 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMed-DualLoRA: Local Adaptation of Foundation Models for 3D Cardiac MRI
Mar 11, 2026Foundation models (FMs) show great promise for robust downstream performance across medical imaging tasks and modalities, including cardiac magnetic resonance (CMR), following task-specific adaptation. However, adaptation using single-site data may lead to suboptimal performance and increased model bias, while centralized fine-tuning on clinical data is often infeasible due to privacy constraints. Federated fine-tuning offers a privacy-preserving alternative; yet conventional approaches struggle under heterogeneous, non-IID multi-center data and incur substantial communication overhead when adapting large models. In this work, we study federated FM fine-tuning for 3D CMR disease detection and propose Med-DualLoRA, a client-aware parameter-efficient fine-tuning (PEFT) federated framework that disentangles globally shared and local low-rank adaptations (LoRA) through additive decomposition. Global and local LoRA modules are trained locally, but only the global component is shared and aggregated across sites, keeping local adapters private. This design improves personalization while significantly reducing communication cost, and experiments show that adapting only two transformer blocks preserves performance while further improving efficiency. We evaluate our method on a multi-center state-of-the-art cine 3D CMR FM fine-tuned for disease detection using ACDC and combined M\&Ms datasets, treating each vendor as a federated client. Med-DualLoRA achieves statistically significant improved performance (balanced accuracy 0.768, specificity 0.612) compared to other federated PEFT baselines, while maintaining communication efficiency. Our approach provides a scalable solution for local federated adaptation of medical FMs under realistic clinical constraints.
Medical Imaging AI Competitions Lack Fairness
Dec 19, 2025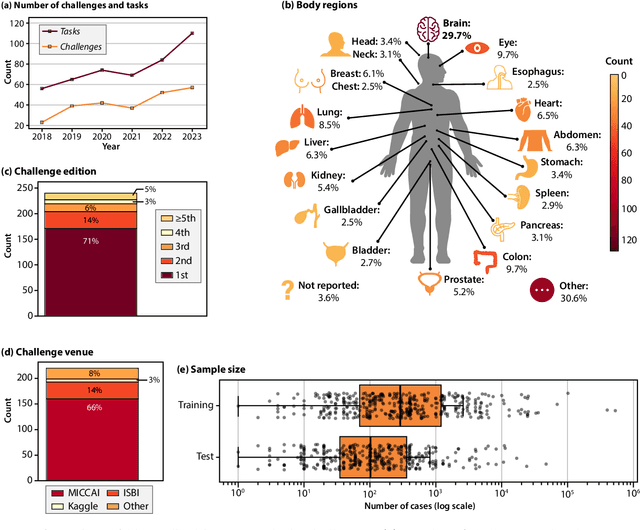
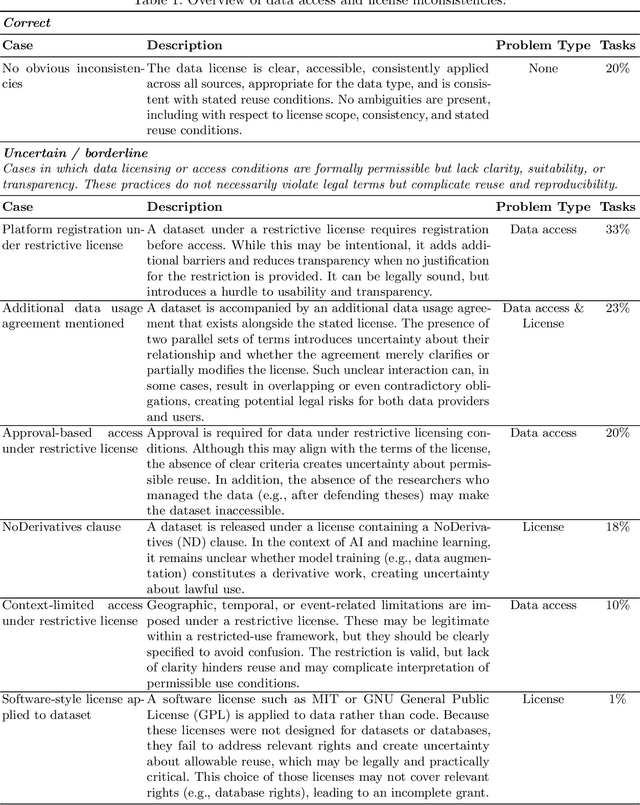
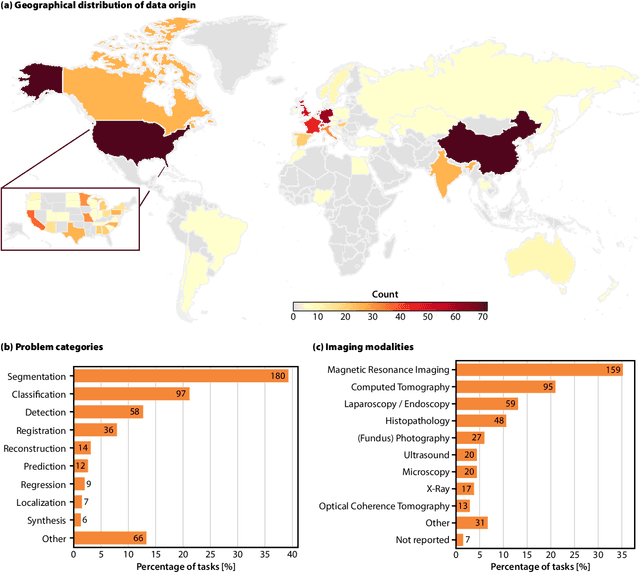
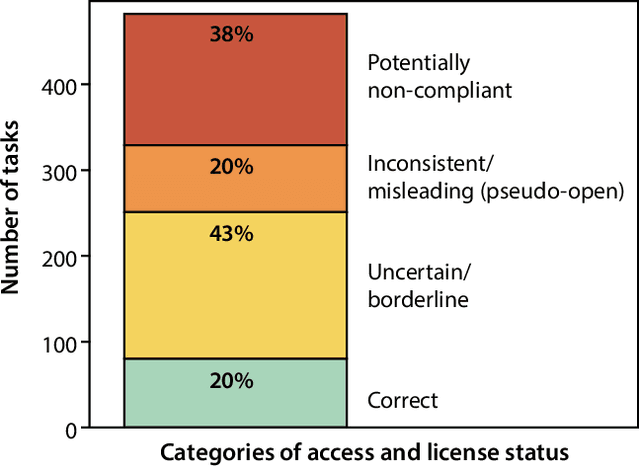
Benchmarking competitions are central to the development of artificial intelligence (AI) in medical imaging, defining performance standards and shaping methodological progress. However, it remains unclear whether these benchmarks provide data that are sufficiently representative, accessible, and reusable to support clinically meaningful AI. In this work, we assess fairness along two complementary dimensions: (1) whether challenge datasets are representative of real-world clinical diversity, and (2) whether they are accessible and legally reusable in line with the FAIR principles. To address this question, we conducted a large-scale systematic study of 241 biomedical image analysis challenges comprising 458 tasks across 19 imaging modalities. Our findings show substantial biases in dataset composition, including geographic location, modality-, and problem type-related biases, indicating that current benchmarks do not adequately reflect real-world clinical diversity. Despite their widespread influence, challenge datasets were frequently constrained by restrictive or ambiguous access conditions, inconsistent or non-compliant licensing practices, and incomplete documentation, limiting reproducibility and long-term reuse. Together, these shortcomings expose foundational fairness limitations in our benchmarking ecosystem and highlight a disconnect between leaderboard success and clinical relevance.
In the Picture: Medical Imaging Datasets, Artifacts, and their Living Review
Jan 18, 2025


Datasets play a critical role in medical imaging research, yet issues such as label quality, shortcuts, and metadata are often overlooked. This lack of attention may harm the generalizability of algorithms and, consequently, negatively impact patient outcomes. While existing medical imaging literature reviews mostly focus on machine learning (ML) methods, with only a few focusing on datasets for specific applications, these reviews remain static -- they are published once and not updated thereafter. This fails to account for emerging evidence, such as biases, shortcuts, and additional annotations that other researchers may contribute after the dataset is published. We refer to these newly discovered findings of datasets as research artifacts. To address this gap, we propose a living review that continuously tracks public datasets and their associated research artifacts across multiple medical imaging applications. Our approach includes a framework for the living review to monitor data documentation artifacts, and an SQL database to visualize the citation relationships between research artifact and dataset. Lastly, we discuss key considerations for creating medical imaging datasets, review best practices for data annotation, discuss the significance of shortcuts and demographic diversity, and emphasize the importance of managing datasets throughout their entire lifecycle. Our demo is publicly available at http://130.226.140.142.
