 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing CLIP's Performance Limitations in Multi-Object Scenarios: A Controlled High-Resolution Study
Feb 27, 2025



Contrastive Language-Image Pre-training (CLIP) models have demonstrated remarkable performance in zero-shot classification tasks, yet their efficacy in handling complex multi-object scenarios remains challenging. This study presents a comprehensive analysis of CLIP's performance limitations in multi-object contexts through controlled experiments. We introduce two custom datasets, SimCO and CompCO, to evaluate CLIP's image and text encoders in various multi-object configurations. Our findings reveal significant biases in both encoders: the image encoder favors larger objects, while the text encoder prioritizes objects mentioned first in descriptions. We hypothesize these biases originate from CLIP's training process and provide evidence through analyses of the COCO dataset and CLIP's training progression. Additionally, we extend our investigation to Stable Diffusion models, revealing that biases in the CLIP text encoder significantly impact text-to-image generation tasks. Our experiments demonstrate how these biases affect CLIP's performance in image-caption matching and generation tasks, particularly when manipulating object sizes and their order in captions. This work contributes valuable insights into CLIP's behavior in complex visual environments and highlights areas for improvement in future vision-language models.
CLIP Under the Microscope: A Fine-Grained Analysis of Multi-Object Representation
Feb 27, 2025



Contrastive Language-Image Pre-training (CLIP) models excel in zero-shot classification, yet face challenges in complex multi-object scenarios. This study offers a comprehensive analysis of CLIP's limitations in these contexts using a specialized dataset, ComCO, designed to evaluate CLIP's encoders in diverse multi-object scenarios. Our findings reveal significant biases: the text encoder prioritizes first-mentioned objects, and the image encoder favors larger objects. Through retrieval and classification tasks, we quantify these biases across multiple CLIP variants and trace their origins to CLIP's training process, supported by analyses of the LAION dataset and training progression. Our image-text matching experiments show substantial performance drops when object size or token order changes, underscoring CLIP's instability with rephrased but semantically similar captions. Extending this to longer captions and text-to-image models like Stable Diffusion, we demonstrate how prompt order influences object prominence in generated images. For more details and access to our dataset and analysis code, visit our project repository: https://clip-analysis.github.io.
Attention Overlap Is Responsible for The Entity Missing Problem in Text-to-image Diffusion Models!
Oct 28, 2024



Text-to-image diffusion models, such as Stable Diffusion and DALL-E, are capable of generating high-quality, diverse, and realistic images from textual prompts. However, they sometimes struggle to accurately depict specific entities described in prompts, a limitation known as the entity missing problem in compositional generation. While prior studies suggested that adjusting cross-attention maps during the denoising process could alleviate this problem, they did not systematically investigate which objective functions could best address it. This study examines three potential causes of the entity-missing problem, focusing on cross-attention dynamics: (1) insufficient attention intensity for certain entities, (2) overly broad attention spread, and (3) excessive overlap between attention maps of different entities. We found that reducing overlap in attention maps between entities can effectively minimize the rate of entity missing. Specifically, we hypothesize that tokens related to specific entities compete for attention on certain image regions during the denoising process, which can lead to divided attention across tokens and prevent accurate representation of each entity. To address this issue, we introduced four loss functions, Intersection over Union (IoU), center-of-mass (CoM) distance, Kullback-Leibler (KL) divergence, and clustering compactness (CC) to regulate attention overlap during denoising steps without the need for retraining. Experimental results across a wide variety of benchmarks reveal that these proposed training-free methods significantly improve compositional accuracy, outperforming previous approaches in visual question answering (VQA), captioning scores, CLIP similarity, and human evaluations. Notably, these methods improved human evaluation scores by 9% over the best baseline, demonstrating substantial improvements in compositional alignment.
Superpipeline: A Universal Approach for Reducing GPU Memory Usage in Large Models
Oct 11, 2024



