 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Frequency-aware Software Cache for Large Recommendation System Embeddings
Aug 08, 2022
Deep learning recommendation models (DLRMs) have been widely applied in Internet companies. The embedding tables of DLRMs are too large to fit on GPU memory entirely. We propose a GPU-based software cache approaches to dynamically manage the embedding table in the CPU and GPU memory space by leveraging the id's frequency statistics of the target dataset. Our proposed software cache is efficient in training entire DLRMs on GPU in a synchronized update manner. It is also scaled to multiple GPUs in combination with the widely used hybrid parallel training approaches. Evaluating our prototype system shows that we can keep only 1.5% of the embedding parameters in the GPU to obtain a decent end-to-end training speed.
Colossal-AI: A Unified Deep Learning System For Large-Scale Parallel Training
Oct 28, 2021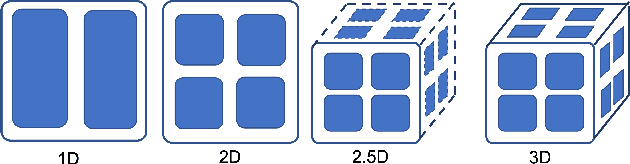
The Transformer architecture has improved the performance of deep learning models in domains such as Computer Vision and Natural Language Processing. Together with better performance come larger model sizes. This imposes challenges to the memory wall of the current accelerator hardware such as GPU. It is never ideal to train large models such as Vision Transformer, BERT, and GPT on a single GPU or a single machine. There is an urgent demand to train models in a distributed environment. However, distributed training, especially model parallelism, often requires domain expertise in computer systems and architecture. It remains a challenge for AI researchers to implement complex distributed training solutions for their models. In this paper, we introduce Colossal-AI, which is a unified parallel training system designed to seamlessly integrate different paradigms of parallelization techniques including data parallelism, pipeline parallelism, multiple tensor parallelism, and sequence parallelism. Colossal-AI aims to support the AI community to write distributed models in the same way as how they write models normally. This allows them to focus on developing the model architecture and separates the concerns of distributed training from the development process. The documentations can be found at https://www.colossalai.org and the source code can be found at https://github.com/hpcaitech/ColossalAI.
Online Evolutionary Batch Size Orchestration for Scheduling Deep Learning Workloads in GPU Clusters
Aug 08, 2021
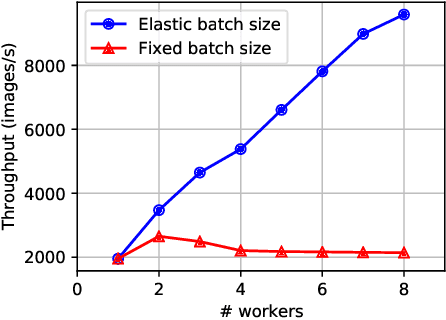
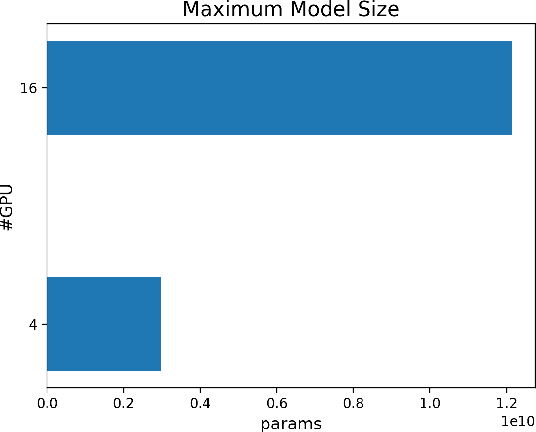
Efficient GPU resource scheduling is essential to maximize resource utilization and save training costs for the increasing amount of deep learning workloads in shared GPU clusters. Existing GPU schedulers largely rely on static policies to leverage the performance characteristics of deep learning jobs. However, they can hardly reach optimal efficiency due to the lack of elasticity. To address the problem, we propose ONES, an ONline Evolutionary Scheduler for elastic batch size orchestration. ONES automatically manages the elasticity of each job based on the training batch size, so as to maximize GPU utilization and improve scheduling efficiency. It determines the batch size for each job through an online evolutionary search that can continuously optimize the scheduling decisions. We evaluate the effectiveness of ONES with 64 GPUs on TACC's Longhorn supercomputers. The results show that ONES can outperform the prior deep learning schedulers with a significantly shorter average job completion time.
