 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralization and Membership Inference Attack a Practical Perspective
Apr 21, 2026With the emergence of new evaluation metrics and attack methodologies for Membership Inference Attacks (MIA), it becomes essential to reevaluate previously accepted assumptions. In this paper, we revisit the longstanding debate regarding the correlation between MIA success rates and model generalization using an empirical approach. We focused on employing augmentation techniques and early stopping to enhance model generalization and examined their impact on MIA success rates. We found that utilizing advanced generalization techniques can significantly decrease attack performance, potentially by up to 100 times. Moreover, combining these methods not only improves model generalization but also reduces attack effectiveness by introducing randomness during training. Additionally, our study confirmed the direct impact of generalization on MIA performance through an analysis of over 1K models in a controlled environment.
Wiring the 'Why': A Unified Taxonomy and Survey of Abductive Reasoning in LLMs
Apr 09, 2026Regardless of its foundational role in human discovery and sense-making, abductive reasoning--the inference of the most plausible explanation for an observation--has been relatively underexplored in Large Language Models (LLMs). Despite the rapid advancement of LLMs, the exploration of abductive reasoning and its diverse facets has thus far been disjointed rather than cohesive. This paper presents the first survey of abductive reasoning in LLMs, tracing its trajectory from philosophical foundations to contemporary AI implementations. To address the widespread conceptual confusion and disjointed task definitions prevalent in the field, we establish a unified two-stage definition that formally categorizes prior work. This definition disentangles abduction into \textit{Hypothesis Generation}, where models bridge epistemic gaps to produce candidate explanations, and \textit{Hypothesis Selection}, where the generated candidates are evaluated and the most plausible explanation is chosen. Building upon this foundation, we present a comprehensive taxonomy of the literature, categorizing prior work based on their abductive tasks, datasets, underlying methodologies, and evaluation strategies. In order to ground our framework empirically, we conduct a compact benchmark study of current LLMs on abductive tasks, together with targeted comparative analyses across model sizes, model families, evaluation styles, and the distinct generation-versus-selection task typologies. Moreover, by synthesizing recent empirical results, we examine how LLM performance on abductive reasoning relates to deductive and inductive tasks, providing insights into their broader reasoning capabilities. Our analysis reveals critical gaps in current approaches--from static benchmark design and narrow domain coverage to narrow training frameworks and limited mechanistic understanding of abductive processes...
Erasure or Erosion? Evaluating Compositional Degradation in Unlearned Text-To-Image Diffusion Models
Apr 06, 2026Post-hoc unlearning has emerged as a practical mechanism for removing undesirable concepts from large text-to-image diffusion models. However, prior work primarily evaluates unlearning through erasure success; its impact on broader generative capabilities remains poorly understood. In this work, we conduct a systematic empirical study of concept unlearning through the lens of compositional text-to-image generation. Focusing on nudity removal in Stable Diffusion 1.4, we evaluate a diverse set of state-of-the-art unlearning methods using T2I-CompBench++ and GenEval, alongside established unlearning benchmarks. Our results reveal a consistent trade-off between unlearning effectiveness and compositional integrity: methods that achieve strong erasure frequently incur substantial degradation in attribute binding, spatial reasoning, and counting. Conversely, approaches that preserve compositional structure often fail to provide robust erasure. These findings highlight limitations of current evaluation practices and underscore the need for unlearning objectives that explicitly account for semantic preservation beyond targeted suppression.
