 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFailing to Explore: Language Models on Interactive Tasks
Jan 29, 2026We evaluate language models on their ability to explore interactive environments under a limited interaction budget. We introduce three parametric tasks with controllable exploration difficulty, spanning continuous and discrete environments. Across state-of-the-art models, we find systematic under-exploration and suboptimal solutions, with performance often significantly worse than simple explore--exploit heuristic baselines and scaling weakly as the budget increases. Finally, we study two lightweight interventions: splitting a fixed budget into parallel executions, which surprisingly improves performance despite a no-gain theoretical result for our tasks, and periodically summarizing the interaction history, which preserves key discoveries and further improves exploration.
Active Learning for Decision Trees with Provable Guarantees
Jan 28, 2026This paper advances the theoretical understanding of active learning label complexity for decision trees as binary classifiers. We make two main contributions. First, we provide the first analysis of the disagreement coefficient for decision trees-a key parameter governing active learning label complexity. Our analysis holds under two natural assumptions required for achieving polylogarithmic label complexity, (i) each root-to-leaf path queries distinct feature dimensions, and (ii) the input data has a regular, grid-like structure. We show these assumptions are essential, as relaxing them leads to polynomial label complexity. Second, we present the first general active learning algorithm for binary classification that achieves a multiplicative error guarantee, producing a $(1+ε)$-approximate classifier. By combining these results, we design an active learning algorithm for decision trees that uses only a polylogarithmic number of label queries in the dataset size, under the stated assumptions. Finally, we establish a label complexity lower bound, showing our algorithm's dependence on the error tolerance $ε$ is close to optimal.
Kaleidoscope: In-language Exams for Massively Multilingual Vision Evaluation
Apr 09, 2025The evaluation of vision-language models (VLMs) has mainly relied on English-language benchmarks, leaving significant gaps in both multilingual and multicultural coverage. While multilingual benchmarks have expanded, both in size and languages, many rely on translations of English datasets, failing to capture cultural nuances. In this work, we propose Kaleidoscope, as the most comprehensive exam benchmark to date for the multilingual evaluation of vision-language models. Kaleidoscope is a large-scale, in-language multimodal benchmark designed to evaluate VLMs across diverse languages and visual inputs. Kaleidoscope covers 18 languages and 14 different subjects, amounting to a total of 20,911 multiple-choice questions. Built through an open science collaboration with a diverse group of researchers worldwide, Kaleidoscope ensures linguistic and cultural authenticity. We evaluate top-performing multilingual vision-language models and find that they perform poorly on low-resource languages and in complex multimodal scenarios. Our results highlight the need for progress on culturally inclusive multimodal evaluation frameworks.
RODEO: Robust Outlier Detection via Exposing Adaptive Out-of-Distribution Samples
Jan 28, 2025In recent years, there have been significant improvements in various forms of image outlier detection. However, outlier detection performance under adversarial settings lags far behind that in standard settings. This is due to the lack of effective exposure to adversarial scenarios during training, especially on unseen outliers, leading to detection models failing to learn robust features. To bridge this gap, we introduce RODEO, a data-centric approach that generates effective outliers for robust outlier detection. More specifically, we show that incorporating outlier exposure (OE) and adversarial training can be an effective strategy for this purpose, as long as the exposed training outliers meet certain characteristics, including diversity, and both conceptual differentiability and analogy to the inlier samples. We leverage a text-to-image model to achieve this goal. We demonstrate both quantitatively and qualitatively that our adaptive OE method effectively generates ``diverse'' and ``near-distribution'' outliers, leveraging information from both text and image domains. Moreover, our experimental results show that utilizing our synthesized outliers significantly enhances the performance of the outlier detector, particularly in adversarial settings.
INCLUDE: Evaluating Multilingual Language Understanding with Regional Knowledge
Nov 29, 2024



The performance differential of large language models (LLM) between languages hinders their effective deployment in many regions, inhibiting the potential economic and societal value of generative AI tools in many communities. However, the development of functional LLMs in many languages (\ie, multilingual LLMs) is bottlenecked by the lack of high-quality evaluation resources in languages other than English. Moreover, current practices in multilingual benchmark construction often translate English resources, ignoring the regional and cultural knowledge of the environments in which multilingual systems would be used. In this work, we construct an evaluation suite of 197,243 QA pairs from local exam sources to measure the capabilities of multilingual LLMs in a variety of regional contexts. Our novel resource, INCLUDE, is a comprehensive knowledge- and reasoning-centric benchmark across 44 written languages that evaluates multilingual LLMs for performance in the actual language environments where they would be deployed.
