 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerated Patient-specific Non-Cartesian MRI Reconstruction using Implicit Neural Representations
Mar 07, 2025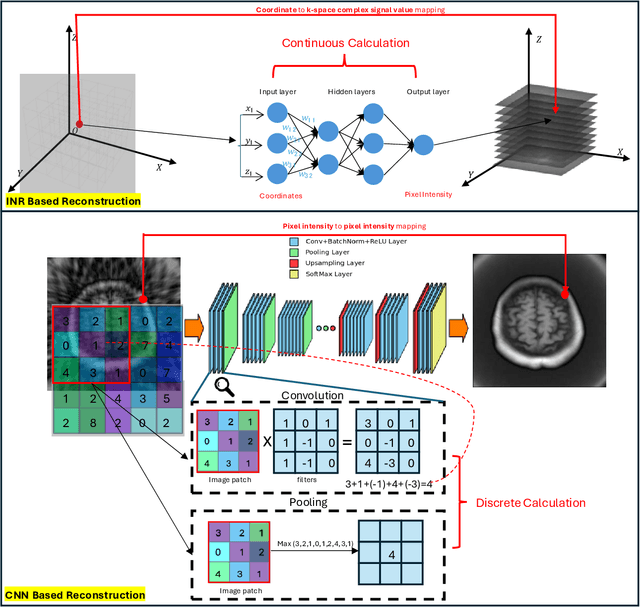
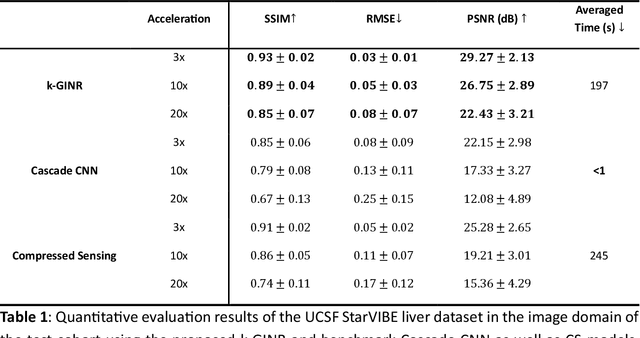
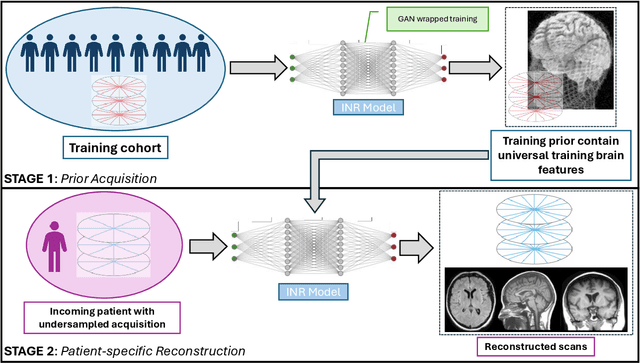
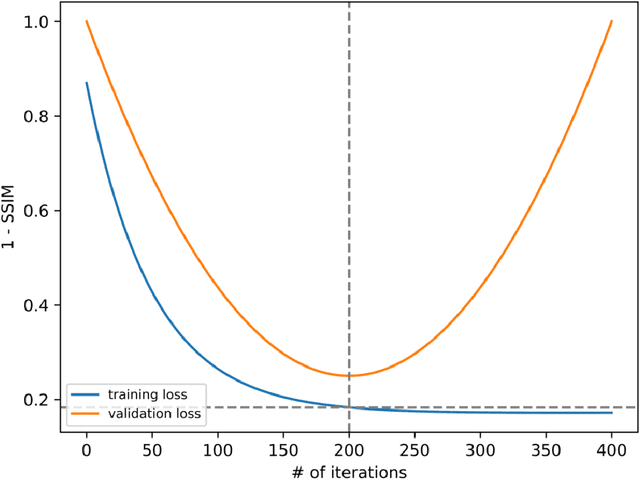
The scanning time for a fully sampled MRI can be undesirably lengthy. Compressed sensing has been developed to minimize image artifacts in accelerated scans, but the required iterative reconstruction is computationally complex and difficult to generalize on new cases. Image-domain-based deep learning methods (e.g., convolutional neural networks) emerged as a faster alternative but face challenges in modeling continuous k-space, a problem amplified with non-Cartesian sampling commonly used in accelerated acquisition. In comparison, implicit neural representations can model continuous signals in the frequency domain and thus are compatible with arbitrary k-space sampling patterns. The current study develops a novel generative-adversarially trained implicit neural representations (k-GINR) for de novo undersampled non-Cartesian k-space reconstruction. k-GINR consists of two stages: 1) supervised training on an existing patient cohort; 2) self-supervised patient-specific optimization. In stage 1, the network is trained with the generative-adversarial network on diverse patients of the same anatomical region supervised by fully sampled acquisition. In stage 2, undersampled k-space data of individual patients is used to tailor the prior-embedded network for patient-specific optimization. The UCSF StarVIBE T1-weighted liver dataset was evaluated on the proposed framework. k-GINR is compared with an image-domain deep learning method, Deep Cascade CNN, and a compressed sensing method. k-GINR consistently outperformed the baselines with a larger performance advantage observed at very high accelerations (e.g., 20 times). k-GINR offers great value for direct non-Cartesian k-space reconstruction for new incoming patients across a wide range of accelerations liver anatomy.
