 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Cone Effect and Modality Gap in Medical Vision-Language Embeddings
Mar 18, 2026Vision-Language Models (VLMs) exhibit a characteristic "cone effect" in which nonlinear encoders map embeddings into highly concentrated regions of the representation space, contributing to cross-modal separation known as the modality gap. While this phenomenon has been widely observed, its practical impact on supervised multimodal learning -particularly in medical domains- remains unclear. In this work, we introduce a lightweight post-hoc mechanism that keeps pretrained VLM encoders frozen while continuously controlling cross-modal separation through a single hyperparameter {λ}. This enables systematic analysis of how the modality gap affects downstream multimodal performance without expensive retraining. We evaluate generalist (CLIP, SigLIP) and medically specialized (BioMedCLIP, MedSigLIP) models across diverse medical and natural datasets in a supervised multimodal settings. Results consistently show that reducing excessive modality gap improves downstream performance, with medical datasets exhibiting stronger sensitivity to gap modulation; however, fully collapsing the gap is not always optimal, and intermediate, task-dependent separation yields the best results. These findings position the modality gap as a tunable property of multimodal representations rather than a quantity that should be universally minimized.
Inference-Time Toxicity Mitigation in Protein Language Models
Mar 04, 2026Protein language models (PLMs) are becoming practical tools for de novo protein design, yet their dual-use potential raises safety concerns. We show that domain adaptation to specific taxonomic groups can elicit toxic protein generation, even when toxicity is not the training objective. To address this, we adapt Logit Diff Amplification (LDA) as an inference-time control mechanism for PLMs. LDA modifies token probabilities by amplifying the logit difference between a baseline model and a toxicity-finetuned model, requiring no retraining. Across four taxonomic groups, LDA consistently reduces predicted toxicity rate (measured via ToxDL2) below the taxon-finetuned baseline while preserving biological plausibility. We evaluate quality using Fréchet ESM Distance and predicted foldability (pLDDT), finding that LDA maintains distributional similarity to natural proteins and structural viability (unlike activation-based steering methods that tend to degrade sequence properties). Our results demonstrate that LDA provides a practical safety knob for protein generators that mitigates elicited toxicity while retaining generative quality.
Mask-HybridGNet: Graph-based segmentation with emergent anatomical correspondence from pixel-level supervision
Feb 24, 2026Graph-based medical image segmentation represents anatomical structures using boundary graphs, providing fixed-topology landmarks and inherent population-level correspondences. However, their clinical adoption has been hindered by a major requirement: training datasets with manually annotated landmarks that maintain point-to-point correspondences across patients rarely exist in practice. We introduce Mask-HybridGNet, a framework that trains graph-based models directly using standard pixel-wise masks, eliminating the need for manual landmark annotations. Our approach aligns variable-length ground truth boundaries with fixed-length landmark predictions by combining Chamfer distance supervision and edge-based regularization to ensure local smoothness and regular landmark distribution, further refined via differentiable rasterization. A significant emergent property of this framework is that predicted landmark positions become consistently associated with specific anatomical locations across patients without explicit correspondence supervision. This implicit atlas learning enables temporal tracking, cross-slice reconstruction, and morphological population analyses. Beyond direct segmentation, Mask-HybridGNet can extract correspondences from existing segmentation masks, allowing it to generate stable anatomical atlases from any high-quality pixel-based model. Experiments across chest radiography, cardiac ultrasound, cardiac MRI, and fetal imaging demonstrate that our model achieves competitive results against state-of-the-art pixel-based methods, while ensuring anatomical plausibility by enforcing boundary connectivity through a fixed graph adjacency matrix. This framework leverages the vast availability of standard segmentation masks to build structured models that maintain topological integrity and provide implicit correspondences.
CheXmask-U: Quantifying uncertainty in landmark-based anatomical segmentation for X-ray images
Dec 11, 2025Uncertainty estimation is essential for the safe clinical deployment of medical image segmentation systems, enabling the identification of unreliable predictions and supporting human oversight. While prior work has largely focused on pixel-level uncertainty, landmark-based segmentation offers inherent topological guarantees yet remains underexplored from an uncertainty perspective. In this work, we study uncertainty estimation for anatomical landmark-based segmentation on chest X-rays. Inspired by hybrid neural network architectures that combine standard image convolutional encoders with graph-based generative decoders, and leveraging their variational latent space, we derive two complementary measures: (i) latent uncertainty, captured directly from the learned distribution parameters, and (ii) predictive uncertainty, obtained by generating multiple stochastic output predictions from latent samples. Through controlled corruption experiments we show that both uncertainty measures increase with perturbation severity, reflecting both global and local degradation. We demonstrate that these uncertainty signals can identify unreliable predictions by comparing with manual ground-truth, and support out-of-distribution detection on the CheXmask dataset. More importantly, we release CheXmask-U (huggingface.co/datasets/mcosarinsky/CheXmask-U), a large scale dataset of 657,566 chest X-ray landmark segmentations with per-node uncertainty estimates, enabling researchers to account for spatial variations in segmentation quality when using these anatomical masks. Our findings establish uncertainty estimation as a promising direction to enhance robustness and safe deployment of landmark-based anatomical segmentation methods in chest X-ray. A fully working interactive demo of the method is available at huggingface.co/spaces/matiasky/CheXmask-U and the source code at github.com/mcosarinsky/CheXmask-U.
