 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesigning UNICORN: a Unified Benchmark for Imaging in Computational Pathology, Radiology, and Natural Language
Mar 03, 2026Medical foundation models show promise to learn broadly generalizable features from large, diverse datasets. This could be the base for reliable cross-modality generalization and rapid adaptation to new, task-specific goals, with only a few task-specific examples. Yet, evidence for this is limited by the lack of public, standardized, and reproducible evaluation frameworks, as existing public benchmarks are often fragmented across task-, organ-, or modality-specific settings, limiting assessment of cross-task generalization. We introduce UNICORN, a public benchmark designed to systematically evaluate medical foundation models under a unified protocol. To isolate representation quality, we built the benchmark on a novel two-step framework that decouples model inference from task-specific evaluation based on standardized few-shot adaptation. As a central design choice, we constructed indirectly accessible sequestered test sets derived from clinically relevant cohorts, along with standardized evaluation code and a submission interface on an open benchmarking platform. Performance is aggregated into a single UNICORN Score, a new metric that we introduce to support direct comparison of foundation models across diverse medical domains, modalities, and task types. The UNICORN test dataset includes data from more than 2,400 patients, including over 3,700 vision cases and over 2,400 clinical reports collected from 17 institutions across eight countries. The benchmark spans eight anatomical regions and four imaging modalities. Both task-specific and aggregated leaderboards enable accessible, standardized, and reproducible evaluation. By standardizing multi-task, multi-modality assessment, UNICORN establishes a foundation for reproducible benchmarking of medical foundation models. Data, baseline methods, and the evaluation platform are publicly available via unicorn.grand-challenge.org.