Rapid Reconstruction of Extremely Accelerated Liver 4D MRI via Chained Iterative Refinement
Dec 14, 2024



Abstract Purpose: High-quality 4D MRI requires an impractically long scanning time for dense k-space signal acquisition covering all respiratory phases. Accelerated sparse sampling followed by reconstruction enhancement is desired but often results in degraded image quality and long reconstruction time. We hereby propose the chained iterative reconstruction network (CIRNet) for efficient sparse-sampling reconstruction while maintaining clinically deployable quality. Methods: CIRNet adopts the denoising diffusion probabilistic framework to condition the image reconstruction through a stochastic iterative denoising process. During training, a forward Markovian diffusion process is designed to gradually add Gaussian noise to the densely sampled ground truth (GT), while CIRNet is optimized to iteratively reverse the Markovian process from the forward outputs. At the inference stage, CIRNet performs the reverse process solely to recover signals from noise, conditioned upon the undersampled input. CIRNet processed the 4D data (3D+t) as temporal slices (2D+t). The proposed framework is evaluated on a data cohort consisting of 48 patients (12332 temporal slices) who underwent free-breathing liver 4D MRI. 3-, 6-, 10-, 20- and 30-times acceleration were examined with a retrospective random undersampling scheme. Compressed sensing (CS) reconstruction with a spatiotemporal constraint and a recently proposed deep network, Re-Con-GAN, are selected as baselines. Results: CIRNet consistently achieved superior performance compared to CS and Re-Con-GAN. The inference time of CIRNet, CS, and Re-Con-GAN are 11s, 120s, and 0.15s. Conclusion: A novel framework, CIRNet, is presented. CIRNet maintains useable image quality for acceleration up to 30 times, significantly reducing the burden of 4DMRI.
