 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGhost Tool Calls: Issue-Time Privacy for Speculative Agent Tools
Jun 01, 2026Tool-augmented language agents speculatively issue likely future tool calls to hide latency, but those calls leak inferred user intent to external services before the agent commits to the branch. Every external observer that received the call retains the disclosure after the agent abandons the branch. Timing is the issue, not authorization: no commit-time cleanup, read-only restriction, or access-control allow-list unsends what an observer already holds. We call these invocations ghost tool calls and propose Speculative Tool Privacy Contracts, a runtime abstraction that treats observation before commitment as a first-class effect, distinct from state mutation. We implement the contracts in a prototype runtime and evaluate twelve policies across three corpora. Speculative dispatch increases what an observer can infer about user intent; post-hoc filters, read-only restrictions, and access-control allow-lists leave that inference intact; only issue-time policies that change or suppress the speculative call's argument or destination projection before dispatch reduce it.
Atomix: Timely, Transactional Tool Use for Reliable Agentic Workflows
Feb 16, 2026LLM agents increasingly act on external systems, yet tool effects are immediate. Under failures, speculation, or contention, losing branches can leak unintended side effects with no safe rollback. We introduce Atomix, a runtime that provides progress-aware transactional semantics for agent tool calls. Atomix tags each call with an epoch, tracks per-resource frontiers, and commits only when progress predicates indicate safety; bufferable effects can be delayed, while externalized effects are tracked and compensated on abort. Across real workloads with fault injection, transactional retry improves task success, while frontier-gated commit strengthens isolation under speculation and contention.
Ask in Any Modality: A Comprehensive Survey on Multimodal Retrieval-Augmented Generation
Feb 12, 2025Large Language Models (LLMs) struggle with hallucinations and outdated knowledge due to their reliance on static training data. Retrieval-Augmented Generation (RAG) mitigates these issues by integrating external dynamic information enhancing factual and updated grounding. Recent advances in multimodal learning have led to the development of Multimodal RAG, incorporating multiple modalities such as text, images, audio, and video to enhance the generated outputs. However, cross-modal alignment and reasoning introduce unique challenges to Multimodal RAG, distinguishing it from traditional unimodal RAG. This survey offers a structured and comprehensive analysis of Multimodal RAG systems, covering datasets, metrics, benchmarks, evaluation, methodologies, and innovations in retrieval, fusion, augmentation, and generation. We precisely review training strategies, robustness enhancements, and loss functions, while also exploring the diverse Multimodal RAG scenarios. Furthermore, we discuss open challenges and future research directions to support advancements in this evolving field. This survey lays the foundation for developing more capable and reliable AI systems that effectively leverage multimodal dynamic external knowledge bases. Resources are available at https://github.com/llm-lab-org/Multimodal-RAG-Survey.
