 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Efficient and Robust Method for Chest X-Ray Rib Suppression that Improves Pulmonary Abnormality Diagnosis
Feb 19, 2023


Suppression of thoracic bone shadows on chest X-rays (CXRs) has been indicated to improve the diagnosis of pulmonary disease. Previous approaches can be categorized as unsupervised physical and supervised deep learning models. Nevertheless, with physical models able to preserve morphological details but at the cost of extremely long processing time, existing DL methods face challenges of gathering sufficient/qualitative ground truth (GT) for robust training, thus leading to failure in maintaining clinically acceptable false positive rates. We hereby propose a generalizable yet efficient workflow of two stages: (1) training pairs generation with GT bone shadows eliminated in by a physical model in spatially transformed gradient fields. (2) fully supervised image denoising network training on stage-one datasets for fast rib removal on incoming CXRs. For step two, we designed a densely connected network called SADXNet, combined with peak signal to noise ratio and multi-scale structure similarity index measure objective minimization to suppress bony structures. The SADXNet organizes spatial filters in U shape (e.g., X=7; filters = 16, 64, 256, 512, 256, 64, 16) and preserves the feature map dimension throughout the network flow. Visually, SADXNet can suppress the rib edge and that near the lung wall/vertebra without jeopardizing the vessel/abnormality conspicuity. Quantitively, it achieves RMSE of ~0 during testing with one prediction taking <1s. Downstream tasks including lung nodule detection as well as common lung disease classification and localization are used to evaluate our proposed rib suppression mechanism. We observed 3.23% and 6.62% area under the curve (AUC) increase as well as 203 and 385 absolute false positive decrease for lung nodule detection and common lung disease localization, separately.
