 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Judge Who Never Admits: Hidden Shortcuts in LLM-based Evaluation
Feb 08, 2026Large language models (LLMs) are increasingly used as automatic judges to evaluate system outputs in tasks such as reasoning, question answering, and creative writing. A faithful judge should base its verdicts solely on content quality, remain invariant to irrelevant context, and transparently reflect the factors driving its decisions. We test this ideal via controlled cue perturbations-synthetic metadata labels injected into evaluation prompts-for six judge models: GPT-4o, Gemini-2.0-Flash, Gemma-3-27B, Qwen3-235B, Claude-3-Haiku, and Llama3-70B. Experiments span two complementary datasets with distinct evaluation regimes: ELI5 (factual QA) and LitBench (open-ended creative writing). We study six cue families: source, temporal, age, gender, ethnicity, and educational status. Beyond measuring verdict shift rates (VSR), we introduce cue acknowledgment rate (CAR) to quantify whether judges explicitly reference the injected cues in their natural-language rationales. Across cues with strong behavioral effects-e.g., provenance hierarchies (Expert > Human > LLM > Unknown), recency preferences (New > Old), and educational-status favoritism-CAR is typically at or near zero, indicating that shortcut reliance is largely unreported even when it drives decisions. Crucially, CAR is also dataset-dependent: explicit cue recognition is more likely to surface in the factual ELI5 setting for some models and cues, but often collapses in the open-ended LitBench regime, where large verdict shifts can persist despite zero acknowledgment. The combination of substantial verdict sensitivity and limited cue acknowledgment reveals an explanation gap in LLM-as-judge pipelines, raising concerns about reliability of model-based evaluation in both research and deployment.
Efficient Adversarial Attacks on High-dimensional Offline Bandits
Feb 02, 2026Bandit algorithms have recently emerged as a powerful tool for evaluating machine learning models, including generative image models and large language models, by efficiently identifying top-performing candidates without exhaustive comparisons. These methods typically rely on a reward model, often distributed with public weights on platforms such as Hugging Face, to provide feedback to the bandit. While online evaluation is expensive and requires repeated trials, offline evaluation with logged data has become an attractive alternative. However, the adversarial robustness of offline bandit evaluation remains largely unexplored, particularly when an attacker perturbs the reward model (rather than the training data) prior to bandit training. In this work, we fill this gap by investigating, both theoretically and empirically, the vulnerability of offline bandit training to adversarial manipulations of the reward model. We introduce a novel threat model in which an attacker exploits offline data in high-dimensional settings to hijack the bandit's behavior. Starting with linear reward functions and extending to nonlinear models such as ReLU neural networks, we study attacks on two Hugging Face evaluators used for generative model assessment: one measuring aesthetic quality and the other assessing compositional alignment. Our results show that even small, imperceptible perturbations to the reward model's weights can drastically alter the bandit's behavior. From a theoretical perspective, we prove a striking high-dimensional effect: as input dimensionality increases, the perturbation norm required for a successful attack decreases, making modern applications such as image evaluation especially vulnerable. Extensive experiments confirm that naive random perturbations are ineffective, whereas carefully targeted perturbations achieve near-perfect attack success rates ...