Medical Imaging AI Competitions Lack Fairness
Dec 19, 2025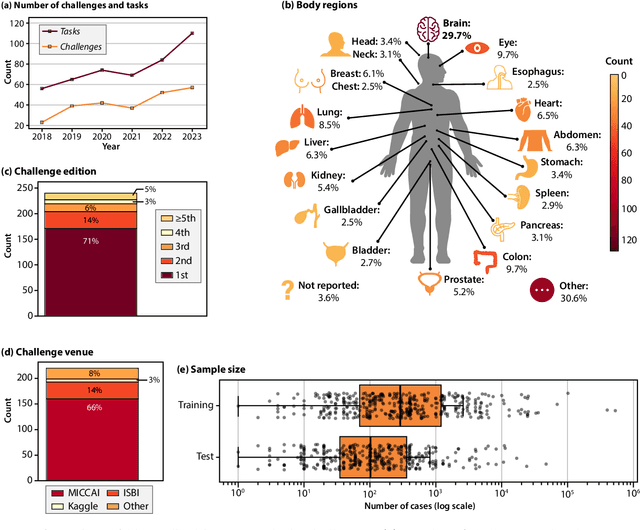
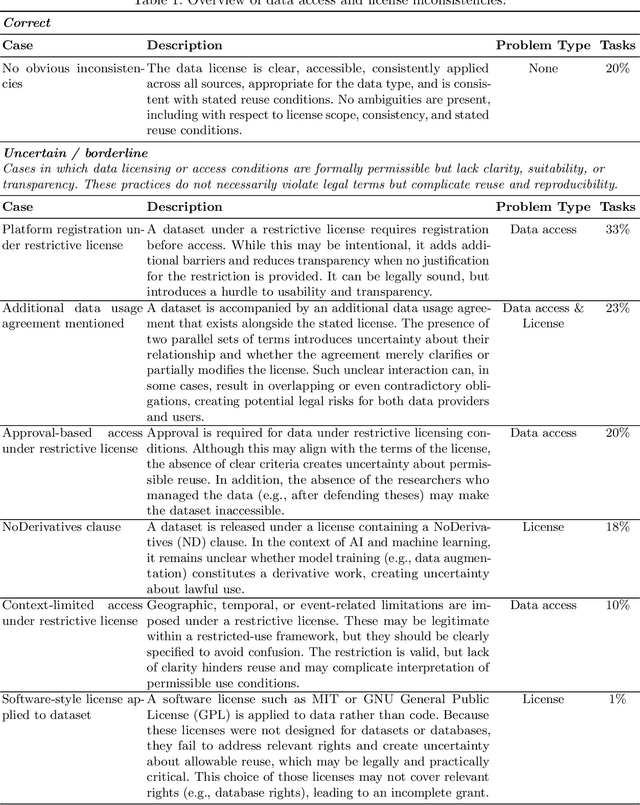
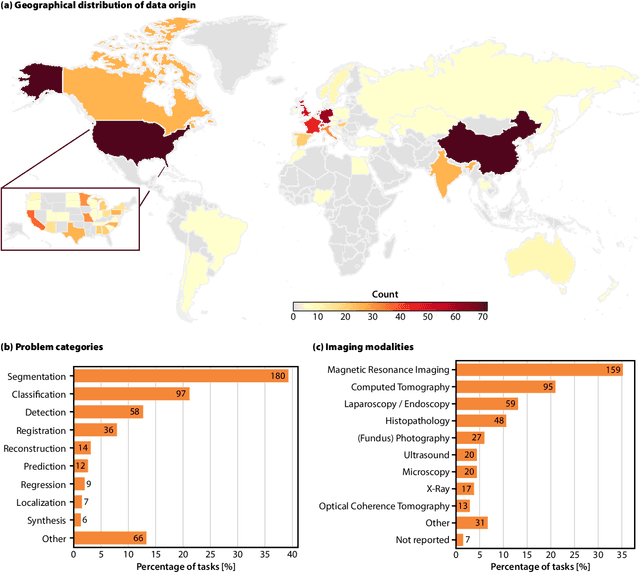
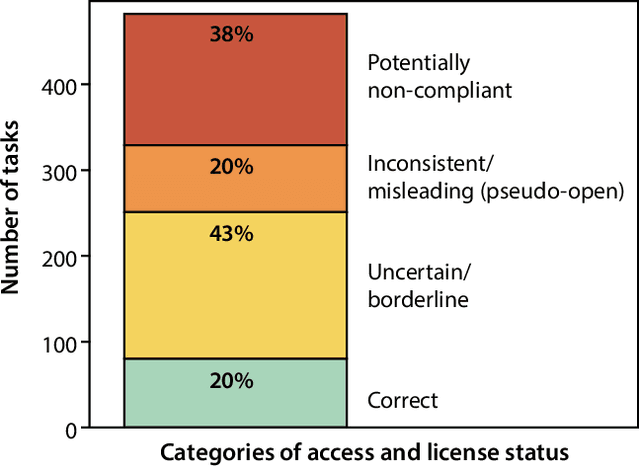
Benchmarking competitions are central to the development of artificial intelligence (AI) in medical imaging, defining performance standards and shaping methodological progress. However, it remains unclear whether these benchmarks provide data that are sufficiently representative, accessible, and reusable to support clinically meaningful AI. In this work, we assess fairness along two complementary dimensions: (1) whether challenge datasets are representative of real-world clinical diversity, and (2) whether they are accessible and legally reusable in line with the FAIR principles. To address this question, we conducted a large-scale systematic study of 241 biomedical image analysis challenges comprising 458 tasks across 19 imaging modalities. Our findings show substantial biases in dataset composition, including geographic location, modality-, and problem type-related biases, indicating that current benchmarks do not adequately reflect real-world clinical diversity. Despite their widespread influence, challenge datasets were frequently constrained by restrictive or ambiguous access conditions, inconsistent or non-compliant licensing practices, and incomplete documentation, limiting reproducibility and long-term reuse. Together, these shortcomings expose foundational fairness limitations in our benchmarking ecosystem and highlight a disconnect between leaderboard success and clinical relevance.