PVeRA: Probabilistic Vector-Based Random Matrix Adaptation
Dec 08, 2025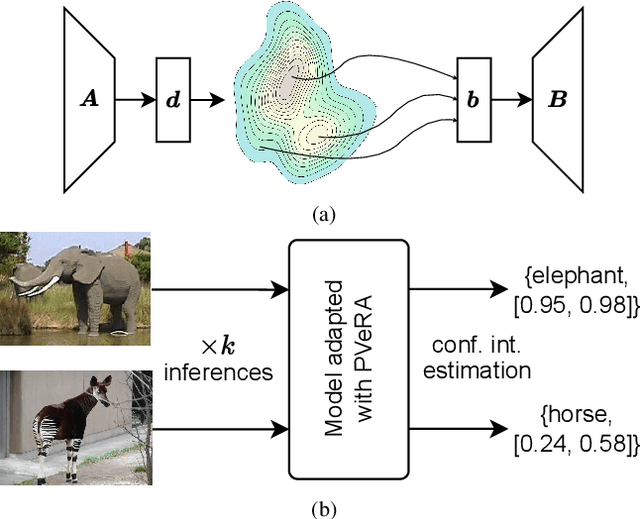
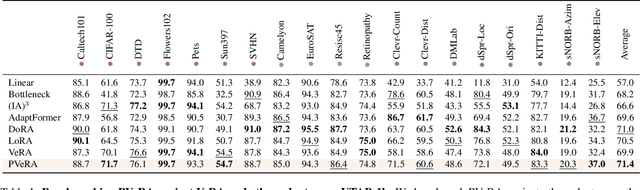
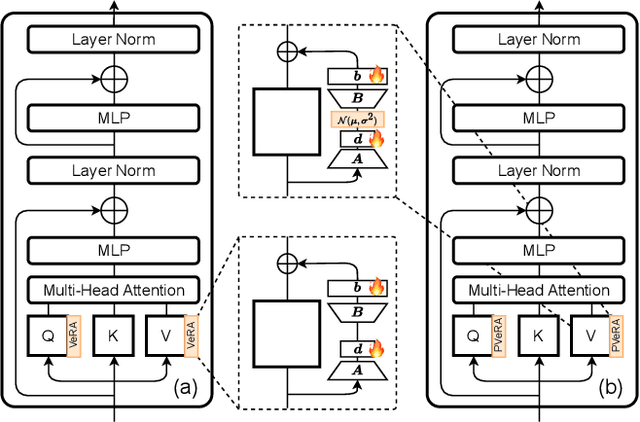

Large foundation models have emerged in the last years and are pushing performance boundaries for a variety of tasks. Training or even finetuning such models demands vast datasets and computational resources, which are often scarce and costly. Adaptation methods provide a computationally efficient solution to address these limitations by allowing such models to be finetuned on small amounts of data and computing power. This is achieved by appending new trainable modules to frozen backbones with only a fraction of the trainable parameters and fitting only these modules on novel tasks. Recently, the VeRA adapter was shown to excel in parameter-efficient adaptations by utilizing a pair of frozen random low-rank matrices shared across all layers. In this paper, we propose PVeRA, a probabilistic version of the VeRA adapter, which modifies the low-rank matrices of VeRA in a probabilistic manner. This modification naturally allows handling inherent ambiguities in the input and allows for different sampling configurations during training and testing. A comprehensive evaluation was performed on the VTAB-1k benchmark and seven adapters, with PVeRA outperforming VeRA and other adapters. Our code for training models with PVeRA and benchmarking all adapters is available https://github.com/leofillioux/pvera.
On the Risk of Misleading Reports: Diagnosing Textual Biases in Multimodal Clinical AI
Jul 31, 2025



Clinical decision-making relies on the integrated analysis of medical images and the associated clinical reports. While Vision-Language Models (VLMs) can offer a unified framework for such tasks, they can exhibit strong biases toward one modality, frequently overlooking critical visual cues in favor of textual information. In this work, we introduce Selective Modality Shifting (SMS), a perturbation-based approach to quantify a model's reliance on each modality in binary classification tasks. By systematically swapping images or text between samples with opposing labels, we expose modality-specific biases. We assess six open-source VLMs-four generalist models and two fine-tuned for medical data-on two medical imaging datasets with distinct modalities: MIMIC-CXR (chest X-ray) and FairVLMed (scanning laser ophthalmoscopy). By assessing model performance and the calibration of every model in both unperturbed and perturbed settings, we reveal a marked dependency on text input, which persists despite the presence of complementary visual information. We also perform a qualitative attention-based analysis which further confirms that image content is often overshadowed by text details. Our findings highlight the importance of designing and evaluating multimodal medical models that genuinely integrate visual and textual cues, rather than relying on single-modality signals.