SUSD: Structured Unsupervised Skill Discovery through State Factorization
Feb 02, 2026Unsupervised Skill Discovery (USD) aims to autonomously learn a diverse set of skills without relying on extrinsic rewards. One of the most common USD approaches is to maximize the Mutual Information (MI) between skill latent variables and states. However, MI-based methods tend to favor simple, static skills due to their invariance properties, limiting the discovery of dynamic, task-relevant behaviors. Distance-Maximizing Skill Discovery (DSD) promotes more dynamic skills by leveraging state-space distances, yet still fall short in encouraging comprehensive skill sets that engage all controllable factors or entities in the environment. In this work, we introduce SUSD, a novel framework that harnesses the compositional structure of environments by factorizing the state space into independent components (e.g., objects or controllable entities). SUSD allocates distinct skill variables to different factors, enabling more fine-grained control on the skill discovery process. A dynamic model also tracks learning across factors, adaptively steering the agent's focus toward underexplored factors. This structured approach not only promotes the discovery of richer and more diverse skills, but also yields a factorized skill representation that enables fine-grained and disentangled control over individual entities which facilitates efficient training of compositional downstream tasks via Hierarchical Reinforcement Learning (HRL). Our experimental results across three environments, with factors ranging from 1 to 10, demonstrate that our method can discover diverse and complex skills without supervision, significantly outperforming existing unsupervised skill discovery methods in factorized and complex environments. Code is publicly available at: https://github.com/hadi-hosseini/SUSD.
Mechanistic Interpretability of Large-Scale Counting in LLMs through a System-2 Strategy
Jan 06, 2026Large language models (LLMs), despite strong performance on complex mathematical problems, exhibit systematic limitations in counting tasks. This issue arises from architectural limits of transformers, where counting is performed across layers, leading to degraded precision for larger counting problems due to depth constraints. To address this limitation, we propose a simple test-time strategy inspired by System-2 cognitive processes that decomposes large counting tasks into smaller, independent sub-problems that the model can reliably solve. We evaluate this approach using observational and causal mediation analyses to understand the underlying mechanism of this System-2-like strategy. Our mechanistic analysis identifies key components: latent counts are computed and stored in the final item representations of each part, transferred to intermediate steps via dedicated attention heads, and aggregated in the final stage to produce the total count. Experimental results demonstrate that this strategy enables LLMs to surpass architectural limitations and achieve high accuracy on large-scale counting tasks. This work provides mechanistic insight into System-2 counting in LLMs and presents a generalizable approach for improving and understanding their reasoning behavior.
Infinity and Beyond: Compositional Alignment in VAR and Diffusion T2I Models
Dec 12, 2025



Achieving compositional alignment between textual descriptions and generated images - covering objects, attributes, and spatial relationships - remains a core challenge for modern text-to-image (T2I) models. Although diffusion-based architectures have been widely studied, the compositional behavior of emerging Visual Autoregressive (VAR) models is still largely unexamined. We benchmark six diverse T2I systems - SDXL, PixArt-$α$, Flux-Dev, Flux-Schnell, Infinity-2B, and Infinity-8B - across the full T2I-CompBench++ and GenEval suites, evaluating alignment in color and attribute binding, spatial relations, numeracy, and complex multi-object prompts. Across both benchmarks, Infinity-8B achieves the strongest overall compositional alignment, while Infinity-2B also matches or exceeds larger diffusion models in several categories, highlighting favorable efficiency-performance trade-offs. In contrast, SDXL and PixArt-$α$ show persistent weaknesses in attribute-sensitive and spatial tasks. These results provide the first systematic comparison of VAR and diffusion approaches to compositional alignment and establish unified baselines for the future development of the T2I model.
Limits and Gains of Test-Time Scaling in Vision-Language Reasoning
Dec 11, 2025Test-time scaling (TTS) has emerged as a powerful paradigm for improving the reasoning ability of Large Language Models (LLMs) by allocating additional computation at inference, yet its application to multimodal systems such as Vision-Language Models (VLMs) remains underexplored. In this work, we present a systematic empirical study of inference time reasoning methods applied across both open-source and closed-source VLMs on different benchmarks. Our results reveal that while closed-source models consistently benefit from structured reasoning and iterative Self-Refinement, open-source VLMs show inconsistent behavior: external verification provides the most reliable gains, whereas iterative refinement often degrades performance. We further find that the effectiveness of TTS is dataset-dependent, yielding clear improvements on multi-step reasoning tasks but offering only limited gains on perception-focused benchmarks. These findings demonstrate that TTS is not a universal solution and must be tailored to both model capabilities and task characteristics, motivating future work on adaptive TTS strategies and multimodal reward models.