Robust Kidney Abnormality Segmentation: A Validation Study of an AI-Based Framework
May 12, 2025Kidney abnormality segmentation has important potential to enhance the clinical workflow, especially in settings requiring quantitative assessments. Kidney volume could serve as an important biomarker for renal diseases, with changes in volume correlating directly with kidney function. Currently, clinical practice often relies on subjective visual assessment for evaluating kidney size and abnormalities, including tumors and cysts, which are typically staged based on diameter, volume, and anatomical location. To support a more objective and reproducible approach, this research aims to develop a robust, thoroughly validated kidney abnormality segmentation algorithm, made publicly available for clinical and research use. We employ publicly available training datasets and leverage the state-of-the-art medical image segmentation framework nnU-Net. Validation is conducted using both proprietary and public test datasets, with segmentation performance quantified by Dice coefficient and the 95th percentile Hausdorff distance. Furthermore, we analyze robustness across subgroups based on patient sex, age, CT contrast phases, and tumor histologic subtypes. Our findings demonstrate that our segmentation algorithm, trained exclusively on publicly available data, generalizes effectively to external test sets and outperforms existing state-of-the-art models across all tested datasets. Subgroup analyses reveal consistent high performance, indicating strong robustness and reliability. The developed algorithm and associated code are publicly accessible at https://github.com/DIAGNijmegen/oncology-kidney-abnormality-segmentation.
Divide to Conquer: A Field Decomposition Approach for Multi-Organ Whole-Body CT Image Registration
Mar 28, 2025Image registration is an essential technique for the analysis of Computed Tomography (CT) images in clinical practice. However, existing methodologies are predominantly tailored to a specific organ of interest and often exhibit lower performance on other organs, thus limiting their generalizability and applicability. Multi-organ registration addresses these limitations, but the simultaneous alignment of multiple organs with diverse shapes, sizes and locations requires a highly complex deformation field with a multi-layer composition of individual deformations. This study introduces a novel field decomposition approach to address the high complexity of deformations in multi-organ whole-body CT image registration. The proposed method is trained and evaluated on a longitudinal dataset of 691 patients, each with two CT images obtained at distinct time points. These scans fully encompass the thoracic, abdominal, and pelvic regions. Two baseline registration methods are selected for this study: one based on optimization techniques and another based on deep learning. Experimental results demonstrate that the proposed approach outperforms baseline methods in handling complex deformations in multi-organ whole-body CT image registration.
Attenuation artifact detection and severity classification in intracoronary OCT using mixed image representations
Mar 07, 2025In intracoronary optical coherence tomography (OCT), blood residues and gas bubbles cause attenuation artifacts that can obscure critical vessel structures. The presence and severity of these artifacts may warrant re-acquisition, prolonging procedure time and increasing use of contrast agent. Accurate detection of these artifacts can guide targeted re-acquisition, reducing the amount of repeated scans needed to achieve diagnostically viable images. However, the highly heterogeneous appearance of these artifacts poses a challenge for the automated detection of the affected image regions. To enable automatic detection of the attenuation artifacts caused by blood residues and gas bubbles based on their severity, we propose a convolutional neural network that performs classification of the attenuation lines (A-lines) into three classes: no artifact, mild artifact and severe artifact. Our model extracts and merges features from OCT images in both Cartesian and polar coordinates, where each column of the image represents an A-line. Our method detects the presence of attenuation artifacts in OCT frames reaching F-scores of 0.77 and 0.94 for mild and severe artifacts, respectively. The inference time over a full OCT scan is approximately 6 seconds. Our experiments show that analysis of images represented in both Cartesian and polar coordinate systems outperforms the analysis in polar coordinates only, suggesting that these representations contain complementary features. This work lays the foundation for automated artifact assessment and image acquisition guidance in intracoronary OCT imaging.