Towards Reliable WMH Segmentation under Domain Shift: An Application Study using Maximum Entropy Regularization to Improve Uncertainty Estimation
Jun 17, 2025Accurate segmentation of white matter hyperintensities (WMH) is crucial for clinical decision-making, particularly in the context of multiple sclerosis. However, domain shifts, such as variations in MRI machine types or acquisition parameters, pose significant challenges to model calibration and uncertainty estimation. This study investigates the impact of domain shift on WMH segmentation by proposing maximum-entropy regularization techniques to enhance model calibration and uncertainty estimation, with the purpose of identifying errors post-deployment using predictive uncertainty as a proxy measure that does not require ground-truth labels. To do this, we conducted experiments using a U-Net architecture to evaluate these regularization schemes on two publicly available datasets, assessing performance with the Dice coefficient, expected calibration error, and entropy-based uncertainty estimates. Our results show that entropy-based uncertainty estimates can anticipate segmentation errors, and that maximum-entropy regularization further strengthens the correlation between uncertainty and segmentation performance while also improving model calibration under domain shift.
Performance Estimation for Supervised Medical Image Segmentation Models on Unlabeled Data Using UniverSeg
Apr 22, 2025The performance of medical image segmentation models is usually evaluated using metrics like the Dice score and Hausdorff distance, which compare predicted masks to ground truth annotations. However, when applying the model to unseen data, such as in clinical settings, it is often impractical to annotate all the data, making the model's performance uncertain. To address this challenge, we propose the Segmentation Performance Evaluator (SPE), a framework for estimating segmentation models' performance on unlabeled data. This framework is adaptable to various evaluation metrics and model architectures. Experiments on six publicly available datasets across six evaluation metrics including pixel-based metrics such as Dice score and distance-based metrics like HD95, demonstrated the versatility and effectiveness of our approach, achieving a high correlation (0.956$\pm$0.046) and low MAE (0.025$\pm$0.019) compare with real Dice score on the independent test set. These results highlight its ability to reliably estimate model performance without requiring annotations. The SPE framework integrates seamlessly into any model training process without adding training overhead, enabling performance estimation and facilitating the real-world application of medical image segmentation algorithms. The source code is publicly available
ChronoRoot 2.0: An Open AI-Powered Platform for 2D Temporal Plant Phenotyping
Apr 20, 2025



The analysis of plant developmental plasticity, including root system architecture, is fundamental to understanding plant adaptability and development, particularly in the context of climate change and agricultural sustainability. While significant advances have been made in plant phenotyping technologies, comprehensive temporal analysis of root development remains challenging, with most existing solutions providing either limited throughput or restricted structural analysis capabilities. Here, we present ChronoRoot 2.0, an integrated open-source platform that combines affordable hardware with advanced artificial intelligence to enable sophisticated temporal plant phenotyping. The system introduces several major advances, offering an integral perspective of seedling development: (i) simultaneous multi-organ tracking of six distinct plant structures, (ii) quality control through real-time validation, (iii) comprehensive architectural measurements including novel gravitropic response parameters, and (iv) dual specialized user interfaces for both architectural analysis and high-throughput screening. We demonstrate the system's capabilities through three use cases for Arabidopsis thaliana: characterization of circadian growth patterns under different light conditions, detailed analysis of gravitropic responses in transgenic plants, and high-throughput screening of etiolation responses across multiple genotypes. ChronoRoot 2.0 maintains its predecessor's advantages of low cost and modularity while significantly expanding its capabilities, making sophisticated temporal phenotyping more accessible to the broader plant science community. The system's open-source nature, combined with extensive documentation and containerized deployment options, ensures reproducibility and enables community-driven development of new analytical capabilities.
Kaleidoscope: In-language Exams for Massively Multilingual Vision Evaluation
Apr 09, 2025The evaluation of vision-language models (VLMs) has mainly relied on English-language benchmarks, leaving significant gaps in both multilingual and multicultural coverage. While multilingual benchmarks have expanded, both in size and languages, many rely on translations of English datasets, failing to capture cultural nuances. In this work, we propose Kaleidoscope, as the most comprehensive exam benchmark to date for the multilingual evaluation of vision-language models. Kaleidoscope is a large-scale, in-language multimodal benchmark designed to evaluate VLMs across diverse languages and visual inputs. Kaleidoscope covers 18 languages and 14 different subjects, amounting to a total of 20,911 multiple-choice questions. Built through an open science collaboration with a diverse group of researchers worldwide, Kaleidoscope ensures linguistic and cultural authenticity. We evaluate top-performing multilingual vision-language models and find that they perform poorly on low-resource languages and in complex multimodal scenarios. Our results highlight the need for progress on culturally inclusive multimodal evaluation frameworks.