Persian Musical Instruments Classification Using Polyphonic Data Augmentation
Nov 07, 2025Musical instrument classification is essential for music information retrieval (MIR) and generative music systems. However, research on non-Western traditions, particularly Persian music, remains limited. We address this gap by introducing a new dataset of isolated recordings covering seven traditional Persian instruments, two common but originally non-Persian instruments (i.e., violin, piano), and vocals. We propose a culturally informed data augmentation strategy that generates realistic polyphonic mixtures from monophonic samples. Using the MERT model (Music undERstanding with large-scale self-supervised Training) with a classification head, we evaluate our approach with out-of-distribution data which was obtained by manually labeling segments of traditional songs. On real-world polyphonic Persian music, the proposed method yielded the best ROC-AUC (0.795), highlighting complementary benefits of tonal and temporal coherence. These results demonstrate the effectiveness of culturally grounded augmentation for robust Persian instrument recognition and provide a foundation for culturally inclusive MIR and diverse music generation systems.
The Illusion of Procedural Reasoning: Measuring Long-Horizon FSM Execution in LLMs
Nov 05, 2025Large language models (LLMs) have achieved remarkable results on tasks framed as reasoning problems, yet their true ability to perform procedural reasoning, executing multi-step, rule-based computations remains unclear. Unlike algorithmic systems, which can deterministically execute long-horizon symbolic procedures, LLMs often degrade under extended reasoning chains, but there is no controlled, interpretable benchmark to isolate and measure this collapse. We introduce Finite-State Machine (FSM) Execution as a minimal, fully interpretable framework for evaluating the procedural reasoning capacity of LLMs. In our setup, the model is given an explicit FSM definition and must execute it step-by-step given input actions, maintaining state consistency over multiple turns. This task requires no world knowledge, only faithful application of deterministic transition rules, making it a direct probe of the model's internal procedural fidelity. We measure both Turn Accuracy and Task Accuracy to disentangle immediate computation from cumulative state maintenance. Empirical results reveal systematic degradation as task horizon or branching complexity increases. Models perform significantly worse when rule retrieval involves high branching factors than when memory span is long. Larger models show improved local accuracy but remain brittle under multi-step reasoning unless explicitly prompted to externalize intermediate steps. FSM-based evaluation offers a transparent, complexity-controlled probe for diagnosing this failure mode and guiding the design of inductive biases that enable genuine long-horizon procedural competence. By grounding reasoning in measurable execution fidelity rather than surface correctness, this work helps establish a rigorous experimental foundation for understanding and improving the algorithmic reliability of LLMs.
MEENA (PersianMMMU): Multimodal-Multilingual Educational Exams for N-level Assessment