Predicting the Understandability of Computational Notebooks through Code Metrics Analysis
Jun 16, 2024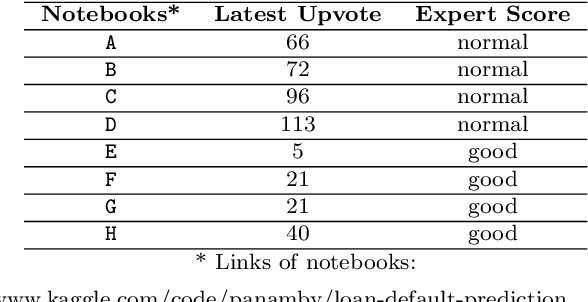
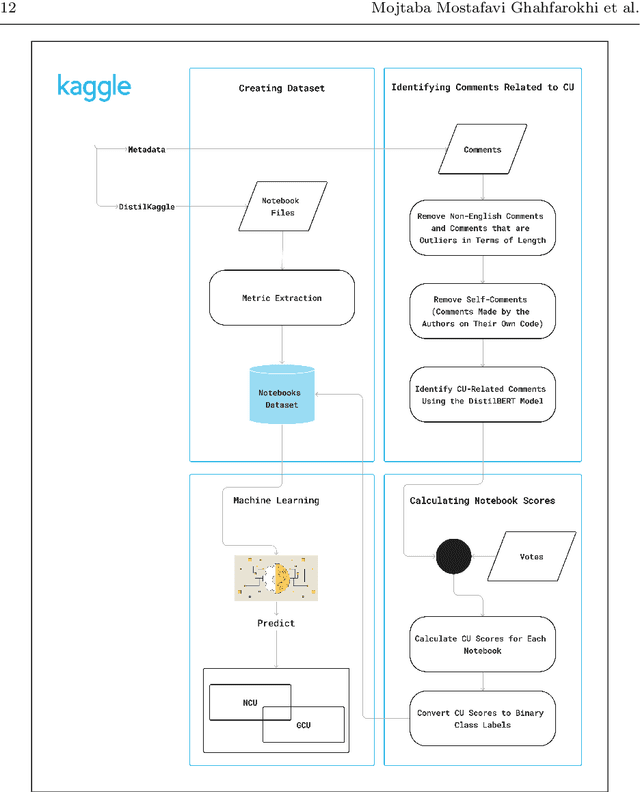
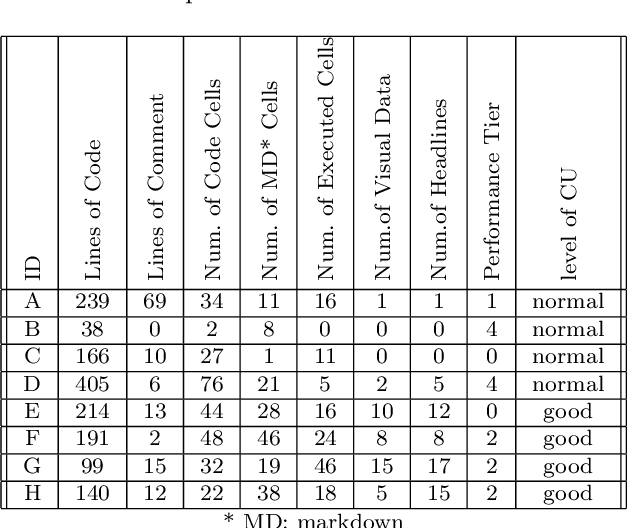
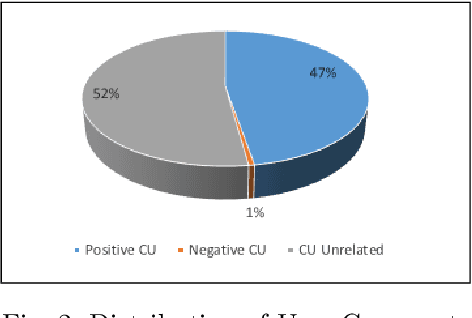
Computational notebooks have become the primary coding environment for data scientists. However, research on their code quality is still emerging, and the code shared is often of poor quality. Given the importance of maintenance and reusability, understanding the metrics that affect notebook code comprehensibility is crucial. Code understandability, a qualitative variable, is closely tied to user opinions. Traditional approaches to measuring it either use limited questionnaires to review a few code pieces or rely on metadata such as likes and votes in software repositories. Our approach enhances the measurement of Jupyter notebook understandability by leveraging user comments related to code understandability. As a case study, we used 542,051 Kaggle Jupyter notebooks from our previous research, named DistilKaggle. We employed a fine-tuned DistilBERT transformer to identify user comments associated with code understandability. We established a criterion called User Opinion Code Understandability (UOCU), which considers the number of relevant comments, upvotes on those comments, total notebook views, and total notebook upvotes. UOCU proved to be more effective than previous methods. Furthermore, we trained machine learning models to predict notebook code understandability based solely on their metrics. We collected 34 metrics for 132,723 final notebooks as features in our dataset, using UOCU as the label. Our predictive model, using the Random Forest classifier, achieved 89% accuracy in predicting the understandability levels of computational notebooks.
ClusterSeq: Enhancing Sequential Recommender Systems with Clustering based Meta-Learning
Jul 25, 2023In practical scenarios, the effectiveness of sequential recommendation systems is hindered by the user cold-start problem, which arises due to limited interactions for accurately determining user preferences. Previous studies have attempted to address this issue by combining meta-learning with user and item-side information. However, these approaches face inherent challenges in modeling user preference dynamics, particularly for "minor users" who exhibit distinct preferences compared to more common or "major users." To overcome these limitations, we present a novel approach called ClusterSeq, a Meta-Learning Clustering-Based Sequential Recommender System. ClusterSeq leverages dynamic information in the user sequence to enhance item prediction accuracy, even in the absence of side information. This model preserves the preferences of minor users without being overshadowed by major users, and it capitalizes on the collective knowledge of users within the same cluster. Extensive experiments conducted on various benchmark datasets validate the effectiveness of ClusterSeq. Empirical results consistently demonstrate that ClusterSeq outperforms several state-of-the-art meta-learning recommenders. Notably, compared to existing meta-learning methods, our proposed approach achieves a substantial improvement of 16-39% in Mean Reciprocal Rank (MRR).