 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Multichannel Active Noise Control with Asynchronous Communication
Jan 22, 2026Distributed multichannel active noise control (DMCANC) offers effective noise reduction across large spatial areas by distributing the computational load of centralized control to multiple low-cost nodes. Conventional DMCANC methods, however, typically assume synchronous communication and require frequent data exchange, resulting in high communication overhead. To enhance efficiency and adaptability, this work proposes an asynchronous communication strategy where each node executes a weight-constrained filtered-x LMS (WCFxLMS) algorithm and independently requests communication only when its local noise reduction performance degrades. Upon request, other nodes transmit the weight difference between their local control filter and the center point in WCFxLMS, which are then integrated to update both the control filter and the center point. This design enables nodes to operate asynchronously while preserving cooperative behavior. Simulation results demonstrate that the proposed asynchronous communication DMCANC (ACDMCANC) system maintains effective noise reduction with significantly reduced communication load, offering improved scalability for heterogeneous networks.
A Stabilized Hybrid Active Noise Control Algorithm of GFANC and FxNLMS with Online Clustering
Jan 22, 2026The Filtered-x Normalized Least Mean Square (FxNLMS) algorithm suffers from slow convergence and a risk of divergence, although it can achieve low steady-state errors after sufficient adaptation. In contrast, the Generative Fixed-Filter Active Noise Control (GFANC) method offers fast response speed, but its lack of adaptability may lead to large steady-state errors. This paper proposes a hybrid GFANC-FxNLMS algorithm to leverage the complementary advantages of both approaches. In the hybrid GFANC-FxNLMS algorithm, GFANC provides a frame-level control filter as an initialization for FxNLMS, while FxNLMS performs continuous adaptation at the sampling rate. Small variations in the GFANC-generated filter may repeatedly reinitialize FxNLMS, interrupting its adaptation process and destabilizing the system. An online clustering module is introduced to avoid unnecessary re-initializations and improve system stability. Simulation results show that the proposed algorithm achieves fast response, very low steady-state error, and high stability, requiring only one pre-trained broadband filter.
Directional Selective Fixed-Filter Active Noise Control Based on a Convolutional Neural Network in Reverberant Environments
Jan 11, 2026Selective fixed-filter active noise control (SFANC) is a novel approach capable of mitigating noise with varying frequency characteristics. It offers faster response and greater computational efficiency compared to traditional adaptive algorithms. However, spatial factors, particularly the influence of the noise source location, are often overlooked. Some existing studies have explored the impact of the direction-of-arrival (DoA) of the noise source on ANC performance, but they are mostly limited to free-field conditions and do not consider the more complex indoor reverberant environments. To address this gap, this paper proposes a learning-based directional SFANC method that incorporates the DoA of the noise source in reverberant environments. In this framework, multiple reference signals are processed by a convolutional neural network (CNN) to estimate the azimuth and elevation angles of the noise source, as well as to identify the most appropriate control filter for effective noise cancellation. Compared to traditional adaptive algorithms, the proposed approach achieves superior noise reduction with shorter response times, even in the presence of reverberations.
DOA Estimation with Lightweight Network on LLM-Aided Simulated Acoustic Scenes
Nov 11, 2025Direction-of-Arrival (DOA) estimation is critical in spatial audio and acoustic signal processing, with wide-ranging applications in real-world. Most existing DOA models are trained on synthetic data by convolving clean speech with room impulse responses (RIRs), which limits their generalizability due to constrained acoustic diversity. In this paper, we revisit DOA estimation using a recently introduced dataset constructed with the assistance of large language models (LLMs), which provides more realistic and diverse spatial audio scenes. We benchmark several representative neural-based DOA methods on this dataset and propose LightDOA, a lightweight DOA estimation model based on depthwise separable convolutions, specifically designed for mutil-channel input in varying environments. Experimental results show that LightDOA achieves satisfactory accuracy and robustness across various acoustic scenes while maintaining low computational complexity. This study not only highlights the potential of spatial audio synthesized with the assistance of LLMs in advancing robust and efficient DOA estimation research, but also highlights LightDOA as efficient solution for resource-constrained applications.