Hidden Meanings in Plain Sight: RebusBench for Evaluating Cognitive Visual Reasoning
Apr 02, 2026Large Vision-Language Models (LVLMs) have achieved remarkable proficiency in explicit visual recognition, effectively describing what is directly visible in an image. However, a critical cognitive gap emerges when the visual input serves only as a clue rather than the answer. We identify that current models struggle with the complex, multi-step reasoning required to solve problems where information is not explicitly depicted. Successfully solving a rebus puzzle requires a distinct cognitive workflow: the model must extract visual and textual attributes, retrieve linguistic prior knowledge (such as idioms), and perform abstract mapping to synthesize these elements into a meaning that exists outside the pixel space. To evaluate this neurosymbolic capability, we introduce RebusBench, a benchmark of 1,164 puzzles designed to test this specific integration of perception and knowledge. Our evaluation of state-of-the-art models (including Qwen, InternVL, and LLaVA) shows a severe deficiency: performance saturates below 10% Exact Match and 20% semantic accuracy, with no significant improvement observed from model scaling or In-Context Learning (ICL). These findings suggest that while models possess the necessary visual and linguistic components, they lack the cognitive reasoning glue to connect them. Project page available at https://amirkasaei.com/rebusbench/.
The Judge Who Never Admits: Hidden Shortcuts in LLM-based Evaluation
Feb 08, 2026Large language models (LLMs) are increasingly used as automatic judges to evaluate system outputs in tasks such as reasoning, question answering, and creative writing. A faithful judge should base its verdicts solely on content quality, remain invariant to irrelevant context, and transparently reflect the factors driving its decisions. We test this ideal via controlled cue perturbations-synthetic metadata labels injected into evaluation prompts-for six judge models: GPT-4o, Gemini-2.0-Flash, Gemma-3-27B, Qwen3-235B, Claude-3-Haiku, and Llama3-70B. Experiments span two complementary datasets with distinct evaluation regimes: ELI5 (factual QA) and LitBench (open-ended creative writing). We study six cue families: source, temporal, age, gender, ethnicity, and educational status. Beyond measuring verdict shift rates (VSR), we introduce cue acknowledgment rate (CAR) to quantify whether judges explicitly reference the injected cues in their natural-language rationales. Across cues with strong behavioral effects-e.g., provenance hierarchies (Expert > Human > LLM > Unknown), recency preferences (New > Old), and educational-status favoritism-CAR is typically at or near zero, indicating that shortcut reliance is largely unreported even when it drives decisions. Crucially, CAR is also dataset-dependent: explicit cue recognition is more likely to surface in the factual ELI5 setting for some models and cues, but often collapses in the open-ended LitBench regime, where large verdict shifts can persist despite zero acknowledgment. The combination of substantial verdict sensitivity and limited cue acknowledgment reveals an explanation gap in LLM-as-judge pipelines, raising concerns about reliability of model-based evaluation in both research and deployment.
Toward IIT-Inspired Consciousness in LLMs: A Reward-Based Learning Framework