To what extent can Plug-and-Play methods outperform neural networks alone in low-dose CT reconstruction
Feb 15, 2022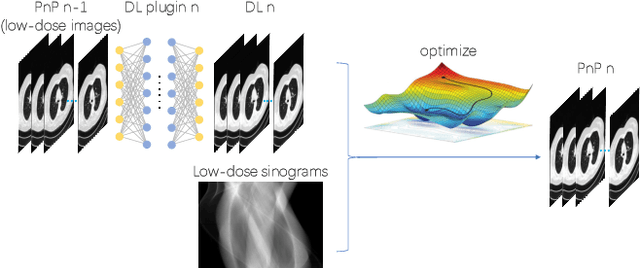
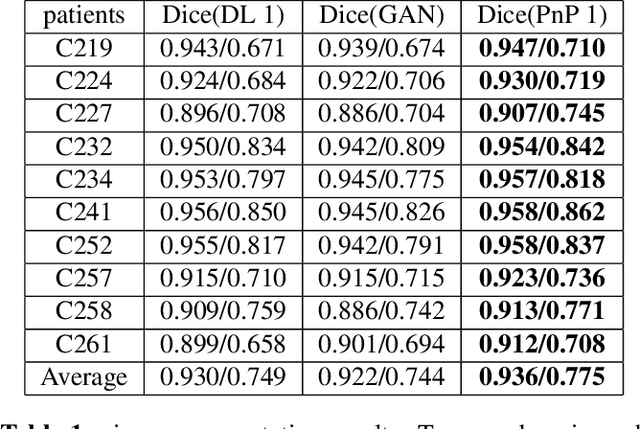

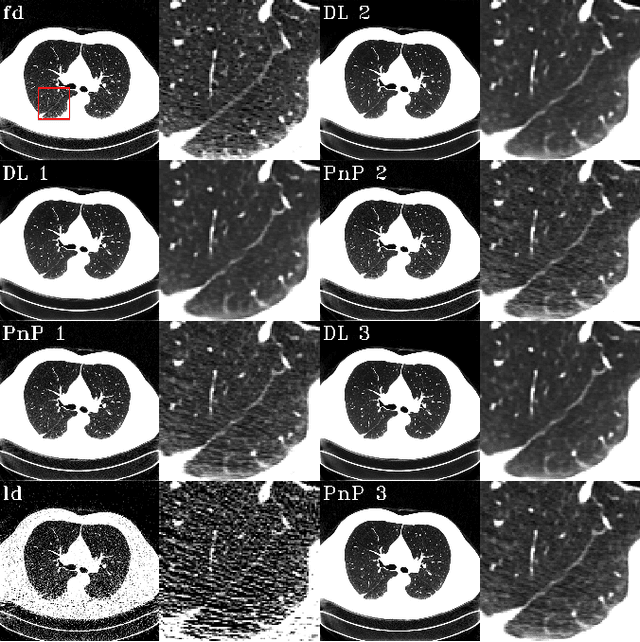
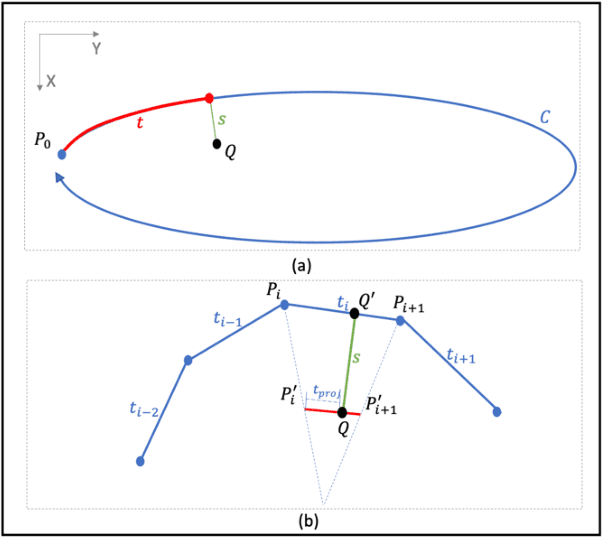
The Plug-and-Play (PnP) framework was recently introduced for low-dose CT reconstruction to leverage the interpretability and the flexibility of model-based methods to incorporate various plugins, such as trained deep learning (DL) neural networks. However, the benefits of PnP vs. state-of-the-art DL methods have not been clearly demonstrated. In this work, we proposed an improved PnP framework to address the previous limitations and develop clinical-relevant segmentation metrics for quantitative result assessment. Compared with the DL alone methods, our proposed PnP framework was slightly inferior in MSE and PSNR. However, the power spectrum of the resulting images better matched that of full-dose images than that of DL denoised images. The resulting images supported higher accuracy in airway segmentation than DL denoised images for all the ten patients in the test set, more substantially on the airways with a cross-section smaller than 0.61cm$^2$, and outperformed the DL denoised images for 45 out of 50 lung lobes in lobar segmentation. Our PnP method proved to be significantly better at preserving the image texture, which translated to task-specific benefits in automated structure segmentation and detection.
2.5-dimensional distributed model training
May 30, 2021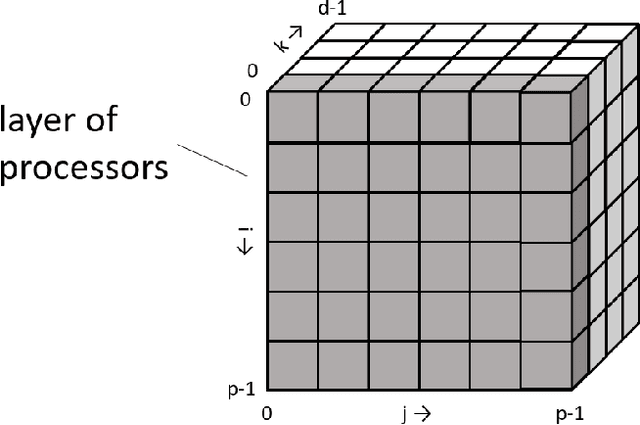
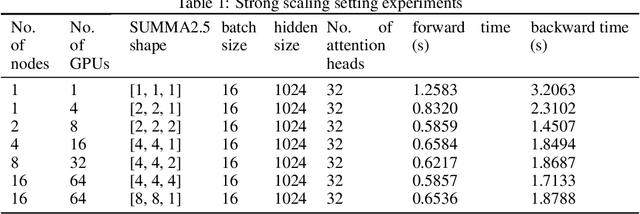
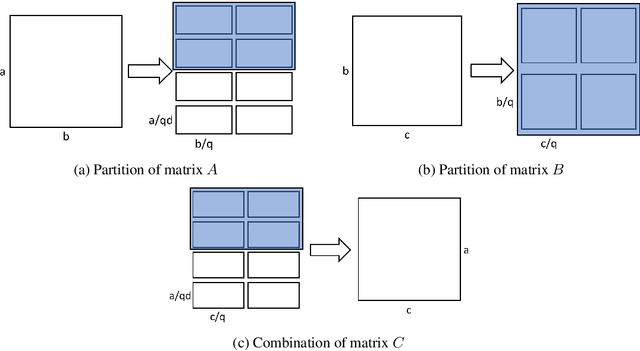
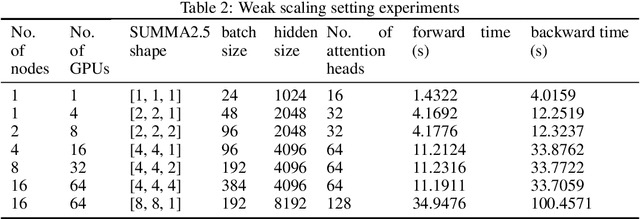
