 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving 3D Few-Shot Segmentation with Inference-Time Pseudo-Labeling
Oct 13, 2024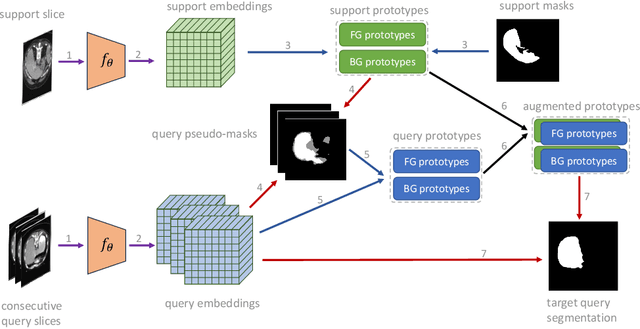

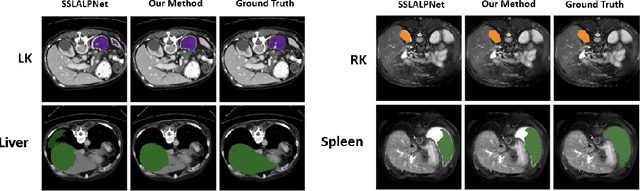

In recent years, few-shot segmentation (FSS) models have emerged as a promising approach in medical imaging analysis, offering remarkable adaptability to segment novel classes with limited annotated data. Existing approaches to few-shot segmentation have often overlooked the potential of the query itself, failing to fully utilize the valuable information it contains. However, treating the query as unlabeled data provides an opportunity to enhance prediction accuracy. Specifically in the domain of medical imaging, the volumetric structure of queries offers a considerable source of valuable information that can be used to improve the target slice segmentation. In this work, we present a novel strategy to efficiently leverage the intrinsic information of the query sample for final segmentation during inference. First, we use the support slices from a reference volume to generate an initial segmentation score for the query slices through a prototypical approach. Subsequently, we apply a confidence-aware pseudo-labeling procedure to transfer the most informative parts of query slices to the support set. The final prediction is performed based on the new expanded support set, enabling the prediction of a more accurate segmentation mask for the query volume. Extensive experiments show that the proposed method can effectively boost performance across diverse settings and datasets.
ComAlign: Compositional Alignment in Vision-Language Models
Sep 12, 2024Vision-language models (VLMs) like CLIP have showcased a remarkable ability to extract transferable features for downstream tasks. Nonetheless, the training process of these models is usually based on a coarse-grained contrastive loss between the global embedding of images and texts which may lose the compositional structure of these modalities. Many recent studies have shown VLMs lack compositional understandings like attribute binding and identifying object relationships. Although some recent methods have tried to achieve finer-level alignments, they either are not based on extracting meaningful components of proper granularity or don't properly utilize the modalities' correspondence (especially in image-text pairs with more ingredients). Addressing these limitations, we introduce Compositional Alignment (ComAlign), a fine-grained approach to discover more exact correspondence of text and image components using only the weak supervision in the form of image-text pairs. Our methodology emphasizes that the compositional structure (including entities and relations) extracted from the text modality must also be retained in the image modality. To enforce correspondence of fine-grained concepts in image and text modalities, we train a lightweight network lying on top of existing visual and language encoders using a small dataset. The network is trained to align nodes and edges of the structure across the modalities. Experimental results on various VLMs and datasets demonstrate significant improvements in retrieval and compositional benchmarks, affirming the effectiveness of our plugin model.