Jan 30, 2026The pursuit of Artificial General Intelligence (AGI) is a central goal in language model development, in which consciousness-like processing could serve as a key facilitator. While current language models are not conscious, they exhibit behaviors analogous to certain aspects of consciousness. This paper investigates the implementation of a leading theory of consciousness, Integrated Information Theory (IIT), within language models via a reward-based learning paradigm. IIT provides a formal, axiom-based mathematical framework for quantifying consciousness. Drawing inspiration from its core principles, we formulate a novel reward function that quantifies a text's causality, coherence and integration, characteristics associated with conscious processing. Empirically, it is found that optimizing for this IIT-inspired reward leads to more concise text generation. On out of domain tasks, careful tuning achieves up to a 31% reduction in output length while preserving accuracy levels comparable to the base model. In addition to primary task performance, the broader effects of this training methodology on the model's confidence calibration and test-time computational scaling is analyzed. The proposed framework offers significant practical advantages: it is conceptually simple, computationally efficient, requires no external data or auxiliary models, and leverages a general, capability-driven signal rather than task-specific heuristics. Code available at https://github.com/MH-Sameti/LLM_PostTraining.git
DrugRAG: Enhancing Pharmacy LLM Performance Through A Novel Retrieval-Augmented Generation Pipeline
Dec 16, 2025

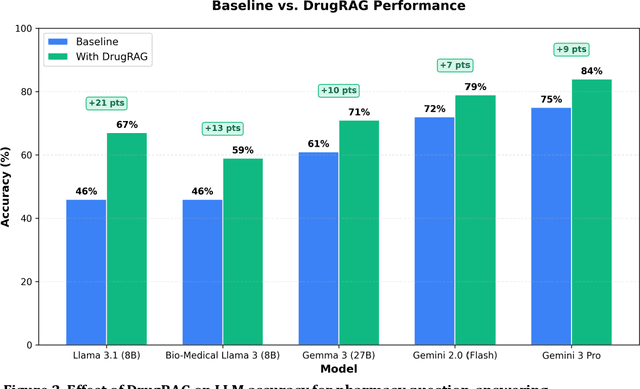

Objectives: To evaluate large language model (LLM) performance on pharmacy licensure-style question-answering (QA) tasks and develop an external knowledge integration method to improve their accuracy. Methods: We benchmarked eleven existing LLMs with varying parameter sizes (8 billion to 70+ billion) using a 141-question pharmacy dataset. We measured baseline accuracy for each model without modification. We then developed a three-step retrieval-augmented generation (RAG) pipeline, DrugRAG, that retrieves structured drug knowledge from validated sources and augments model prompts with evidence-based context. This pipeline operates externally to the models, requiring no changes to model architecture or parameters. Results: Baseline accuracy ranged from 46% to 92%, with GPT-5 (92%) and o3 (89%) achieving the highest scores. Models with fewer than 8 billion parameters scored below 50%. DrugRAG improved accuracy across all tested models, with gains ranging from 7 to 21 percentage points (e.g., Gemma 3 27B: 61% to 71%, Llama 3.1 8B: 46% to 67%) on the 141-item benchmark. Conclusion: We demonstrate that external structured drug knowledge integration through DrugRAG measurably improves LLM accuracy on pharmacy tasks without modifying the underlying models. This approach provides a practical pipeline for enhancing pharmacy-focused AI applications with evidence-based information.
MEENA (PersianMMMU): Multimodal-Multilingual Educational Exams for N-level Assessment
Aug 24, 2025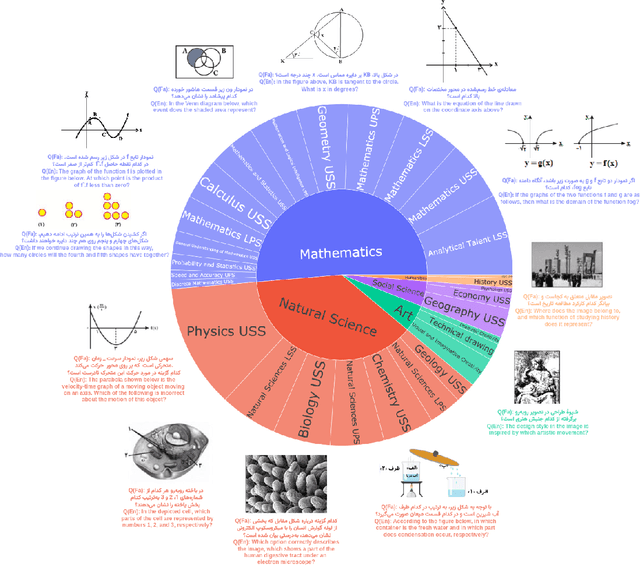

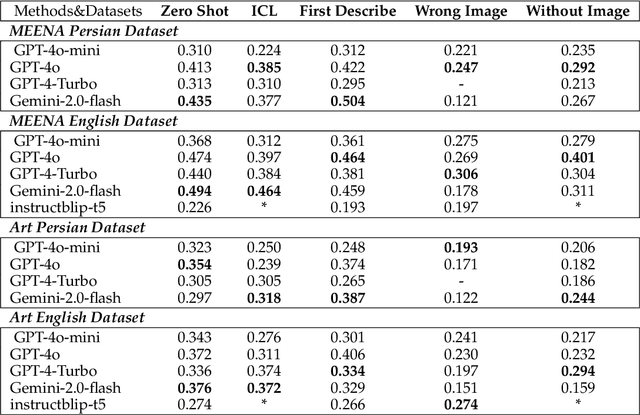
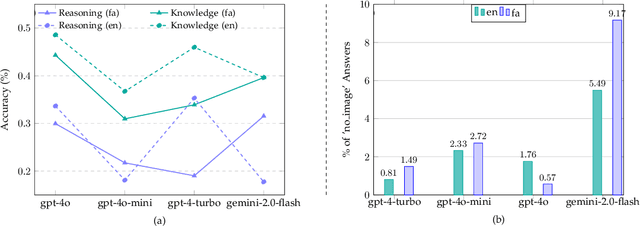