The rapid growth in machine learning models, especially in natural language processing and computer vision, has led to challenges when running these models on hardware with limited resources. This paper introduces Superpipeline, a new framework designed to optimize the execution of large AI models on constrained hardware during both training and inference. Our approach involves dynamically managing model execution by dividing models into individual layers and efficiently transferring these layers between GPU and CPU memory. Superpipeline reduces GPU memory usage by up to 60% in our experiments while maintaining model accuracy and acceptable processing speeds. This allows models that would otherwise exceed available GPU memory to run effectively. Unlike existing solutions that focus mainly on inference or specific model types, Superpipeline can be applied to large language models (LLMs), vision-language models (VLMs), and vision-based models. We tested Superpipeline's performance across various models and hardware setups. The method includes two key parameters that allow fine-tuning the balance between GPU memory use and processing speed. Importantly, Superpipeline does not require retraining or changing model parameters, ensuring that the original model's output remains unchanged. Superpipeline's simplicity and flexibility make it useful for researchers and professionals working with advanced AI models on limited hardware. It enables the use of larger models or bigger batch sizes on existing hardware, potentially speeding up innovation across many machine learning applications. This work marks an important step toward making advanced AI models more accessible and optimizing their deployment in resource-limited environments. The code for Superpipeline is available at https://github.com/abbasiReza/super-pipeline.
GABInsight: Exploring Gender-Activity Binding Bias in Vision-Language Models
Jul 30, 2024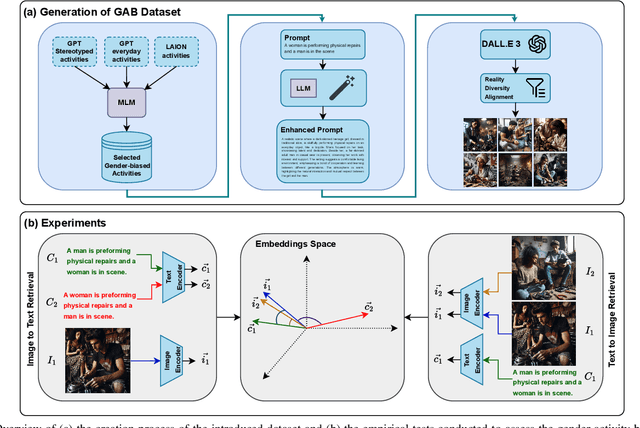
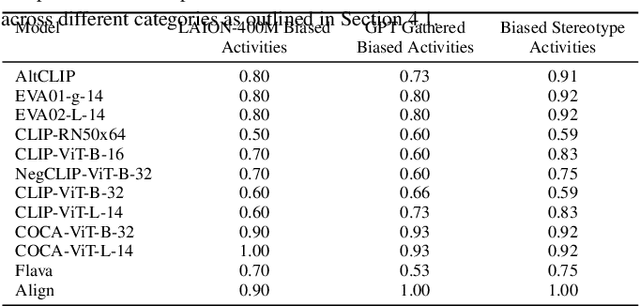
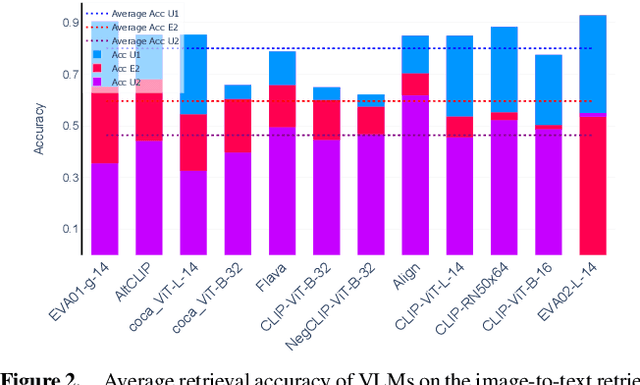
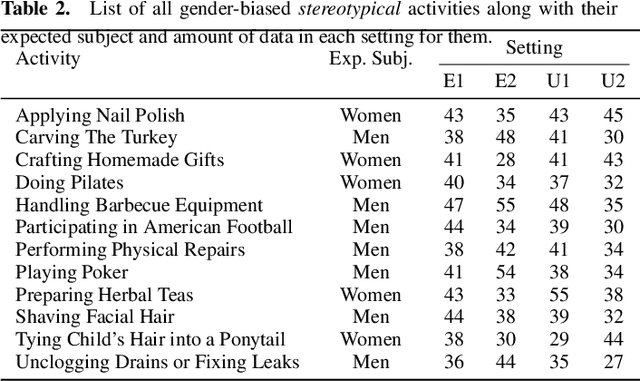
Vision-language models (VLMs) are intensively used in many downstream tasks, including those requiring assessments of individuals appearing in the images. While VLMs perform well in simple single-person scenarios, in real-world applications, we often face complex situations in which there are persons of different genders doing different activities. We show that in such cases, VLMs are biased towards identifying the individual with the expected gender (according to ingrained gender stereotypes in the model or other forms of sample selection bias) as the performer of the activity. We refer to this bias in associating an activity with the gender of its actual performer in an image or text as the Gender-Activity Binding (GAB) bias and analyze how this bias is internalized in VLMs. To assess this bias, we have introduced the GAB dataset with approximately 5500 AI-generated images that represent a variety of activities, addressing the scarcity of real-world images for some scenarios. To have extensive quality control, the generated images are evaluated for their diversity, quality, and realism. We have tested 12 renowned pre-trained VLMs on this dataset in the context of text-to-image and image-to-text retrieval to measure the effect of this bias on their predictions. Additionally, we have carried out supplementary experiments to quantify the bias in VLMs' text encoders and to evaluate VLMs' capability to recognize activities. Our experiments indicate that VLMs experience an average performance decline of about 13.2% when confronted with gender-activity binding bias.
Deciphering the Role of Representation Disentanglement: Investigating Compositional Generalization in CLIP Models
Jul 08, 2024