Data parallelism does a good job in speeding up the training. However, when it comes to the case when the memory of a single device can not host a whole model, data parallelism would not have the chance to do anything. Another option is to split the model by operator, or horizontally. Megatron-LM introduced a 1-Dimensional distributed method to use GPUs to speed up the training process. Optimus is a 2D solution for distributed tensor parallelism. However, these methods have a high communication overhead and a low scaling efficiency on large-scale computing clusters. To solve this problem, we investigate the 2.5-Dimensional distributed tensor parallelism.Introduced by Solomonik et al., 2.5-Dimensional Matrix Multiplication developed an effective method to perform multiple Cannon's algorithm at the same time to increase the efficiency. With many restrictions of Cannon's Algorithm and a huge amount of shift operation, we need to invent a new method of 2.5-dimensional matrix multiplication to enhance the performance. Absorbing the essence from both SUMMA and 2.5-Dimensional Matrix Multiplication, we introduced SUMMA2.5-LM for language models to overcome the abundance of unnecessary transmission loss result from the increasing size of language model parallelism. Compared to previous 1D and 2D model parallelization of language models, our SUMMA2.5-LM managed to reduce the transmission cost on each layer, which could get a 1.45X efficiency according to our weak scaling result between 2.5-D [4,4,4] arrangement and 2-D [8,8,1] arrangement.
Maximizing Parallelism in Distributed Training for Huge Neural Networks
May 30, 2021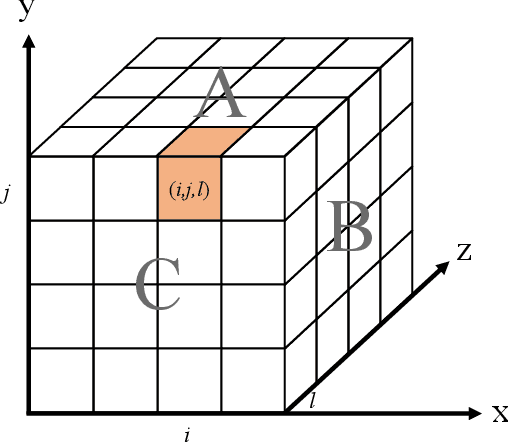
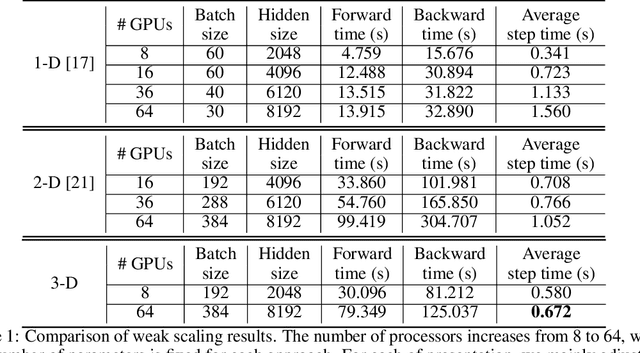
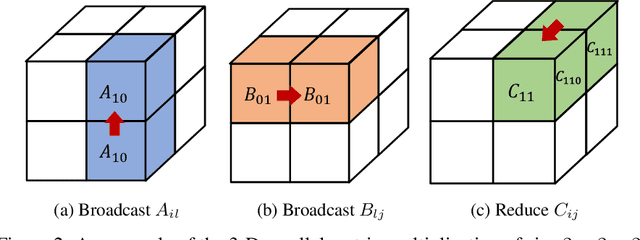
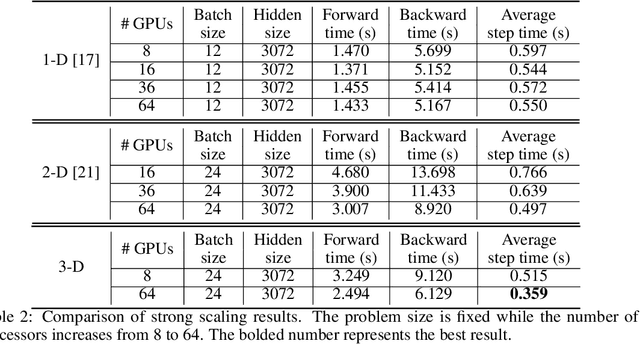
The recent Natural Language Processing techniques have been refreshing the state-of-the-art performance at an incredible speed. Training huge language models is therefore an imperative demand in both industry and academy. However, huge language models impose challenges to both hardware and software. Graphical processing units (GPUs) are iterated frequently to meet the exploding demand, and a variety of ASICs like TPUs are