2.5-dimensional distributed model training
May 30, 2021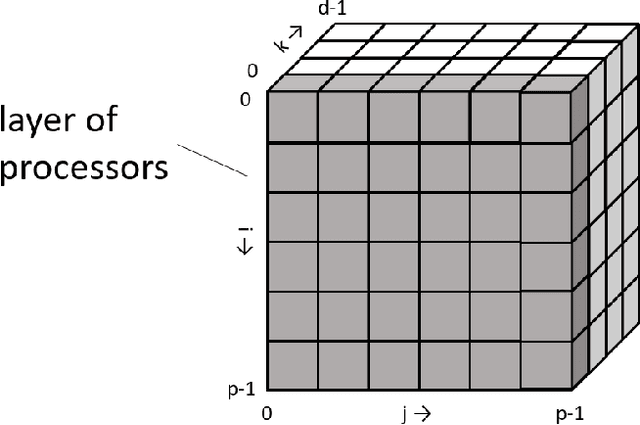
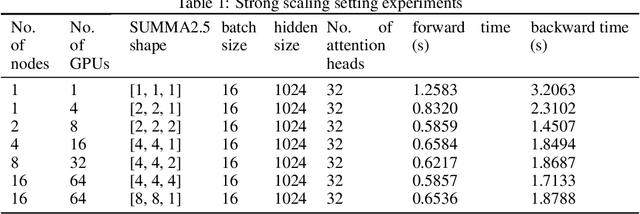
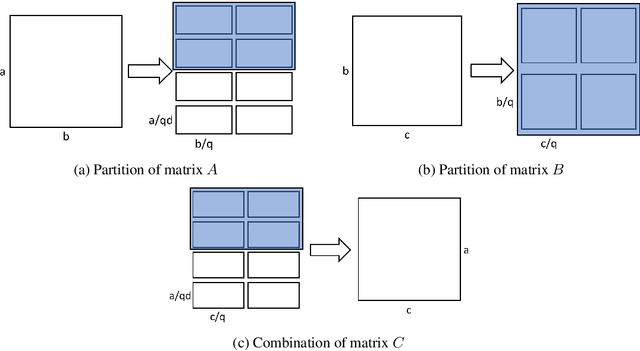
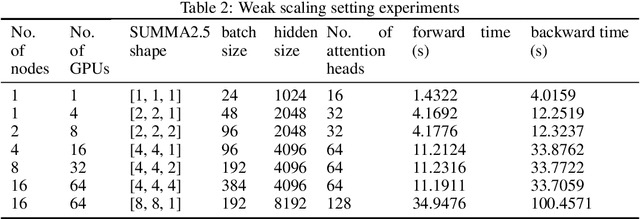
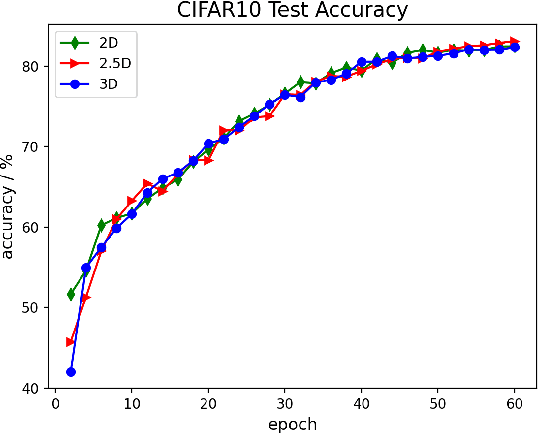
Data parallelism does a good job in speeding up the training. However, when it comes to the case when the memory of a single device can not host a whole model, data parallelism would not have the chance to do anything. Another option is to split the model by operator, or horizontally. Megatron-LM introduced a 1-Dimensional distributed method to use GPUs to speed up the training process. Optimus is a 2D solution for distributed tensor parallelism. However, these methods have a high communication overhead and a low scaling efficiency on large-scale computing clusters. To solve this problem, we investigate the 2.5-Dimensional distributed tensor parallelism.Introduced by Solomonik et al., 2.5-Dimensional Matrix Multiplication developed an effective method to perform multiple Cannon's algorithm at the same time to increase the efficiency. With many restrictions of Cannon's Algorithm and a huge amount of shift operation, we need to invent a new method of 2.5-dimensional matrix multiplication to enhance the performance. Absorbing the essence from both SUMMA and 2.5-Dimensional Matrix Multiplication, we introduced SUMMA2.5-LM for language models to overcome the abundance of unnecessary transmission loss result from the increasing size of language model parallelism. Compared to previous 1D and 2D model parallelization of language models, our SUMMA2.5-LM managed to reduce the transmission cost on each layer, which could get a 1.45X efficiency according to our weak scaling result between 2.5-D [4,4,4] arrangement and 2-D [8,8,1] arrangement.