In the Picture: Medical Imaging Datasets, Artifacts, and their Living Review
Jan 18, 2025


Datasets play a critical role in medical imaging research, yet issues such as label quality, shortcuts, and metadata are often overlooked. This lack of attention may harm the generalizability of algorithms and, consequently, negatively impact patient outcomes. While existing medical imaging literature reviews mostly focus on machine learning (ML) methods, with only a few focusing on datasets for specific applications, these reviews remain static -- they are published once and not updated thereafter. This fails to account for emerging evidence, such as biases, shortcuts, and additional annotations that other researchers may contribute after the dataset is published. We refer to these newly discovered findings of datasets as research artifacts. To address this gap, we propose a living review that continuously tracks public datasets and their associated research artifacts across multiple medical imaging applications. Our approach includes a framework for the living review to monitor data documentation artifacts, and an SQL database to visualize the citation relationships between research artifact and dataset. Lastly, we discuss key considerations for creating medical imaging datasets, review best practices for data annotation, discuss the significance of shortcuts and demographic diversity, and emphasize the importance of managing datasets throughout their entire lifecycle. Our demo is publicly available at http://130.226.140.142.
MRSegmentator: Robust Multi-Modality Segmentation of 40 Classes in MRI and CT Sequences
May 10, 2024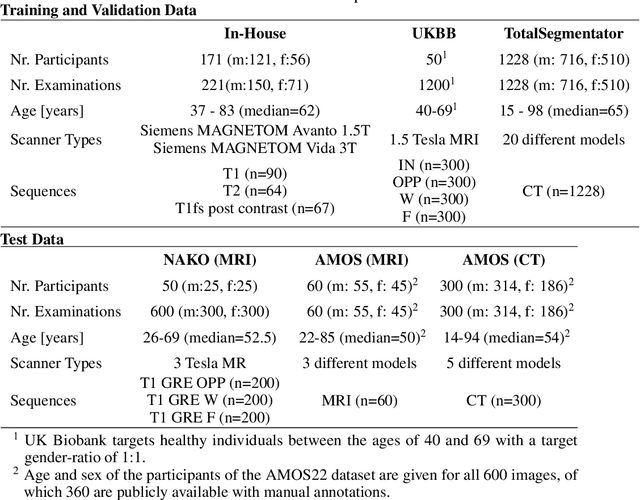
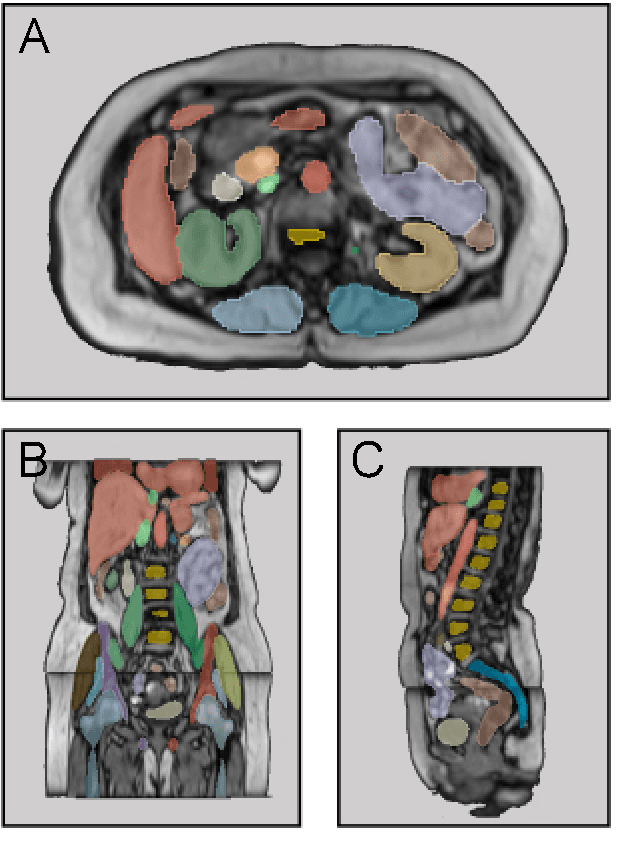
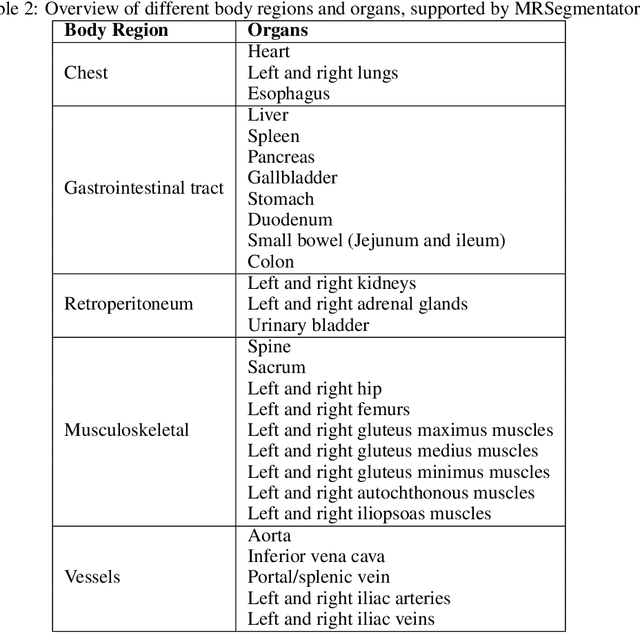
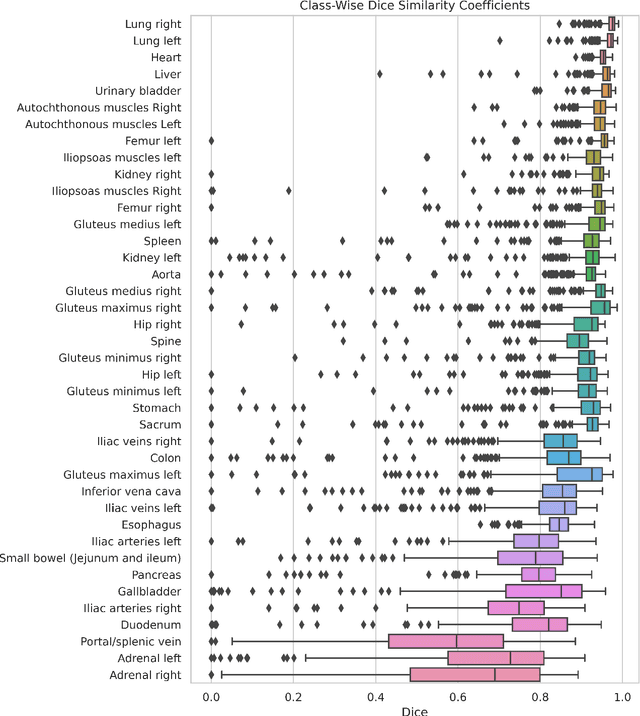