TomoGRAF: A Robust and Generalizable Reconstruction Network for Single-View Computed Tomography
Nov 12, 2024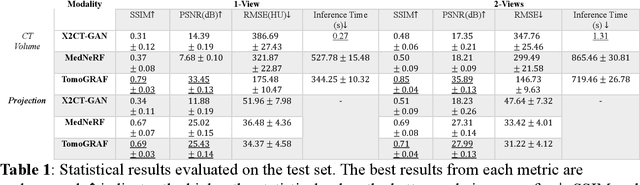

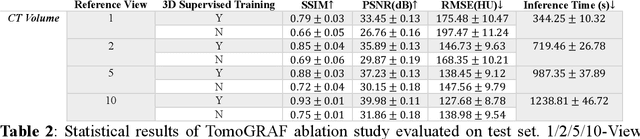

Computed tomography (CT) provides high spatial resolution visualization of 3D structures for scientific and clinical applications. Traditional analytical/iterative CT reconstruction algorithms require hundreds of angular data samplings, a condition that may not be met in practice due to physical and mechanical limitations. Sparse view CT reconstruction has been proposed using constrained optimization and machine learning methods with varying success, less so for ultra-sparse view CT reconstruction with one to two views. Neural radiance field (NeRF) is a powerful tool for reconstructing and rendering 3D natural scenes from sparse views, but its direct application to 3D medical image reconstruction has been minimally successful due to the differences between optical and X-ray photon transportation. Here, we develop a novel TomoGRAF framework incorporating the unique X-ray transportation physics to reconstruct high-quality 3D volumes using ultra-sparse projections without prior. TomoGRAF captures the CT imaging geometry, simulates the X-ray casting and tracing process, and penalizes the difference between simulated and ground truth CT sub-volume during training. We evaluated the performance of TomoGRAF on an unseen dataset of distinct imaging characteristics from the training data and demonstrated a vast leap in performance compared with state-of-the-art deep learning and NeRF methods. TomoGRAF provides the first generalizable solution for image-guided radiotherapy and interventional radiology applications, where only one or a few X-ray views are available, but 3D volumetric information is desired.
Paired Conditional Generative Adversarial Network for Highly Accelerated Liver 4D MRI
May 20, 2024Purpose: 4D MRI with high spatiotemporal resolution is desired for image-guided liver radiotherapy. Acquiring densely sampling k-space data is time-consuming. Accelerated acquisition with sparse samples is desirable but often causes degraded image quality or long reconstruction time. We propose the Reconstruct Paired Conditional Generative Adversarial Network (Re-Con-GAN) to shorten the 4D MRI reconstruction time while maintaining the reconstruction quality. Methods: Patients who underwent free-breathing liver 4D MRI were included in the study. Fully- and retrospectively under-sampled data at 3, 6 and 10 times (3x, 6x and 10x) were first reconstructed using the nuFFT algorithm. Re-Con-GAN then trained input and output in pairs. Three types of networks, ResNet9, UNet and reconstruction swin transformer, were explored as generators. PatchGAN was selected as the discriminator. Re-Con-GAN processed the data (3D+t) as temporal slices (2D+t). A total of 48 patients with 12332 temporal slices were split into training (37 patients with 10721 slices) and test (11 patients with 1611 slices). Results: Re-Con-GAN consistently achieved comparable/better PSNR, SSIM, and RMSE scores compared to CS/UNet models. The inference time of Re-Con-GAN, UNet and CS are 0.15s, 0.16s, and 120s. The GTV detection task showed that Re-Con-GAN and CS, compared to UNet, better improved the dice score (3x Re-Con-GAN 80.98%; 3x CS 80.74%; 3x UNet 79.88%) of unprocessed under-sampled images (3x 69.61%). Conclusion: A generative network with adversarial training is proposed with promising and efficient reconstruction results demonstrated on an in-house dataset. The rapid and qualitative reconstruction of 4D liver MR has the potential to facilitate online adaptive MR-guided radiotherapy for liver cancer.
Nodule detection and generation on chest X-rays: NODE21 Challenge
Jan 04, 2024



Pulmonary nodules may be an early manifestation of lung cancer, the leading cause of cancer-related deaths among both men and women. Numerous studies have established that deep learning methods can yield high-performance levels in the detection of lung nodules in chest X-rays. However, the lack of gold-standard public datasets slows down the progression of the research and prevents benchmarking of methods for this task. To address this, we organized a public research challenge, NODE21, aimed at the detection and generation of lung nodules in chest X-rays. While the detection track assesses state-of-the-art nodule detection systems, the generation track determines the utility of nodule generation algorithms to augment training data and hence improve the performance of the detection systems. This paper summarizes the results of the NODE21 challenge and performs extensive additional experiments to examine the impact of the synthetically generated nodule training images on the detection algorithm performance.