Self-Boosted Weight-Constrained FxLMS: A Robustness Distributed Active Noise Control Algorithm Without Internode Communication
Jul 16, 2025Compared to the conventional centralized multichannel active noise control (MCANC) algorithm, which requires substantial computational resources, decentralized approaches exhibit higher computational efficiency but typically result in inferior noise reduction performance. To enhance performance, distributed ANC methods have been introduced, enabling information exchange among ANC nodes; however, the resulting communication latency often compromises system stability. To overcome these limitations, we propose a self-boosted weight-constrained filtered-reference least mean square (SB-WCFxLMS) algorithm for the distributed MCANC system without internode communication. The WCFxLMS algorithm is specifically designed to mitigate divergence issues caused by the internode cross-talk effect. The self-boosted strategy lets each ANC node independently adapt its constraint parameters based on its local noise reduction performance, thus ensuring effective noise cancellation without the need for inter-node communication. With the assistance of this mechanism, this approach significantly reduces both computational complexity and communication overhead. Numerical simulations employing real acoustic paths and compressor noise validate the effectiveness and robustness of the proposed system. The results demonstrate that our proposed method achieves satisfactory noise cancellation performance with minimal resource requirements.
Preventing output saturation in active noise control: An output-constrained Kalman filter approach
Dec 25, 2024The Kalman filter (KF)-based active noise control (ANC) system demonstrates superior tracking and faster convergence compared to the least mean square (LMS) method, particularly in dynamic noise cancellation scenarios. However, in environments with extremely high noise levels, the power of the control signal can exceed the system's rated output power due to hardware limitations, leading to output saturation and subsequent non-linearity. To mitigate this issue, a modified KF with an output constraint is proposed. In this approach, the disturbance treated as an measurement is re-scaled by a constraint factor, which is determined by the system's rated power, the secondary path gain, and the disturbance power. As a result, the output power of the system, i.e. the control signal, is indirectly constrained within the maximum output of the system, ensuring stability. Simulation results indicate that the proposed algorithm not only achieves rapid suppression of dynamic noise but also effectively prevents non-linearity due to output saturation, highlighting its practical significance.
Transferable Selective Virtual Sensing Active Noise Control Technique Based on Metric Learning
Sep 09, 2024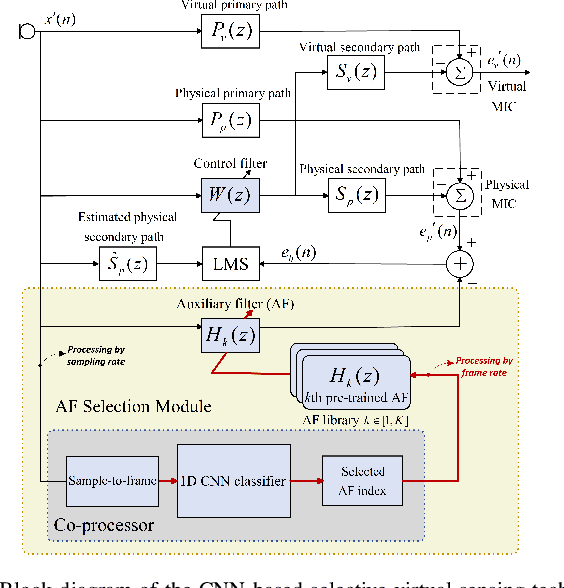
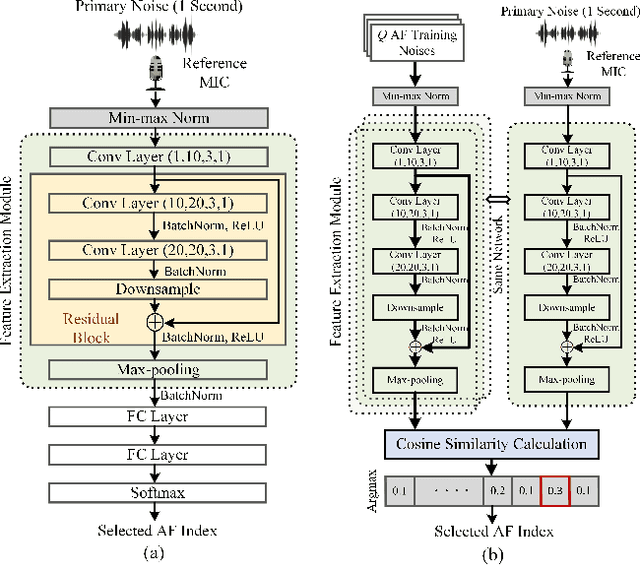
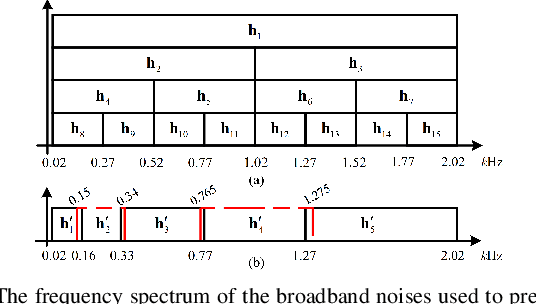
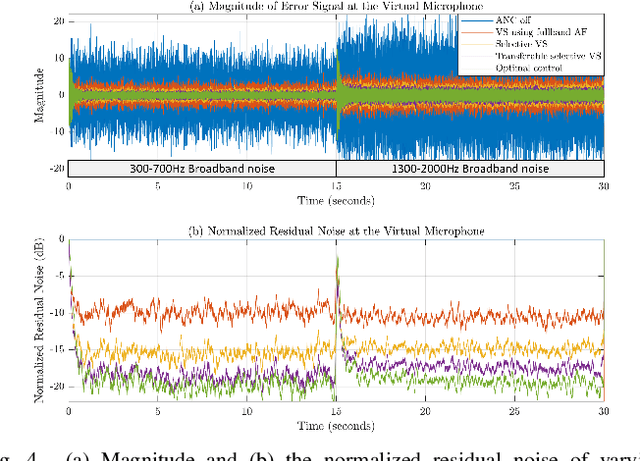
Virtual sensing (VS) technology enables active noise control (ANC) systems to attenuate noise at virtual locations distant from the physical error microphones. Appropriate auxiliary filters (AF) can significantly enhance the effectiveness of VS approaches. The selection of appropriate AF for various types of noise can be automatically achieved using convolutional neural networks (CNNs). However, training the CNN model for different ANC systems is often labour-intensive and time-consuming. To tackle this problem, we propose a novel method, Transferable Selective VS, by integrating metric-learning technology into CNN-based VS approaches. The Transferable Selective VS method allows a pre-trained CNN to be applied directly to new ANC systems without requiring retraining, and it can handle unseen noise types. Numerical simulations demonstrate the effectiveness of the proposed method in attenuating sudden-varying broadband noises and real-world noises.
