 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Simple Geometric-Aware Indoor Positioning Interpolation Algorithm Based on Manifold Learning
Nov 27, 2023Interpolation methodologies have been widely used within the domain of indoor positioning systems. However, existing indoor positioning interpolation algorithms exhibit several inherent limitations, including reliance on complex mathematical models, limited flexibility, and relatively low precision. To enhance the accuracy and efficiency of indoor positioning interpolation techniques, this paper proposes a simple yet powerful geometric-aware interpolation algorithm for indoor positioning tasks. The key to our algorithm is to exploit the geometric attributes of the local topological manifold using manifold learning principles. Therefore, instead of constructing complicated mathematical models, the proposed algorithm facilitates the more precise and efficient estimation of points grounded in the local topological manifold. Moreover, our proposed method can be effortlessly integrated into any indoor positioning system, thereby bolstering its adaptability. Through a systematic array of experiments and comprehensive performance analyses conducted on both simulated and real-world datasets, we demonstrate that the proposed algorithm consistently outperforms the most commonly used and representative interpolation approaches regarding interpolation accuracy and efficiency. Furthermore, the experimental results also underscore the substantial practical utility of our method and its potential applicability in real-time indoor positioning scenarios.
A Frequency-aware Software Cache for Large Recommendation System Embeddings
Aug 08, 2022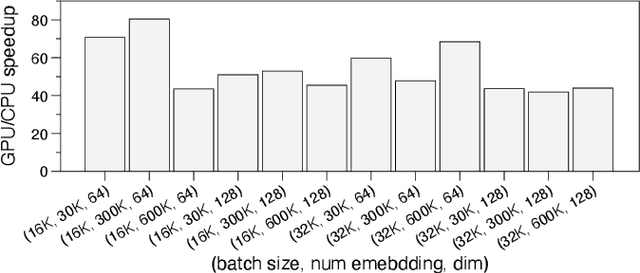
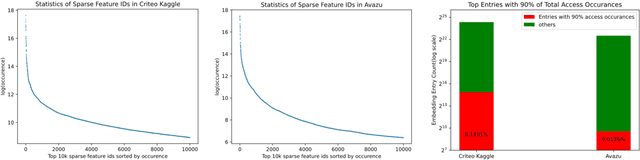
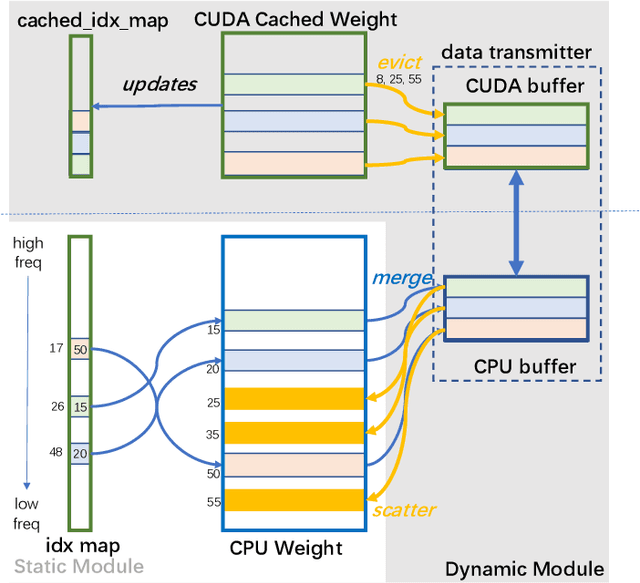
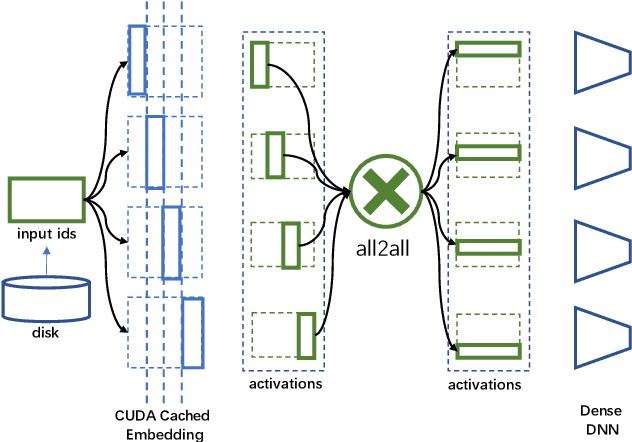
Deep learning recommendation models (DLRMs) have been widely applied in Internet companies. The embedding tables of DLRMs are too large to fit on GPU memory entirely. We propose a GPU-based software cache approaches to dynamically manage the embedding table in the CPU and GPU memory space by leveraging the id's frequency statistics of the target dataset. Our proposed software cache is efficient in training entire DLRMs on GPU in a synchronized update manner. It is also scaled to multiple GPUs in combination with the widely used hybrid parallel training approaches. Evaluating our prototype system shows that we can keep only 1.5% of the embedding parameters in the GPU to obtain a decent end-to-end training speed.