A Two-Step Framework for Multi-Material Decomposition of Dual Energy Computed Tomography from Projection Domain
Oct 31, 2023Dual-energy computed tomography (DECT) utilizes separate X-ray energy spectra to improve multi-material decomposition (MMD) for various diagnostic applications. However accurate decomposing more than two types of material remains challenging using conventional methods. Deep learning (DL) methods have shown promise to improve the MMD performance, but typical approaches of conducing DL-MMD in the image domain fail to fully utilize projection information or under iterative setup are computationally inefficient in both training and prediction. In this work, we present a clinical-applicable MMD (>2) framework rFast-MMDNet, operating with raw projection data in non-recursive setup, for breast tissue differentiation. rFast-MMDNet is a two-stage algorithm, including stage-one SinoNet to perform dual energy projection decomposition on tissue sinograms and stage-two FBP-DenoiseNet to perform domain adaptation and image post-processing. rFast-MMDNet was tested on a 2022 DL-Spectral-Challenge breast phantom dataset. The two stages of rFast-MMDNet were evaluated separately and then compared with four noniterative reference methods including a direct inversion method (AA-MMD), an image domain DL method (ID-UNet), AA-MMD/ID-UNet + DenoiseNet and a sinogram domain DL method (Triple-CBCT). Our results show that models trained from information stored in DE transmission domain can yield high-fidelity decomposition of the adipose, calcification, and fibroglandular materials with averaged RMSE, MAE, negative PSNR, and SSIM of 0.004+/-~0, 0.001+/-~0, -45.027+/-~0.542, and 0.002+/-~0 benchmarking to the ground truth, respectively. Training of entire rFast-MMDNet on a 4xRTX A6000 GPU cluster took a day with inference time <1s. All DL methods generally led to more accurate MMD than AA-MMD. rFast-MMDNet outperformed Triple-CBCT, but both are superior to the image-domain based methods.
Learning Dynamic MRI Reconstruction with Convolutional Network Assisted Reconstruction Swin Transformer
Sep 19, 2023
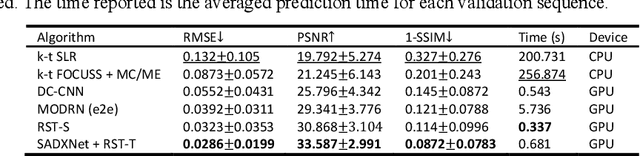

Dynamic magnetic resonance imaging (DMRI) is an effective imaging tool for diagnosis tasks that require motion tracking of a certain anatomy. To speed up DMRI acquisition, k-space measurements are commonly undersampled along spatial or spatial-temporal domains. The difficulty of recovering useful information increases with increasing undersampling ratios. Compress sensing was invented for this purpose and has become the most popular method until deep learning (DL) based DMRI reconstruction methods emerged in the past decade. Nevertheless, existing DL networks are still limited in long-range sequential dependency understanding and computational efficiency and are not fully automated. Considering the success of Transformers positional embedding and "swin window" self-attention mechanism in the vision community, especially natural video understanding, we hereby propose a novel architecture named Reconstruction Swin Transformer (RST) for 4D MRI. RST inherits the backbone design of the Video Swin Transformer with a novel reconstruction head introduced to restore pixel-wise intensity. A convolution network called SADXNet is used for rapid initialization of 2D MR frames before RST learning to effectively reduce the model complexity, GPU hardware demand, and training time. Experimental results in the cardiac 4D MR dataset further substantiate the superiority of RST, achieving the lowest RMSE of 0.0286 +/- 0.0199 and 1 - SSIM of 0.0872 +/- 0.0783 on 9 times accelerated validation sequences.