Mask of truth: model sensitivity to unexpected regions of medical images
Dec 05, 2024The development of larger models for medical image analysis has led to increased performance. However, it also affected our ability to explain and validate model decisions. Models can use non-relevant parts of images, also called spurious correlations or shortcuts, to obtain high performance on benchmark datasets but fail in real-world scenarios. In this work, we challenge the capacity of convolutional neural networks (CNN) to classify chest X-rays and eye fundus images while masking out clinically relevant parts of the image. We show that all models trained on the PadChest dataset, irrespective of the masking strategy, are able to obtain an Area Under the Curve (AUC) above random. Moreover, the models trained on full images obtain good performance on images without the region of interest (ROI), even superior to the one obtained on images only containing the ROI. We also reveal a possible spurious correlation in the Chaksu dataset while the performances are more aligned with the expectation of an unbiased model. We go beyond the performance analysis with the usage of the explainability method SHAP and the analysis of embeddings. We asked a radiology resident to interpret chest X-rays under different masking to complement our findings with clinical knowledge. Our code is available at https://github.com/TheoSourget/MMC_Masking and https://github.com/TheoSourget/MMC_Masking_EyeFundus
Source Matters: Source Dataset Impact on Model Robustness in Medical Imaging
Mar 07, 2024Transfer learning has become an essential part of medical imaging classification algorithms, often leveraging ImageNet weights. However, the domain shift from natural to medical images has prompted alternatives such as RadImageNet, often demonstrating comparable classification performance. However, it remains unclear whether the performance gains from transfer learning stem from improved generalization or shortcut learning. To address this, we investigate potential confounders -- whether synthetic or sampled from the data -- across two publicly available chest X-ray and CT datasets. We show that ImageNet and RadImageNet achieve comparable classification performance, yet ImageNet is much more prone to overfitting to confounders. We recommend that researchers using ImageNet-pretrained models reexamine their model robustness by conducting similar experiments. Our code and experiments are available at https://github.com/DovileDo/source-matters.
Towards actionability for open medical imaging datasets: lessons from community-contributed platforms for data management and stewardship
Feb 09, 2024



Medical imaging datasets are fundamental to artificial intelligence (AI) in healthcare. The accuracy, robustness and fairness of diagnostic algorithms depend on the data (and its quality) on which the models are trained and evaluated. Medical imaging datasets have become increasingly available to the public, and are often hosted on Community-Contributed Platforms (CCP), including private companies like Kaggle or HuggingFace. While open data is important to enhance the redistribution of data's public value, we find that the current CCP governance model fails to uphold the quality needed and recommended practices for sharing, documenting, and evaluating datasets. In this paper we investigate medical imaging datasets on CCPs and how they are documented, shared, and maintained. We first highlight some differences between medical imaging and computer vision, particularly in the potentially harmful downstream effects due to poor adoption of recommended dataset management practices. We then analyze 20 (10 medical and 10 computer vision) popular datasets on CCPs and find vague licenses, lack of persistent identifiers and storage, duplicates and missing metadata, with differences between the platforms. We present "actionability" as a conceptual metric to reveal the data quality gap between characteristics of data on CCPs and the desired characteristics of data for AI in healthcare. Finally, we propose a commons-based stewardship model for documenting, sharing and maintaining datasets on CCPs and end with a discussion of limitations and open questions.
Data usage and citation practices in medical imaging conferences
Feb 05, 2024



Medical imaging papers often focus on methodology, but the quality of the algorithms and the validity of the conclusions are highly dependent on the datasets used. As creating datasets requires a lot of effort, researchers often use publicly available datasets, there is however no adopted standard for citing the datasets used in scientific papers, leading to difficulty in tracking dataset usage. In this work, we present two open-source tools we created that could help with the detection of dataset usage, a pipeline \url{https://github.com/TheoSourget/Public_Medical_Datasets_References} using OpenAlex and full-text analysis, and a PDF annotation software \url{https://github.com/TheoSourget/pdf_annotator} used in our study to manually label the presence of datasets. We applied both tools on a study of the usage of 20 publicly available medical datasets in papers from MICCAI and MIDL. We compute the proportion and the evolution between 2013 and 2023 of 3 types of presence in a paper: cited, mentioned in the full text, cited and mentioned. Our findings demonstrate the concentration of the usage of a limited set of datasets. We also highlight different citing practices, making the automation of tracking difficult.
Augmenting Chest X-ray Datasets with Non-Expert Annotations
Sep 05, 2023The advancement of machine learning algorithms in medical image analysis requires the expansion of training datasets. A popular and cost-effective approach is automated annotation extraction from free-text medical reports, primarily due to the high costs associated with expert clinicians annotating chest X-ray images. However, it has been shown that the resulting datasets are susceptible to biases and shortcuts. Another strategy to increase the size of a dataset is crowdsourcing, a widely adopted practice in general computer vision with some success in medical image analysis. In a similar vein to crowdsourcing, we enhance two publicly available chest X-ray datasets by incorporating non-expert annotations. However, instead of using diagnostic labels, we annotate shortcuts in the form of tubes. We collect 3.5k chest drain annotations for CXR14, and 1k annotations for 4 different tube types in PadChest. We train a chest drain detector with the non-expert annotations that generalizes well to expert labels. Moreover, we compare our annotations to those provided by experts and show "moderate" to "almost perfect" agreement. Finally, we present a pathology agreement study to raise awareness about ground truth annotations. We make our annotations and code available.