Maximizing Parallelism in Distributed Training for Huge Neural Networks
May 30, 2021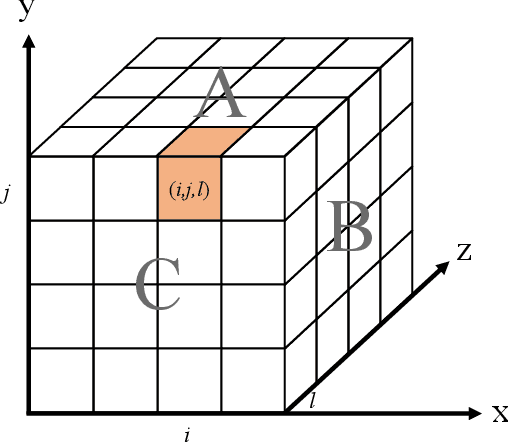
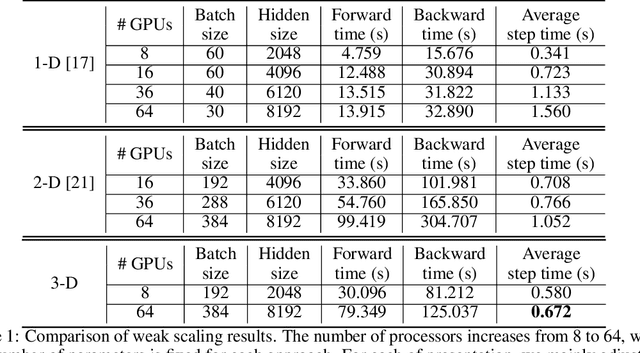
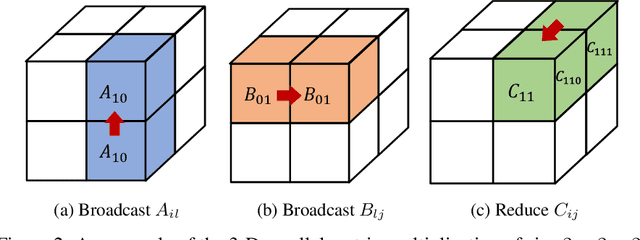
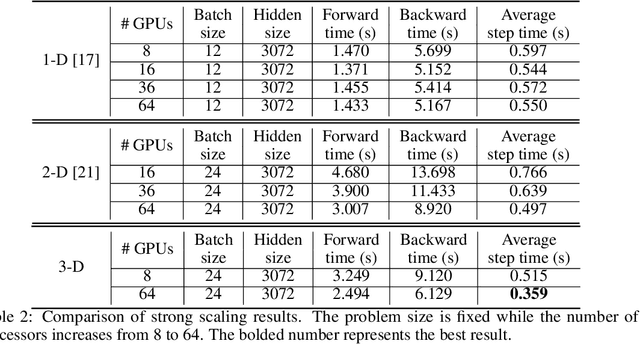
The recent Natural Language Processing techniques have been refreshing the state-of-the-art performance at an incredible speed. Training huge language models is therefore an imperative demand in both industry and academy. However, huge language models impose challenges to both hardware and software. Graphical processing units (GPUs) are iterated frequently to meet the exploding demand, and a variety of ASICs like TPUs are spawned. However, there is still a tension between the fast growth of the extremely huge models and the fact that Moore's law is approaching the end. To this end, many model parallelism techniques are proposed to distribute the model parameters to multiple devices, so as to alleviate the tension on both memory and computation. Our work is the first to introduce a 3-dimensional model parallelism for expediting huge language models. By reaching a perfect load balance, our approach presents smaller memory and communication cost than existing state-of-the-art 1-D and 2-D model parallelism. Our experiments on 64 TACC's V100 GPUs show that our 3-D parallelism outperforms the 1-D and 2-D parallelism with 2.32x and 1.57x speedup, respectively.