An Efficient and Robust Method for Chest X-Ray Rib Suppression that Improves Pulmonary Abnormality Diagnosis
Feb 19, 2023

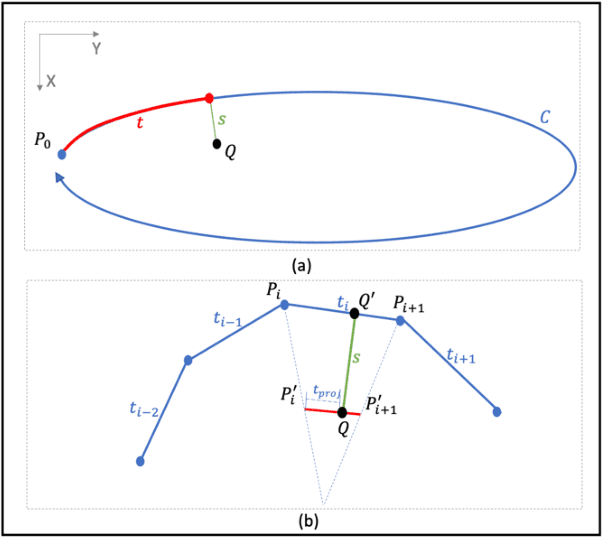

Suppression of thoracic bone shadows on chest X-rays (CXRs) has been indicated to improve the diagnosis of pulmonary disease. Previous approaches can be categorized as unsupervised physical and supervised deep learning models. Nevertheless, with physical models able to preserve morphological details but at the cost of extremely long processing time, existing DL methods face challenges of gathering sufficient/qualitative ground truth (GT) for robust training, thus leading to failure in maintaining clinically acceptable false positive rates. We hereby propose a generalizable yet efficient workflow of two stages: (1) training pairs generation with GT bone shadows eliminated in by a physical model in spatially transformed gradient fields. (2) fully supervised image denoising network training on stage-one datasets for fast rib removal on incoming CXRs. For step two, we designed a densely connected network called SADXNet, combined with peak signal to noise ratio and multi-scale structure similarity index measure objective minimization to suppress bony structures. The SADXNet organizes spatial filters in U shape (e.g., X=7; filters = 16, 64, 256, 512, 256, 64, 16) and preserves the feature map dimension throughout the network flow. Visually, SADXNet can suppress the rib edge and that near the lung wall/vertebra without jeopardizing the vessel/abnormality conspicuity. Quantitively, it achieves RMSE of ~0 during testing with one prediction taking <1s. Downstream tasks including lung nodule detection as well as common lung disease classification and localization are used to evaluate our proposed rib suppression mechanism. We observed 3.23% and 6.62% area under the curve (AUC) increase as well as 203 and 385 absolute false positive decrease for lung nodule detection and common lung disease localization, separately.
To what extent can Plug-and-Play methods outperform neural networks alone in low-dose CT reconstruction
Feb 15, 2022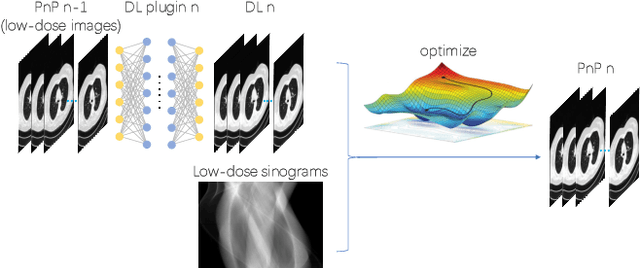
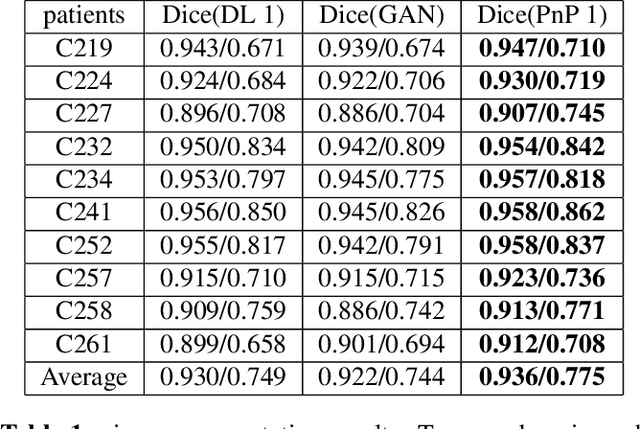

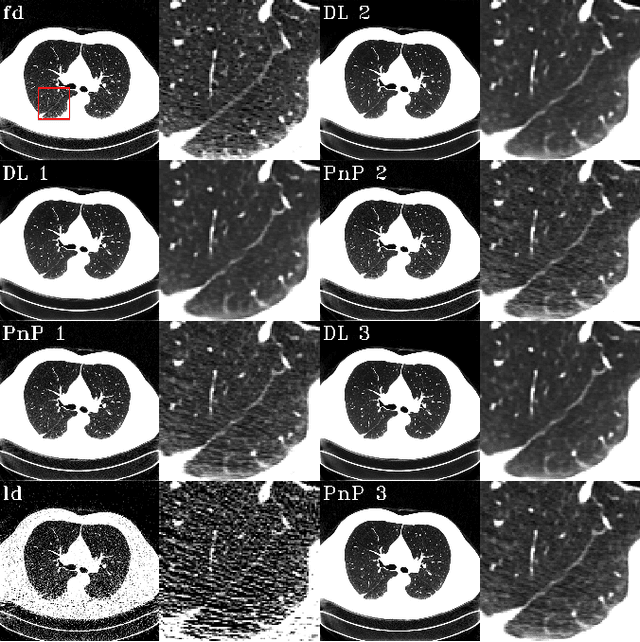