CLIP models have recently shown to exhibit Out of Distribution (OoD) generalization capabilities. However, Compositional Out of Distribution (C-OoD) generalization, which is a crucial aspect of a model's ability to understand unseen compositions of known concepts, is relatively unexplored for the CLIP models. Our goal is to address this problem and identify the factors that contribute to the C-OoD in CLIPs. We noted that previous studies regarding compositional understanding of CLIPs frequently fail to ensure that test samples are genuinely novel relative to the CLIP training data. To this end, we carefully synthesized a large and diverse dataset in the single object setting, comprising attributes for objects that are highly unlikely to be encountered in the combined training datasets of various CLIP models. This dataset enables an authentic evaluation of C-OoD generalization. Our observations reveal varying levels of C-OoD generalization across different CLIP models. We propose that the disentanglement of CLIP representations serves as a critical indicator in this context. By utilizing our synthesized datasets and other existing datasets, we assess various disentanglement metrics of text and image representations. Our study reveals that the disentanglement of image and text representations, particularly with respect to their compositional elements, plays a crucial role in improving the generalization of CLIP models in out-of-distribution settings. This finding suggests promising opportunities for advancing out-of-distribution generalization in CLIPs.
Language Plays a Pivotal Role in the Object-Attribute Compositional Generalization of CLIP
Mar 27, 2024Vision-language models, such as CLIP, have shown promising Out-of-Distribution (OoD) generalization under various types of distribution shifts. Recent studies attempted to investigate the leading cause of this capability. In this work, we follow the same path, but focus on a specific type of OoD data - images with novel compositions of attribute-object pairs - and study whether such models can successfully classify those images into composition classes. We carefully designed an authentic image test dataset called ImageNet-AO, consisting of attributes for objects that are unlikely encountered in the CLIP training sets. We found that CLIPs trained with large datasets such as OpenAI CLIP, LAION-400M, and LAION-2B show orders-of-magnitude improvement in effective compositional OoD generalization compared to both supervised models and CLIPs trained with smaller datasets, such as CC-12M and YFCC-15M. Our results provide evidence that the scale and diversity of training data and language supervision play a key role in unlocking the compositional generalization abilities of vision-language models.
Spuriosity Rankings for Free: A Simple Framework for Last Layer Retraining Based on Object Detection
Oct 31, 2023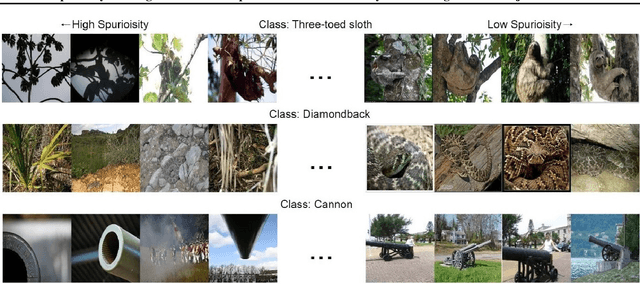

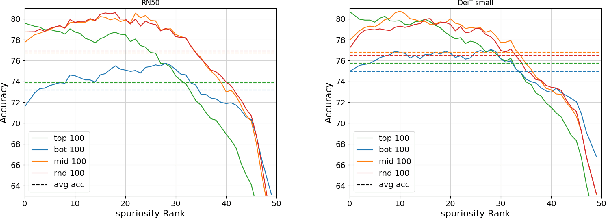
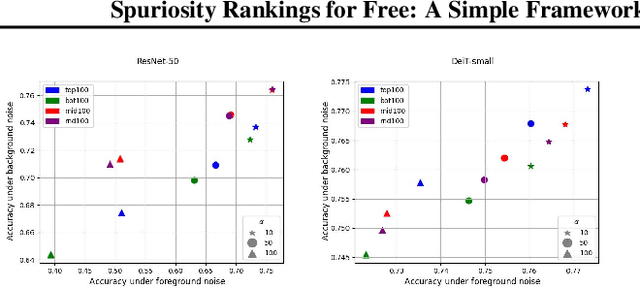
Deep neural networks have exhibited remarkable performance in various domains. However, the reliance of these models on spurious features has raised concerns about their reliability. A promising solution to this problem is last-layer retraining, which involves retraining the linear classifier head on a small subset of data without spurious cues. Nevertheless, selecting this subset requires human supervision, which reduces its scalability. Moreover, spurious cues may still exist in the selected subset. As a solution to this problem, we propose a novel ranking framework that leverages an open vocabulary object detection technique to identify images without spurious cues. More specifically, we use the object detector as a measure to score the presence of the target object in the images. Next, the images are sorted based on this score, and the last-layer of the model is retrained on a subset of the data with the highest scores. Our experiments on the ImageNet-1k dataset demonstrate the effectiveness of this ranking framework in sorting images based on spuriousness and using them for last-layer retraining.