spawned. However, there is still a tension between the fast growth of the extremely huge models and the fact that Moore's law is approaching the end. To this end, many model parallelism techniques are proposed to distribute the model parameters to multiple devices, so as to alleviate the tension on both memory and computation. Our work is the first to introduce a 3-dimensional model parallelism for expediting huge language models. By reaching a perfect load balance, our approach presents smaller memory and communication cost than existing state-of-the-art 1-D and 2-D model parallelism. Our experiments on 64 TACC's V100 GPUs show that our 3-D parallelism outperforms the 1-D and 2-D parallelism with 2.32x and 1.57x speedup, respectively.
An Efficient 2D Method for Training Super-Large Deep Learning Models
Apr 12, 2021
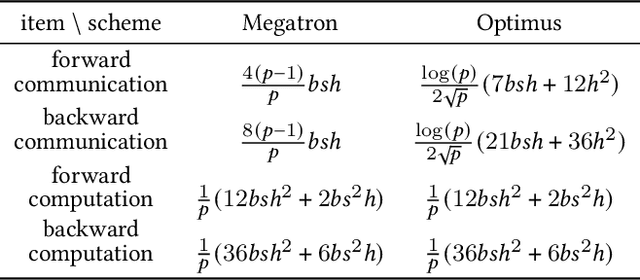
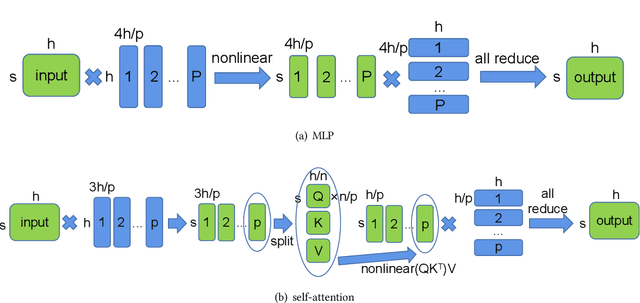

Huge neural network models have shown unprecedented performance in real-world applications. However, due to memory constraints, model parallelism must be utilized to host large models that would otherwise not fit into the memory of a single device. Previous methods like Megatron partition the parameters of the entire model among multiple devices, while each device has to accommodate the redundant activations in forward and backward pass. In this work, we propose Optimus, a highly efficient and scalable 2D-partition paradigm of model parallelism that would facilitate the training of infinitely large language models. In Optimus, activations are partitioned and distributed among devices, further reducing redundancy. In terms of isoefficiency, Optimus significantly outperforms Megatron. On 64 GPUs of TACC Frontera, Optimus achieves 1.48X speedup for training, 1.78X speedup for inference, and 8X increase in maximum batch size over Megatron. Optimus surpasses Megatron in scaling efficiency by a great margin. The code is available at https://github.com/xuqifan897/Optimus.