fastkqr: A Fast Algorithm for Kernel Quantile Regression
Aug 10, 2024Quantile regression is a powerful tool for robust and heterogeneous learning that has seen applications in a diverse range of applied areas. However, its broader application is often hindered by the substantial computational demands arising from the non-smooth quantile loss function. In this paper, we introduce a novel algorithm named fastkqr, which significantly advances the computation of quantile regression in reproducing kernel Hilbert spaces. The core of fastkqr is a finite smoothing algorithm that magically produces exact regression quantiles, rather than approximations. To further accelerate the algorithm, we equip fastkqr with a novel spectral technique that carefully reutilizes matrix computations. In addition, we extend fastkqr to accommodate a flexible kernel quantile regression with a data-driven crossing penalty, addressing the interpretability challenges of crossing quantile curves at multiple levels. We have implemented fastkqr in a publicly available R package. Extensive simulations and real applications show that fastkqr matches the accuracy of state-of-the-art algorithms but can operate up to an order of magnitude faster.
Computation-efficient Virtual Sensing Approach with Multichannel Adjoint Least Mean Square Algorithm
May 23, 2024Multichannel active noise control (ANC) systems are designed to create a large zone of quietness (ZoQ) around the error microphones, however, the placement of these microphones often presents challenges due to physical limitations. Virtual sensing technique that effectively suppresses the noise far from the physical error microphones is one of the most promising solutions. Nevertheless, the conventional multichannel virtual sensing ANC (MVANC) system based on the multichannel filtered reference least mean square (MCFxLMS) algorithm often suffers from high computational complexity. This paper proposes a feedforward MVANC system that incorporates the multichannel adjoint least mean square (MCALMS) algorithm to overcome these limitations effectively. Computational analysis demonstrates the improvement of computational efficiency and numerical simulations exhibit comparable noise reduction performance at virtual locations compared to the conventional MCFxLMS algorithm. Additionally, the effects of varied tuning noises on system performance are also investigated, providing insightful findings on optimizing MVANC systems.
Implementation of the Feedforward Multichannel Virtual Sensing Active Noise Control (MVANC) by Using MATLAB
May 17, 2024The multichannel virtual sensing active noise control (MVANC) methodology is an advanced approach that may provide a wide area of silence at specific virtual positions that are distant from the physical error microphones. Currently, there is a scarcity of open-source programs available for the MVANC algorithm. This work presents a MATLAB code for the MVANC approach, utilizing the multichannel filtered-x least mean square (MCFxLMS) algorithm. The code is designed to be applicable to systems with any number of channels. The code can be found on GitHub.