, which is often time-consuming and misleading. Existing training systems and machine learning pipelines either physically execute each operand or estimate memory usage with a scaled input tensor. To address these challenges, we introduce a system that can jointly optimize distributed execution and gradient checkpointing plans. Additionally, we provide an easy-to-use symbolic profiler that generates memory and computing statistics for any PyTorch model with a minimal time cost. Our approach allows users to parallelize their model training on the given hardware with minimum code change based. The source code is publicly available at Colossal-AI GitHub or https://github.com/hpcaitech/ColossalAI
Elixir: Train a Large Language Model on a Small GPU Cluster
Dec 10, 2022In recent years, the number of parameters of one deep learning (DL) model has been growing much faster than the growth of GPU memory space. People who are inaccessible to a large number of GPUs resort to heterogeneous training systems for storing model parameters in CPU memory. Existing heterogeneous systems are based on parallelization plans in the scope of the whole model. They apply a consistent parallel training method for all the operators in the computation. Therefore, engineers need to pay a huge effort to incorporate a new type of model parallelism and patch its compatibility with other parallelisms. For example, Mixture-of-Experts (MoE) is still incompatible with ZeRO-3 in Deepspeed. Also, current systems face efficiency problems on small scale, since they are designed and tuned for large-scale training. In this paper, we propose Elixir, a new parallel heterogeneous training system, which is designed for efficiency and flexibility. Elixir utilizes memory resources and computing resources of both GPU and CPU. For flexibility, Elixir generates parallelization plans in the granularity of operators. Any new type of model parallelism can be incorporated by assigning a parallel pattern to the operator. For efficiency, Elixir implements a hierarchical distributed memory management scheme to accelerate inter-GPU communications and CPU-GPU data transmissions. As a result, Elixir can train a 30B OPT model on an A100 with 40GB CUDA memory, meanwhile reaching 84% efficiency of Pytorch GPU training. With its super-linear scalability, the training efficiency becomes the same as Pytorch GPU training on multiple GPUs. Also, large MoE models can be trained 5.3x faster than dense models of the same size. Now Elixir is integrated into ColossalAI and is available on its main branch.
EnergonAI: An Inference System for 10-100 Billion Parameter Transformer Models
Sep 06, 2022
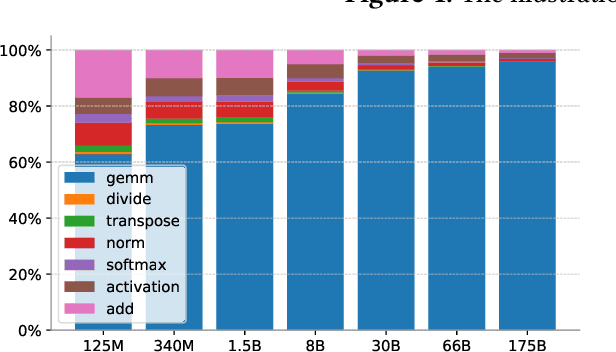
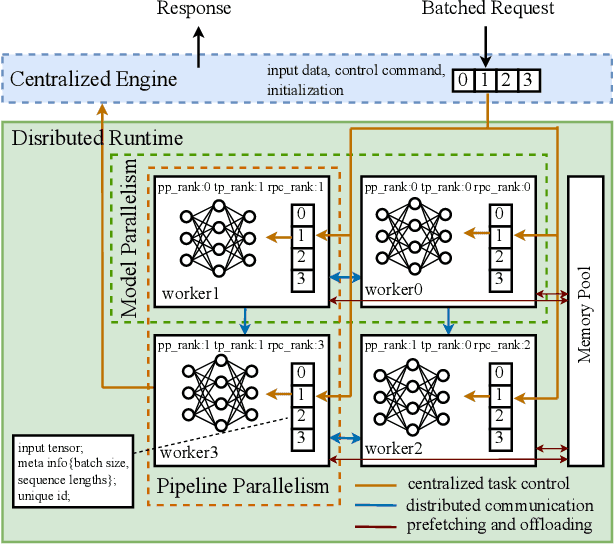
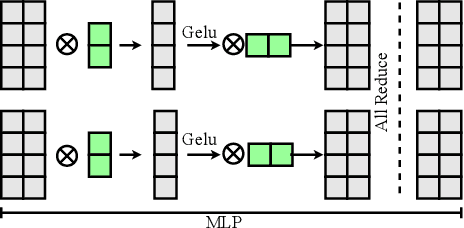
Large transformer models display promising performance on a wide range of natural language processing (NLP) tasks. Although the AI community has expanded the model scale to the trillion parameter level, the practical deployment of 10-100 billion parameter models is still uncertain due to the latency, throughput, and memory constraints. In this paper, we proposed EnergonAI to solve the challenges of the efficient deployment of 10-100 billion parameter transformer models on single- or multi-GPU systems. EnergonAI adopts a hierarchy-controller system architecture to coordinate multiple devices and efficiently support different parallel patterns. It delegates the execution of sub-models to multiple workers in the single-controller style and applies tensor parallelism and pipeline parallelism among the workers in a multi-controller style. Upon the novel architecture, we propose three techniques, i.e. non-blocking pipeline parallelism, distributed redundant computation elimination, and peer memory pooling. EnergonAI enables the users to program complex parallel code the same as a serial one. Compared with the FasterTransformer, we have proven that EnergonAI has superior performance on latency and throughput. In our experiments, EnergonAI can achieve 37% latency reduction in tensor parallelism, 10% scalability improvement in pipeline parallelism, and it improves the model scale inferred on a single GPU by using a larger heterogeneous memory space at cost of limited performance reduction.
