 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMechanistic Interpretability of Large-Scale Counting in LLMs through a System-2 Strategy
Jan 06, 2026Large language models (LLMs), despite strong performance on complex mathematical problems, exhibit systematic limitations in counting tasks. This issue arises from architectural limits of transformers, where counting is performed across layers, leading to degraded precision for larger counting problems due to depth constraints. To address this limitation, we propose a simple test-time strategy inspired by System-2 cognitive processes that decomposes large counting tasks into smaller, independent sub-problems that the model can reliably solve. We evaluate this approach using observational and causal mediation analyses to understand the underlying mechanism of this System-2-like strategy. Our mechanistic analysis identifies key components: latent counts are computed and stored in the final item representations of each part, transferred to intermediate steps via dedicated attention heads, and aggregated in the final stage to produce the total count. Experimental results demonstrate that this strategy enables LLMs to surpass architectural limitations and achieve high accuracy on large-scale counting tasks. This work provides mechanistic insight into System-2 counting in LLMs and presents a generalizable approach for improving and understanding their reasoning behavior.
Improving 3D Few-Shot Segmentation with Inference-Time Pseudo-Labeling
Oct 13, 2024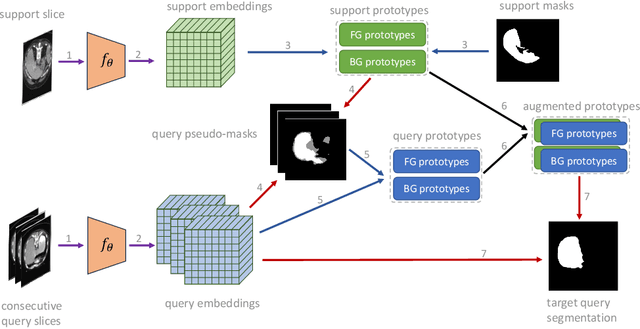

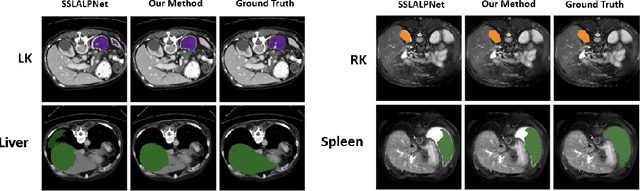

In recent years, few-shot segmentation (FSS) models have emerged as a promising approach in medical imaging analysis, offering remarkable adaptability to segment novel classes with limited annotated data. Existing approaches to few-shot segmentation have often overlooked the potential of the query itself, failing to fully utilize the valuable information it contains. However, treating the query as unlabeled data provides an opportunity to enhance prediction accuracy. Specifically in the domain of medical imaging, the volumetric structure of queries offers a considerable source of valuable information that can be used to improve the target slice segmentation. In this work, we present a novel strategy to efficiently leverage the intrinsic information of the query sample for final segmentation during inference. First, we use the support slices from a reference volume to generate an initial segmentation score for the query slices through a prototypical approach. Subsequently, we apply a confidence-aware pseudo-labeling procedure to transfer the most informative parts of query slices to the support set. The final prediction is performed based on the new expanded support set, enabling the prediction of a more accurate segmentation mask for the query volume. Extensive experiments show that the proposed method can effectively boost performance across diverse settings and datasets.
Trained Models Tell Us How to Make Them Robust to Spurious Correlation without Group Annotation
Oct 07, 2024Classifiers trained with Empirical Risk Minimization (ERM) tend to rely on attributes that have high spurious correlation with the target. This can degrade the performance on underrepresented (or 'minority') groups that lack these attributes, posing significant challenges for both out-of-distribution generalization and fairness objectives. Many studies aim to enhance robustness to spurious correlation, but they sometimes depend on group annotations for training. Additionally, a common limitation in previous research is the reliance on group-annotated validation datasets for model selection. This constrains their applicability in situations where the nature of the spurious correlation is not known, or when group labels for certain spurious attributes are not available. To enhance model robustness with minimal group annotation assumptions, we propose Environment-based Validation and Loss-based Sampling (EVaLS). It uses the losses from an ERM-trained model to construct a balanced dataset of high-loss and low-loss samples, mitigating group imbalance in data. This significantly enhances robustness to group shifts when equipped with a simple post-training last layer retraining. By using environment inference methods to create diverse environments with correlation shifts, EVaLS can potentially eliminate the need for group annotation in validation data. In this context, the worst environment accuracy acts as a reliable surrogate throughout the retraining process for tuning hyperparameters and finding a model that performs well across diverse group shifts. EVaLS effectively achieves group robustness, showing that group annotation is not necessary even for validation. It is a fast, straightforward, and effective approach that reaches near-optimal worst group accuracy without needing group annotations, marking a new chapter in the robustness of trained models against spurious correlation.
Speech-Driven Facial Reenactment Using Conditional Generative Adversarial Networks
Mar 20, 2018



We present a novel approach to generating photo-realistic images of a face with accurate lip sync, given an audio input. By using a recurrent neural network, we achieved mouth landmarks based on audio features. We exploited the power of conditional generative adversarial networks to produce highly-realistic face conditioned on a set of landmarks. These two networks together are capable of producing a sequence of natural faces in sync with an input audio track.