Seeking Next Layer Neurons' Attention for Error-Backpropagation-Like Training in a Multi-Agent Network Framework
Oct 15, 2023
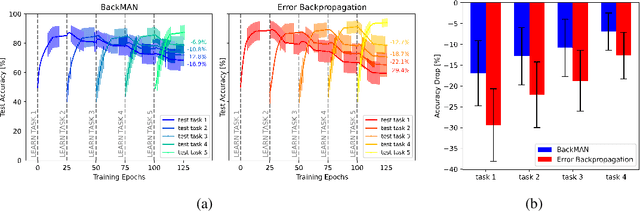

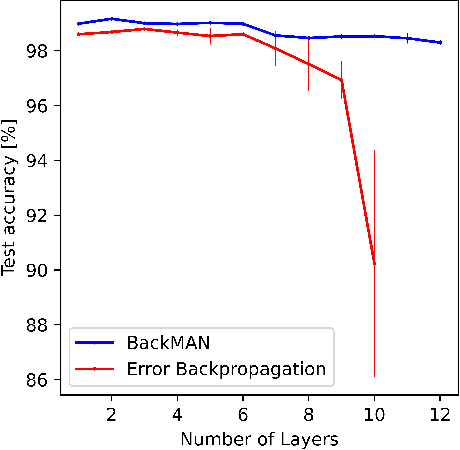
Despite considerable theoretical progress in the training of neural networks viewed as a multi-agent system of neurons, particularly concerning biological plausibility and decentralized training, their applicability to real-world problems remains limited due to scalability issues. In contrast, error-backpropagation has demonstrated its effectiveness for training deep networks in practice. In this study, we propose a local objective for neurons that, when pursued by neurons individually, align them to exhibit similarities to error-backpropagation in terms of efficiency and scalability during training. For this purpose, we examine a neural network comprising decentralized, self-interested neurons seeking to maximize their local objective -- attention from subsequent layer neurons -- and identify the optimal strategy for neurons. We also analyze the relationship between this strategy and backpropagation, establishing conditions under which the derived strategy is equivalent to error-backpropagation. Lastly, we demonstrate the learning capacity of these multi-agent neural networks through experiments on three datasets and showcase their superior performance relative to error-backpropagation in a catastrophic forgetting benchmark.
SPADE: Sparsity-Guided Debugging for Deep Neural Networks
Oct 06, 2023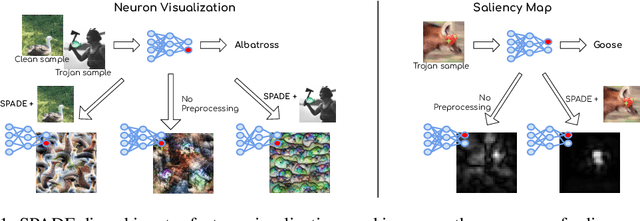
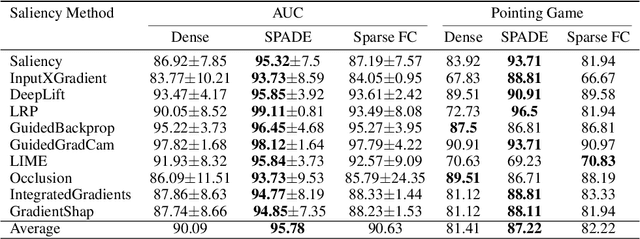

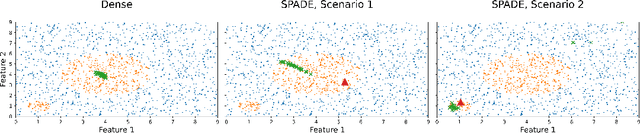
Interpretability, broadly defined as mechanisms for understanding why and how machine learning models reach their decisions, is one of the key open goals at the intersection of deep learning theory and practice. Towards this goal, multiple tools have been proposed to aid a human examiner in reasoning about a network's behavior in general or on a set of instances. However, the outputs of these tools-such as input saliency maps or neuron visualizations-are frequently difficult for a human to interpret, or even misleading, due, in particular, to the fact that neurons can be multifaceted, i.e., a single neuron can be associated with multiple distinct feature combinations. In this paper, we present a new general approach to address this problem, called SPADE, which, given a trained model and a target sample, uses sample-targeted pruning to provide a "trace" of the network's execution on the sample, reducing the network to the connections that are most relevant to the specific prediction. We demonstrate that preprocessing with SPADE significantly increases both the accuracy of image saliency maps across several interpretability methods and the usefulness of neuron visualizations, aiding humans in reasoning about network behavior. Our findings show that sample-specific pruning of connections can disentangle multifaceted neurons, leading to consistently improved interpretability.