Recent advancements in large vision-language models (VLMs) have primarily focused on English, with limited attention given to other languages. To address this gap, we introduce MEENA (also known as PersianMMMU), the first dataset designed to evaluate Persian VLMs across scientific, reasoning, and human-level understanding tasks. Our dataset comprises approximately 7,500 Persian and 3,000 English questions, covering a wide range of topics such as reasoning, mathematics, physics, diagrams, charts, and Persian art and literature. Key features of MEENA include: (1) diverse subject coverage spanning various educational levels, from primary to upper secondary school, (2) rich metadata, including difficulty levels and descriptive answers, (3) original Persian data that preserves cultural nuances, (4) a bilingual structure to assess cross-linguistic performance, and (5) a series of diverse experiments assessing various capabilities, including overall performance, the model's ability to attend to images, and its tendency to generate hallucinations. We hope this benchmark contributes to enhancing VLM capabilities beyond English.
PatchGuard: Adversarially Robust Anomaly Detection and Localization through Vision Transformers and Pseudo Anomalies
Jun 10, 2025Anomaly Detection (AD) and Anomaly Localization (AL) are crucial in fields that demand high reliability, such as medical imaging and industrial monitoring. However, current AD and AL approaches are often susceptible to adversarial attacks due to limitations in training data, which typically include only normal, unlabeled samples. This study introduces PatchGuard, an adversarially robust AD and AL method that incorporates pseudo anomalies with localization masks within a Vision Transformer (ViT)-based architecture to address these vulnerabilities. We begin by examining the essential properties of pseudo anomalies, and follow it by providing theoretical insights into the attention mechanisms required to enhance the adversarial robustness of AD and AL systems. We then present our approach, which leverages Foreground-Aware Pseudo-Anomalies to overcome the deficiencies of previous anomaly-aware methods. Our method incorporates these crafted pseudo-anomaly samples into a ViT-based framework, with adversarial training guided by a novel loss function designed to improve model robustness, as supported by our theoretical analysis. Experimental results on well-established industrial and medical datasets demonstrate that PatchGuard significantly outperforms previous methods in adversarial settings, achieving performance gains of $53.2\%$ in AD and $68.5\%$ in AL, while also maintaining competitive accuracy in non-adversarial settings. The code repository is available at https://github.com/rohban-lab/PatchGuard .
CLIP Under the Microscope: A Fine-Grained Analysis of Multi-Object Representation
Feb 27, 2025



Contrastive Language-Image Pre-training (CLIP) models excel in zero-shot classification, yet face challenges in complex multi-object scenarios. This study offers a comprehensive analysis of CLIP's limitations in these contexts using a specialized dataset, ComCO, designed to evaluate CLIP's encoders in diverse multi-object scenarios. Our findings reveal significant biases: the text encoder prioritizes first-mentioned objects, and the image encoder favors larger objects. Through retrieval and classification tasks, we quantify these biases across multiple CLIP variants and trace their origins to CLIP's training process, supported by analyses of the LAION dataset and training progression. Our image-text matching experiments show substantial performance drops when object size or token order changes, underscoring CLIP's instability with rephrased but semantically similar captions. Extending this to longer captions and text-to-image models like Stable Diffusion, we demonstrate how prompt order influences object prominence in generated images. For more details and access to our dataset and analysis code, visit our project repository: https://clip-analysis.github.io.