Using ROC and Unlabeled Data for Increasing Low-Shot Transfer Learning Classification Accuracy
Oct 01, 2020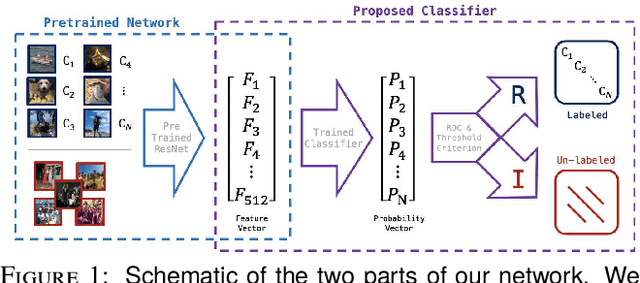
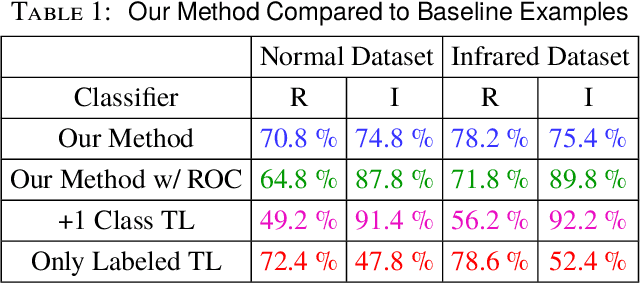
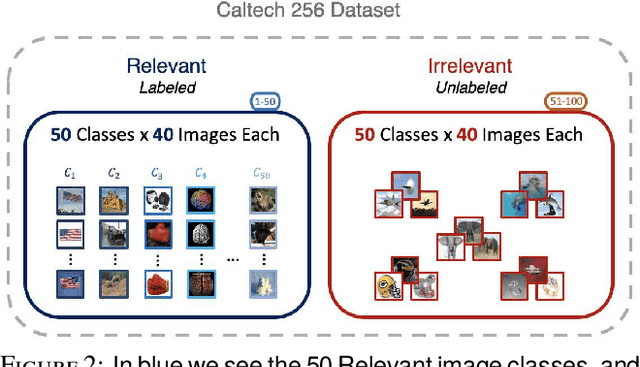
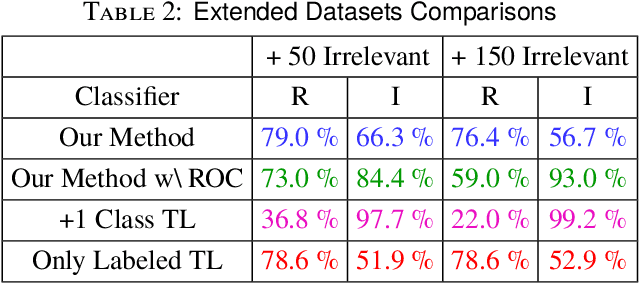
One of the most important characteristics of human visual intelligence is the ability to identify unknown objects. The capability to distinguish between a substance which a human mind has no previous experience of and a familiar object, is innate to every human. In everyday life, within seconds of seeing an "unknown" object, we are able to categorize it as such without any substantial effort. Convolutional Neural Networks, regardless of how they are trained (i.e. in a conventional manner or through transfer learning) can recognize only the classes that they are trained for. When using them for classification, any candidate image will be placed in one of the available classes. We propose a low-shot classifier which can serve as the top layer to any existing CNN that the feature extractor was already trained. Using a limited amount of labeled data for the type of images which need to be specifically classified along with unlabeled data for all other images, a unique target matrix and a Receiver Operator Curve (ROC) criterion, we are able to increase identification accuracy by up to 30% for the images that do not belong to any specific classes, while retaining the ability to identify images that belong to the specific classes of interest.