Your Out-of-Distribution Detection Method is Not Robust!
Sep 30, 2022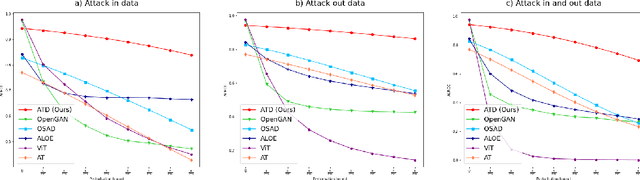
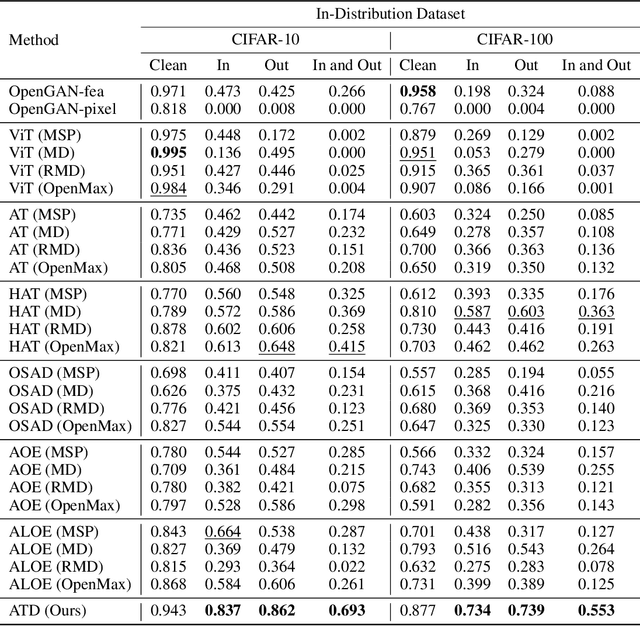
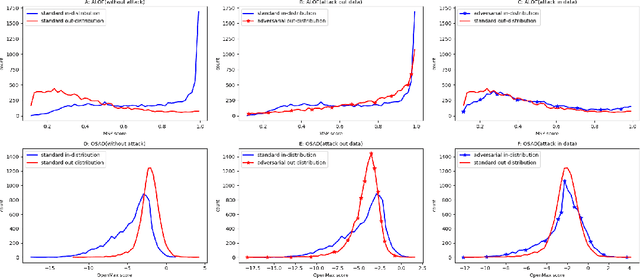

Out-of-distribution (OOD) detection has recently gained substantial attention due to the importance of identifying out-of-domain samples in reliability and safety. Although OOD detection methods have advanced by a great deal, they are still susceptible to adversarial examples, which is a violation of their purpose. To mitigate this issue, several defenses have recently been proposed. Nevertheless, these efforts remained ineffective, as their evaluations are based on either small perturbation sizes, or weak attacks. In this work, we re-examine these defenses against an end-to-end PGD attack on in/out data with larger perturbation sizes, e.g. up to commonly used $\epsilon=8/255$ for the CIFAR-10 dataset. Surprisingly, almost all of these defenses perform worse than a random detection under the adversarial setting. Next, we aim to provide a robust OOD detection method. In an ideal defense, the training should expose the model to almost all possible adversarial perturbations, which can be achieved through adversarial training. That is, such training perturbations should based on both in- and out-of-distribution samples. Therefore, unlike OOD detection in the standard setting, access to OOD, as well as in-distribution, samples sounds necessary in the adversarial training setup. These tips lead us to adopt generative OOD detection methods, such as OpenGAN, as a baseline. We subsequently propose the Adversarially Trained Discriminator (ATD), which utilizes a pre-trained robust model to extract robust features, and a generator model to create OOD samples. Using ATD with CIFAR-10 and CIFAR-100 as the in-distribution data, we could significantly outperform all previous methods in the robust AUROC while maintaining high standard AUROC and classification accuracy. The code repository is available at https://github.com/rohban-lab/ATD .