 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaximizing Parallelism in Distributed Training for Huge Neural Networks
Paper and Code
May 30, 2021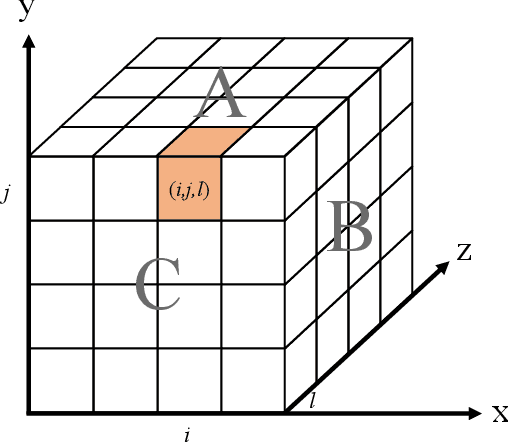
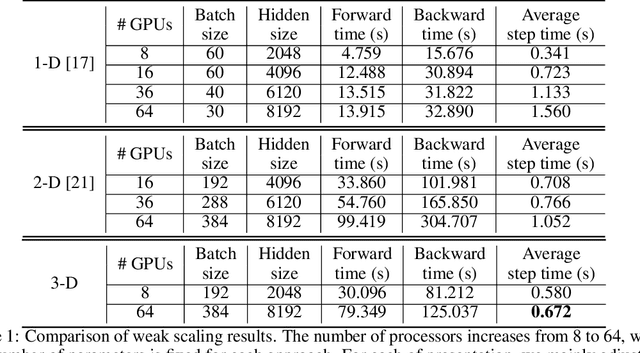
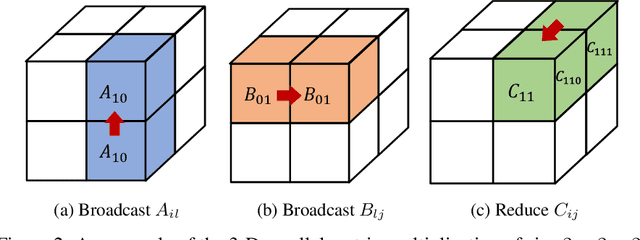
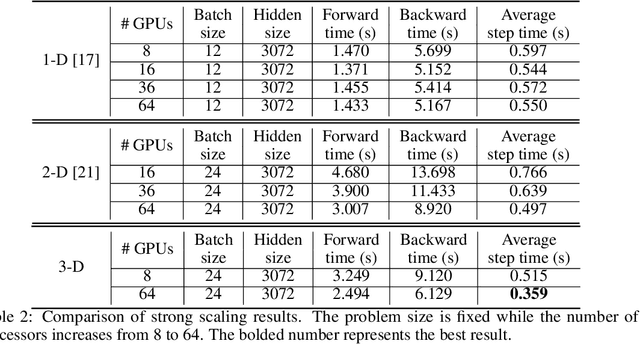
The recent Natural Language Processing techniques have been refreshing the state-of-the-art performance at an incredible speed. Training huge language models is therefore an imperative demand in both industry and academy. However, huge language models impose challenges to both hardware and software. Graphical processing units (GPUs) are iterated frequently to meet the exploding demand, and a variety of ASICs like TPUs are spawned. However, there is still a tension between the fast growth of the extremely huge models and the fact that Moore's law is approaching the end. To this end, many model parallelism techniques are proposed to distribute the model parameters to multiple devices, so as to alleviate the tension on both memory and computation. Our work is the first to introduce a 3-dimensional model parallelism for expediting huge language models. By reaching a perfect load balance, our approach presents smaller memory and communication cost than existing state-of-the-art 1-D and 2-D model parallelism. Our experiments on 64 TACC's V100 GPUs show that our 3-D parallelism outperforms the 1-D and 2-D parallelism with 2.32x and 1.57x speedup, respectively.