Purpose: To introduce a deep learning model capable of multi-organ segmentation in MRI scans, offering a solution to the current limitations in MRI analysis due to challenges in resolution, standardized intensity values, and variability in sequences. Materials and Methods: he model was trained on 1,200 manually annotated MRI scans from the UK Biobank, 221 in-house MRI scans and 1228 CT scans, leveraging cross-modality transfer learning from CT segmentation models. A human-in-the-loop annotation workflow was employed to efficiently create high-quality segmentations. The model's performance was evaluated on NAKO and the AMOS22 dataset containing 600 and 60 MRI examinations. Dice Similarity Coefficient (DSC) and Hausdorff Distance (HD) was used to assess segmentation accuracy. The model will be open sourced. Results: The model showcased high accuracy in segmenting well-defined organs, achieving Dice Similarity Coefficient (DSC) scores of 0.97 for the right and left lungs, and 0.95 for the heart. It also demonstrated robustness in organs like the liver (DSC: 0.96) and kidneys (DSC: 0.95 left, 0.95 right), which present more variability. However, segmentation of smaller and complex structures such as the portal and splenic veins (DSC: 0.54) and adrenal glands (DSC: 0.65 left, 0.61 right) revealed the need for further model optimization. Conclusion: The proposed model is a robust, tool for accurate segmentation of 40 anatomical structures in MRI and CT images. By leveraging cross-modality learning and interactive annotation, the model achieves strong performance and generalizability across diverse datasets, making it a valuable resource for researchers and clinicians. It is open source and can be downloaded from https://github.com/hhaentze/MRSegmentator.
