 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrained Models Tell Us How to Make Them Robust to Spurious Correlation without Group Annotation
Oct 07, 2024Classifiers trained with Empirical Risk Minimization (ERM) tend to rely on attributes that have high spurious correlation with the target. This can degrade the performance on underrepresented (or 'minority') groups that lack these attributes, posing significant challenges for both out-of-distribution generalization and fairness objectives. Many studies aim to enhance robustness to spurious correlation, but they sometimes depend on group annotations for training. Additionally, a common limitation in previous research is the reliance on group-annotated validation datasets for model selection. This constrains their applicability in situations where the nature of the spurious correlation is not known, or when group labels for certain spurious attributes are not available. To enhance model robustness with minimal group annotation assumptions, we propose Environment-based Validation and Loss-based Sampling (EVaLS). It uses the losses from an ERM-trained model to construct a balanced dataset of high-loss and low-loss samples, mitigating group imbalance in data. This significantly enhances robustness to group shifts when equipped with a simple post-training last layer retraining. By using environment inference methods to create diverse environments with correlation shifts, EVaLS can potentially eliminate the need for group annotation in validation data. In this context, the worst environment accuracy acts as a reliable surrogate throughout the retraining process for tuning hyperparameters and finding a model that performs well across diverse group shifts. EVaLS effectively achieves group robustness, showing that group annotation is not necessary even for validation. It is a fast, straightforward, and effective approach that reaches near-optimal worst group accuracy without needing group annotations, marking a new chapter in the robustness of trained models against spurious correlation.
GABInsight: Exploring Gender-Activity Binding Bias in Vision-Language Models
Jul 30, 2024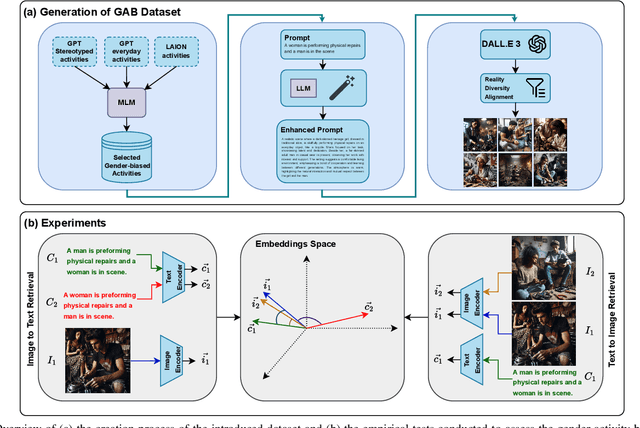
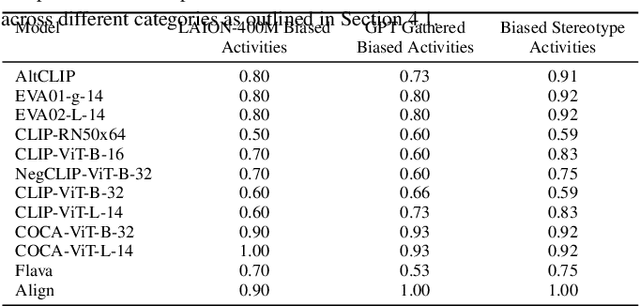
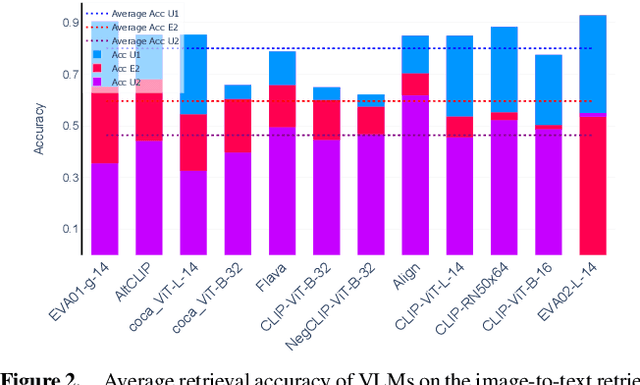
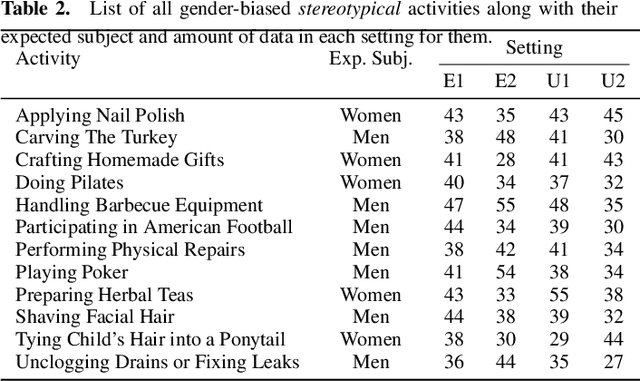
Vision-language models (VLMs) are intensively used in many downstream tasks, including those requiring assessments of individuals appearing in the images. While VLMs perform well in simple single-person scenarios, in real-world applications, we often face complex situations in which there are persons of different genders doing different activities. We show that in such cases, VLMs are biased towards identifying the individual with the expected gender (according to ingrained gender stereotypes in the model or other forms of sample selection bias) as the performer of the activity. We refer to this bias in associating an activity with the gender of its actual performer in an image or text as the Gender-Activity Binding (GAB) bias and analyze how this bias is internalized in VLMs. To assess this bias, we have introduced the GAB dataset with approximately 5500 AI-generated images that represent a variety of activities, addressing the scarcity of real-world images for some scenarios. To have extensive quality control, the generated images are evaluated for their diversity, quality, and realism. We have tested 12 renowned pre-trained VLMs on this dataset in the context of text-to-image and image-to-text retrieval to measure the effect of this bias on their predictions. Additionally, we have carried out supplementary experiments to quantify the bias in VLMs' text encoders and to evaluate VLMs' capability to recognize activities. Our experiments indicate that VLMs experience an average performance decline of about 13.2% when confronted with gender-activity binding bias.
Annotation-Free Group Robustness via Loss-Based Resampling
Dec 08, 2023It is well-known that training neural networks for image classification with empirical risk minimization (ERM) makes them vulnerable to relying on spurious attributes instead of causal ones for prediction. Previously, deep feature re-weighting (DFR) has proposed retraining the last layer of a pre-trained network on balanced data concerning spurious attributes, making it robust to spurious correlation. However, spurious attribute annotations are not always available. In order to provide group robustness without such annotations, we propose a new method, called loss-based feature re-weighting (LFR), in which we infer a grouping of the data by evaluating an ERM-pre-trained model on a small left-out split of the training data. Then, a balanced number of samples is chosen by selecting high-loss samples from misclassified data points and low-loss samples from correctly-classified ones. Finally, we retrain the last layer on the selected balanced groups to make the model robust to spurious correlation. For a complete assessment, we evaluate LFR on various versions of Waterbirds and CelebA datasets with different spurious correlations, which is a novel technique for observing the model's performance in a wide range of spuriosity rates. While LFR is extremely fast and straightforward, it outperforms the previous methods that do not assume group label availability, as well as the DFR with group annotations provided, in cases of high spurious correlation in the training data.