A Frequency-aware Software Cache for Large Recommendation System Embeddings
Aug 08, 2022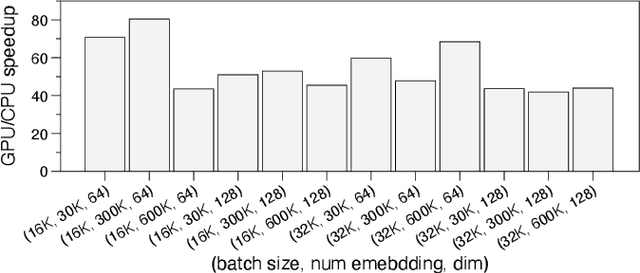
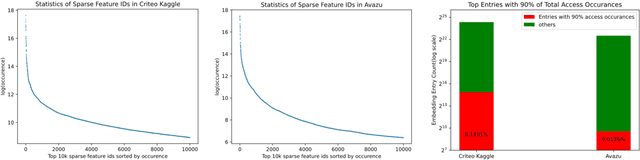
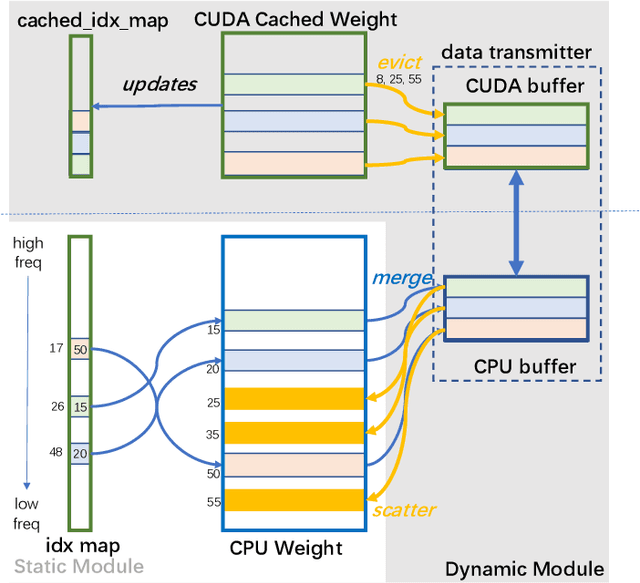
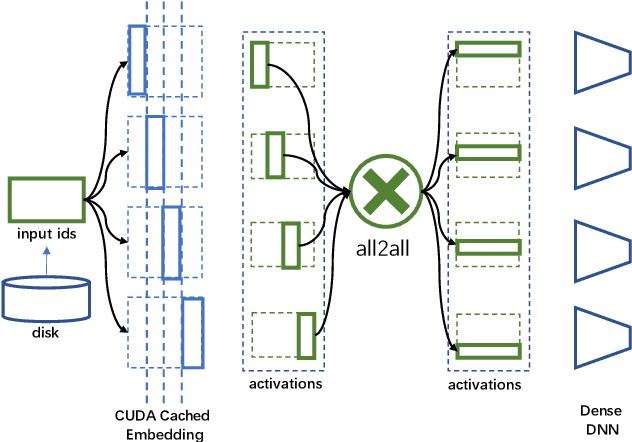
Deep learning recommendation models (DLRMs) have been widely applied in Internet companies. The embedding tables of DLRMs are too large to fit on GPU memory entirely. We propose a GPU-based software cache approaches to dynamically manage the embedding table in the CPU and GPU memory space by leveraging the id's frequency statistics of the target dataset. Our proposed software cache is efficient in training entire DLRMs on GPU in a synchronized update manner. It is also scaled to multiple GPUs in combination with the widely used hybrid parallel training approaches. Evaluating our prototype system shows that we can keep only 1.5% of the embedding parameters in the GPU to obtain a decent end-to-end training speed.