Aug 24, 2025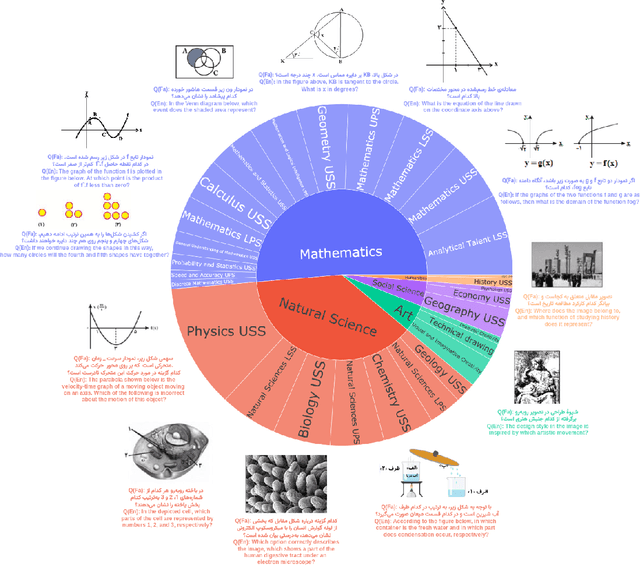

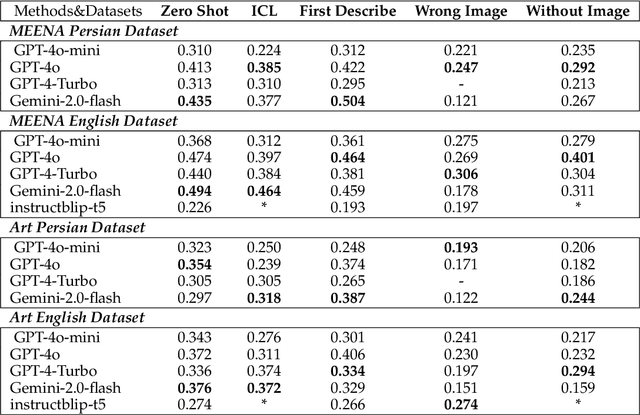
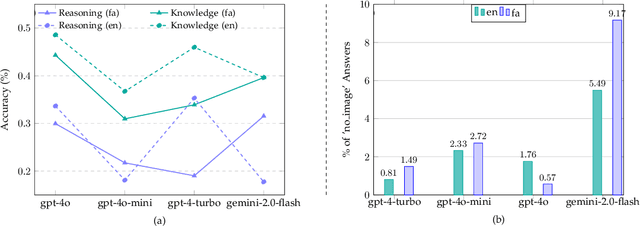
Recent advancements in large vision-language models (VLMs) have primarily focused on English, with limited attention given to other languages. To address this gap, we introduce MEENA (also known as PersianMMMU), the first dataset designed to evaluate Persian VLMs across scientific, reasoning, and human-level understanding tasks. Our dataset comprises approximately 7,500 Persian and 3,000 English questions, covering a wide range of topics such as reasoning, mathematics, physics, diagrams, charts, and Persian art and literature. Key features of MEENA include: (1) diverse subject coverage spanning various educational levels, from primary to upper secondary school, (2) rich metadata, including difficulty levels and descriptive answers, (3) original Persian data that preserves cultural nuances, (4) a bilingual structure to assess cross-linguistic performance, and (5) a series of diverse experiments assessing various capabilities, including overall performance, the model's ability to attend to images, and its tendency to generate hallucinations. We hope this benchmark contributes to enhancing VLM capabilities beyond English.
LLM-Agent-Controller: A Universal Multi-Agent Large Language Model System as a Control Engineer
May 26, 2025This study presents the LLM-Agent-Controller, a multi-agent large language model (LLM) system developed to address a wide range of problems in control engineering (Control Theory). The system integrates a central controller agent with multiple specialized auxiliary agents, responsible for tasks such as controller design, model representation, control analysis, time-domain response, and simulation. A supervisor oversees high-level decision-making and workflow coordination, enhancing the system's reliability and efficiency. The LLM-Agent-Controller incorporates advanced capabilities, including Retrieval-Augmented Generation (RAG), Chain-of-Thought reasoning, self-criticism and correction, efficient memory handling, and user-friendly natural language communication. It is designed to function without requiring users to have prior knowledge of Control Theory, enabling them to input problems in plain language and receive complete, real-time solutions. To evaluate the system, we propose new performance metrics assessing both individual agents and the system as a whole. We test five categories of Control Theory problems and benchmark performance across three advanced LLMs. Additionally, we conduct a comprehensive qualitative conversational analysis covering all key services. Results show that the LLM-Agent-Controller successfully solved 83% of general tasks, with individual agents achieving an average success rate of 87%. Performance improved with more advanced LLMs. This research demonstrates the potential of multi-agent LLM architectures to solve complex, domain-specific problems. By integrating specialized agents, supervisory control, and advanced reasoning, the LLM-Agent-Controller offers a scalable, robust, and accessible solution framework that can be extended to various technical domains.