Nodule detection and generation on chest X-rays: NODE21 Challenge
Jan 04, 2024



Pulmonary nodules may be an early manifestation of lung cancer, the leading cause of cancer-related deaths among both men and women. Numerous studies have established that deep learning methods can yield high-performance levels in the detection of lung nodules in chest X-rays. However, the lack of gold-standard public datasets slows down the progression of the research and prevents benchmarking of methods for this task. To address this, we organized a public research challenge, NODE21, aimed at the detection and generation of lung nodules in chest X-rays. While the detection track assesses state-of-the-art nodule detection systems, the generation track determines the utility of nodule generation algorithms to augment training data and hence improve the performance of the detection systems. This paper summarizes the results of the NODE21 challenge and performs extensive additional experiments to examine the impact of the synthetically generated nodule training images on the detection algorithm performance.
Transfer learning from a sparsely annotated dataset of 3D medical images
Nov 08, 2023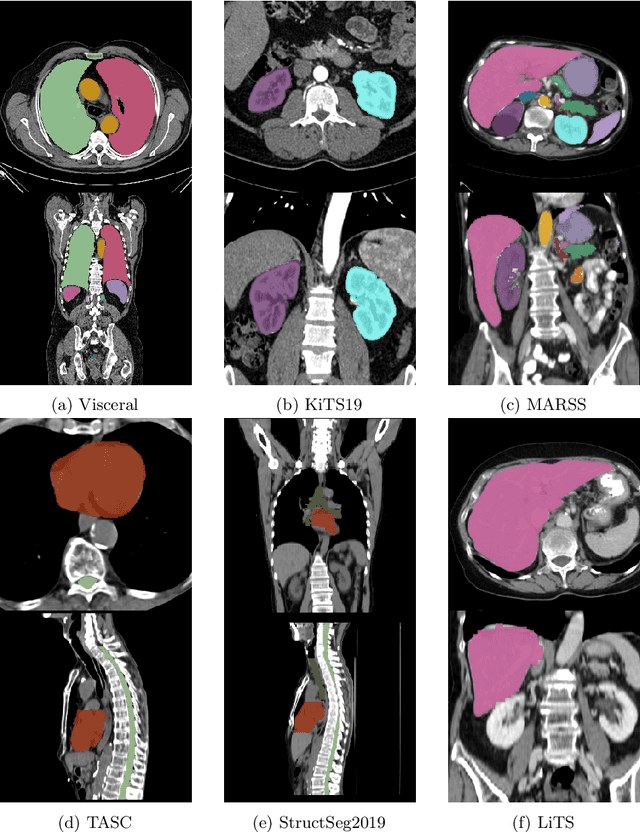
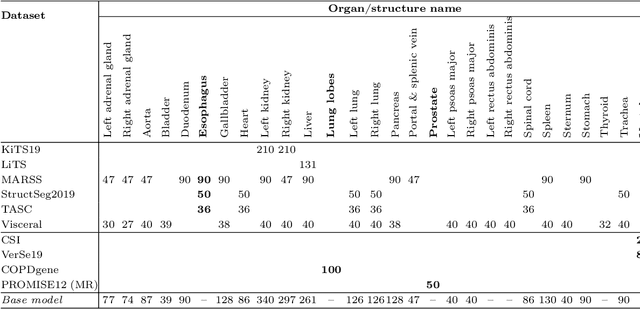
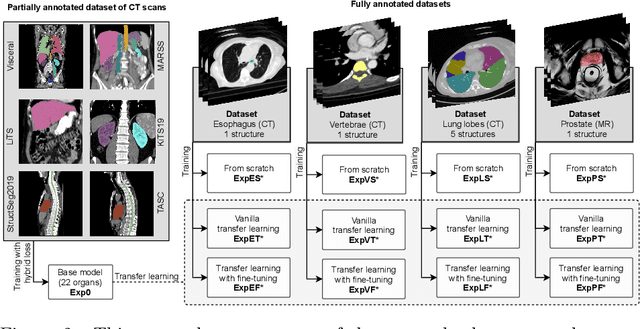

Transfer learning leverages pre-trained model features from a large dataset to save time and resources when training new models for various tasks, potentially enhancing performance. Due to the lack of large datasets in the medical imaging domain, transfer learning from one medical imaging model to other medical imaging models has not been widely explored. This study explores the use of transfer learning to improve the performance of deep convolutional neural networks for organ segmentation in medical imaging. A base segmentation model (3D U-Net) was trained on a large and sparsely annotated dataset; its weights were used for transfer learning on four new down-stream segmentation tasks for which a fully annotated dataset was available. We analyzed the training set size's influence to simulate scarce data. The results showed that transfer learning from the base model was beneficial when small datasets were available, providing significant performance improvements; where fine-tuning the base model is more beneficial than updating all the network weights with vanilla transfer learning. Transfer learning with fine-tuning increased the performance by up to 0.129 (+28\%) Dice score than experiments trained from scratch, and on average 23 experiments increased the performance by 0.029 Dice score in the new segmentation tasks. The study also showed that cross-modality transfer learning using CT scans was beneficial. The findings of this study demonstrate the potential of transfer learning to improve the efficiency of annotation and increase the accessibility of accurate organ segmentation in medical imaging, ultimately leading to improved patient care. We made the network definition and weights publicly available to benefit other users and researchers.
Kidney abnormality segmentation in thorax-abdomen CT scans
Sep 06, 2023
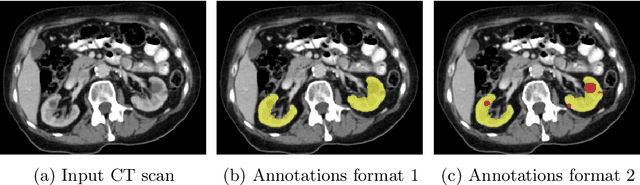


In this study, we introduce a deep learning approach for segmenting kidney parenchyma and kidney abnormalities to support clinicians in identifying and quantifying renal abnormalities such as cysts, lesions, masses, metastases, and primary tumors. Our end-to-end segmentation method was trained on 215 contrast-enhanced thoracic-abdominal CT scans, with half of these scans containing one or more abnormalities. We began by implementing our own version of the original 3D U-Net network and incorporated four additional components: an end-to-end multi-resolution approach, a set of task-specific data augmentations, a modified loss function using top-$k$, and spatial dropout. Furthermore, we devised a tailored post-processing strategy. Ablation studies demonstrated that each of the four modifications enhanced kidney abnormality segmentation performance, while three out of four improved kidney parenchyma segmentation. Subsequently, we trained the nnUNet framework on our dataset. By ensembling the optimized 3D U-Net and the nnUNet with our specialized post-processing, we achieved marginally superior results. Our best-performing model attained Dice scores of 0.965 and 0.947 for segmenting kidney parenchyma in two test sets (20 scans without abnormalities and 30 with abnormalities), outperforming an independent human observer who scored 0.944 and 0.925, respectively. In segmenting kidney abnormalities within the 30 test scans containing them, the top-performing method achieved a Dice score of 0.585, while an independent second human observer reached a score of 0.664, suggesting potential for further improvement in computerized methods. All training data is available to the research community under a CC-BY 4.0 license on https://doi.org/10.5281/zenodo.8014289