Detecting Shortcuts in Medical Images -- A Case Study in Chest X-rays
Nov 09, 2022The availability of large public datasets and the increased amount of computing power have shifted the interest of the medical community to high-performance algorithms. However, little attention is paid to the quality of the data and their annotations. High performance on benchmark datasets may be reported without considering possible shortcuts or artifacts in the data, besides, models are not tested on subpopulation groups. With this work, we aim to raise awareness about shortcuts problems. We validate previous findings, and present a case study on chest X-rays using two publicly available datasets. We share annotations for a subset of pneumothorax images with drains. We conclude with general recommendations for medical image classification.
Memory-aware curriculum federated learning for breast cancer classification
Jul 06, 2021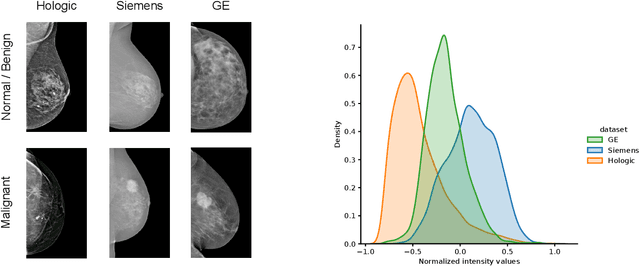
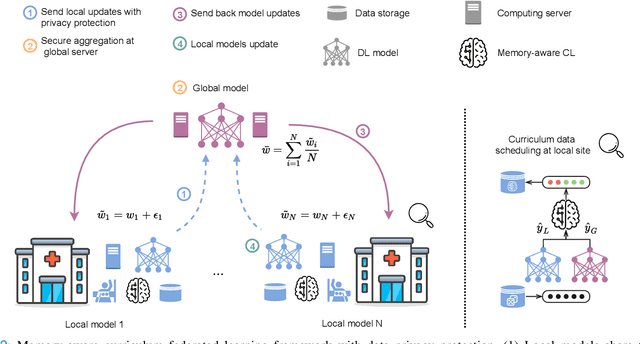
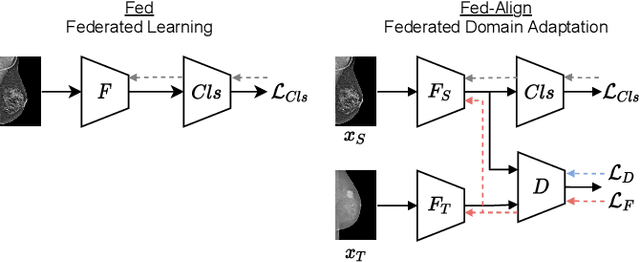
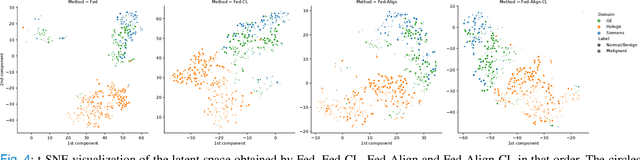
For early breast cancer detection, regular screening with mammography imaging is recommended. Routinary examinations result in datasets with a predominant amount of negative samples. A potential solution to such class-imbalance is joining forces across multiple institutions. Developing a collaborative computer-aided diagnosis system is challenging in different ways. Patient privacy and regulations need to be carefully respected. Data across institutions may be acquired from different devices or imaging protocols, leading to heterogeneous non-IID data. Also, for learning-based methods, new optimization strategies working on distributed data are required. Recently, federated learning has emerged as an effective tool for collaborative learning. In this setting, local models perform computation on their private data to update the global model. The order and the frequency of local updates influence the final global model. Hence, the order in which samples are locally presented to the optimizers plays an important role. In this work, we define a memory-aware curriculum learning method for the federated setting. Our curriculum controls the order of the training samples paying special attention to those that are forgotten after the deployment of the global model. Our approach is combined with unsupervised domain adaptation to deal with domain shift while preserving data privacy. We evaluate our method with three clinical datasets from different vendors. Our results verify the effectiveness of federated adversarial learning for the multi-site breast cancer classification. Moreover, we show that our proposed memory-aware curriculum method is beneficial to further improve classification performance. Our code is publicly available at: https://github.com/ameliajimenez/curriculum-federated-learning.