The Plug-and-Play (PnP) framework was recently introduced for low-dose CT reconstruction to leverage the interpretability and the flexibility of model-based methods to incorporate various plugins, such as trained deep learning (DL) neural networks. However, the benefits of PnP vs. state-of-the-art DL methods have not been clearly demonstrated. In this work, we proposed an improved PnP framework to address the previous limitations and develop clinical-relevant segmentation metrics for quantitative result assessment. Compared with the DL alone methods, our proposed PnP framework was slightly inferior in MSE and PSNR. However, the power spectrum of the resulting images better matched that of full-dose images than that of DL denoised images. The resulting images supported higher accuracy in airway segmentation than DL denoised images for all the ten patients in the test set, more substantially on the airways with a cross-section smaller than 0.61cm$^2$, and outperformed the DL denoised images for 45 out of 50 lung lobes in lobar segmentation. Our PnP method proved to be significantly better at preserving the image texture, which translated to task-specific benefits in automated structure segmentation and detection.
Fully Automated Pancreas Segmentation with Two-stage 3D Convolutional Neural Networks
Jun 05, 2019


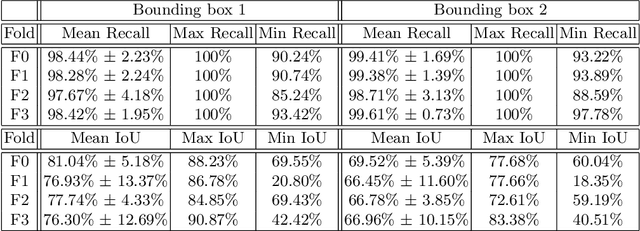
Due to the fact that pancreas is an abdominal organ with very large variations in shape and size, automatic and accurate pancreas segmentation can be challenging for medical image analysis. In this work, we proposed a fully automated two stage framework for pancreas segmentation based on convolutional neural networks (CNN). In the first stage, a U-Net is trained for the down-sampled 3D volume segmentation. Then a candidate region covering the pancreas is extracted from the estimated labels. Motivated by the superior performance reported by renowned region based CNN, in the second stage, another 3D U-Net is trained on the candidate region generated in the first stage. We evaluated the performance of the proposed method on the NIH computed tomography (CT) dataset, and verified its superiority over other state-of-the-art 2D and 3D approaches for pancreas segmentation in terms of dice-sorensen coefficient (DSC) accuracy in testing. The mean DSC of the proposed method is 85.99%.